变分贝叶斯VBEM 由浅入深
Posted 懵懂的菜鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了变分贝叶斯VBEM 由浅入深相关的知识,希望对你有一定的参考价值。
变分贝叶斯EM指的是变分贝叶斯期望最大化(VBEM, variational Bayes expectation maximization),这种算法基于变分推理,通过迭代寻找最小化KL(Kullback-Leibler)距离的边缘分布来近似联合分布,同时利用mean field 近似减小联合估计的复杂度。
变分贝叶斯EM方程最早是由BEAL M J. 在其论文《Variational Algorithms for Approximate Bayesian Inference》[D], London, UK: University College London, 2003里所提出的[1] 。其具体算法可表示为:在第i次VBEM迭代中,参数分布的更新方程式可表示为VBE步和VBM步。
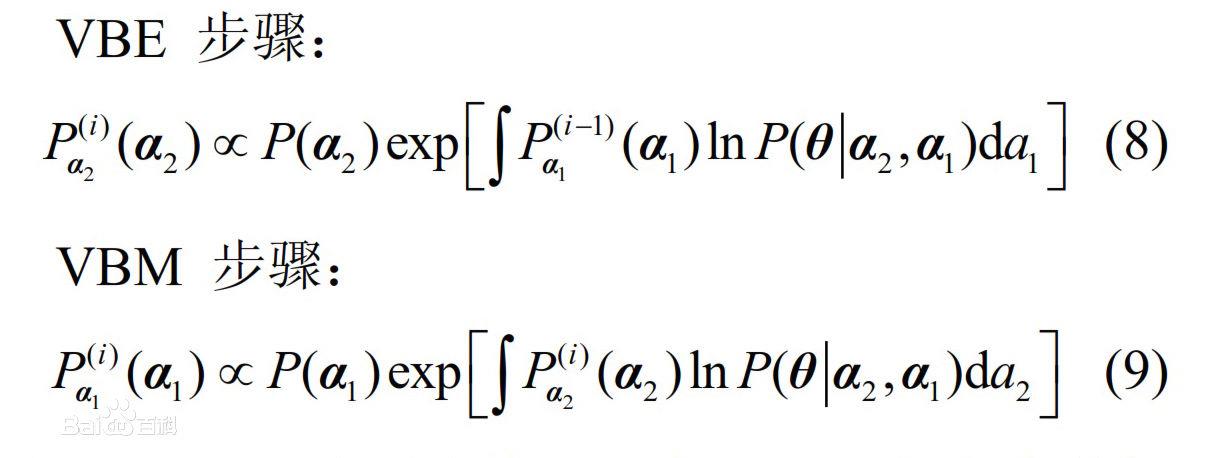
在VBEM算法中,VBE步骤和VBM步骤均是关于后验分布求均值的,因此隐参数和未知参数之间不再存在区别。
一、《VBEM算法由浅入深》
1,EM算法讲得比较直观明了的资料是Andrew NG的machine learning课程的讲稿。CS 229: Machine Learning (Course handouts),第八章就是专门讲EM算法
2,EM的一些code实现。比如MachineLearning-C---code/main.cpp at master · pennyliang/MachineLearning-C---code · GitHub。
3,熟悉完EM算法之后,可以去看变分推断了,关于变分推断的方法,D.Blei一直在推。笔记在此https://www.cs.princeton.edu/courses/archive/fall11/cos597C/lectures/variational-inference-i.pdf。 文章在此https://arxiv.org/abs/1601.00670。笔记是对文章的总结。
4,结合了EM和variational inference的变分EM了,这个可以看香港大学的一份PPT,讲得是使用变分EM推导LDA的过程,很详。http://www.cse.ust.hk/~lzhang/teach/6931a/slides/lda-zhou.pdf
3,熟悉完EM算法之后,可以去看变分推断了,关于变分推断的方法,D.Blei一直在推。笔记在此https://www.cs.princeton.edu/courses/archive/fall11/cos597C/lectures/variational-inference-i.pdf。 文章在此https://arxiv.org/abs/1601.00670。笔记是对文章的总结。
4,结合了EM和variational inference的变分EM了,这个可以看香港大学的一份PPT,讲得是使用变分EM推导LDA的过程,很详。http://www.cse.ust.hk/~lzhang/teach/6931a/slides/lda-zhou.pdf
二、采样和变分
1、Gibbs采样和变分
Gibbs采样:使用邻居结点(相同文档的词)的主题采样值
变分:采用相邻结点的期望。n
这使得变分往往比采样算法更高效:用一次期望计算代替了大量的采样。直观上,均值的信息是高密(dense)的,而采样值的信息是稀疏(sparse)的。
2、变分概述
变分既能够推断隐变量,也能推断未知参数,是非常有力的参数学习工具。其难点在于公式演算略复杂,和采样相对:一个容易计算但速度慢,一个不容易计算但运行效率高。
平均场方法的变分推导,对离散和连续的隐变量都适用。在平均场方法的框架下,变分推导一次更新一个分布,其本质为坐标上升。可以使用模式搜索(pattern search)、基于参数的扩展(parameter expansion)等方案加速
有时假定所有变量都独立不符合实际,可使用结构化平均场(structured mean field),将变量分成若干组,每组之间独立
变分除了能够和贝叶斯理论相配合得到VB(变分贝叶斯),还能进一步与EM算法结合,得到VBEM,用于带隐变量和未知参数的推断
以上是关于变分贝叶斯VBEM 由浅入深的主要内容,如果未能解决你的问题,请参考以下文章