2.2 logistic回归损失函数(非常重要,深入理解)
Posted yangzsnews
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2.2 logistic回归损失函数(非常重要,深入理解)相关的知识,希望对你有一定的参考价值。
- 上一节当中,为了能够训练logistic回归模型的参数w和b,需要定义一个成本函数
- 使用logistic回归训练的成本函数
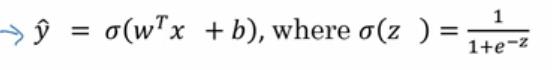
- 为了让模型通过学习来调整参数,要给出一个含有m和训练样本的训练集
- 很自然的,希望通过训练集找到参数w和b,来得到自己得输出
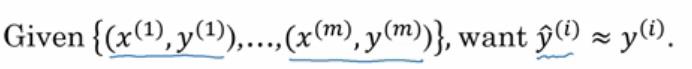
- 对训练集当中的值进行预测,将他写成y^(I)我们希望他会接近于训练集当中的y^(i)的数值
- 使用logistic回归训练的成本函数
- 现在来看一下损失函数或者叫做误差函数
- 他们可以用来衡量算法的运行情况
- 可以定义损失函数为y^和y的差,或者他们差的平方的一半,结果表明你可能这样做,但是实际当中,大家都不会这么做,因为当你学习这些参数的时候,你会发现之后讨论的优化问题,会变成非凸的,最后会得到很多的局部最优解,梯度下降算法可能找不到最优的全局最优值,
- 直观理解就是我们定义这个损失函数L,来衡量你的预测输出值y^和y的实际值有多接近,误差平方看起来是一个合理的选择,但是如果用这个的话,梯度下降法就不会很好用,
- 在logistic回归中,我们会定义一个不同的损失函数,它起着于误差平方相似的作用,这会给我们一个凸的优化问题,他很容易去做优化,
- 在logistic回归中,我们用的损失函数将会是下面这样的,(非常重要!)
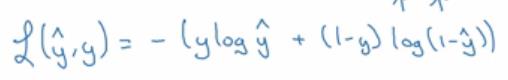
- 直观的看一下为什么这个函数会起到作用,
- 记得如果我们使用误差平方越小越好
- 对于这个logistic回归的损失函数,同样的,我们也想让它尽可能的小,
- 为了更好的理解它能起到好的作用,来看两个例子
- 当y=1的时候,就是第一项L带个负号,
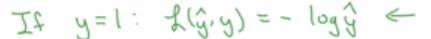
- 这就是说,当y=1的时候,你想让-log(y^)尽可能小(代表着误差尽可能的小),那么就需要y^足够大,但是因为y^是sigmoid函数得出来的,永远不会比1大,也就是说,如果y=1的时候,你想让y^,尽可能的大,但是它永远不会大于1,所以你要让y^接近1(从sigmoid函数的图像上看一下,采取什么样的措施才能够让y^接近于1呢?就是上一节分析的那样),
- 当y=0的时候,
- 在学习过程中,想让损失函数小一些,也就意味着你想要log(1-y^)够大,通过这一系列的推导,发现,损失函数让y^尽可能的小,再次,因为y^只能介于0和1之间,所以就是说,当y=0的时候,损失函数会让这些让y^尽可能的接近0,有很多函数都能够达到上面的效果,
- 当y=1的时候,就是第一项L带个负号,
- 如果y=1,我们尽可能的让y^很大,如果y=0,尽可能的让y^足够小,
- 给出解释为什么在logistic回归中,要使用这个形式的损失函数。
- 最后说一下
- 在单个训练样本中定义的,它衡量了在单个训练样本上的表现(个人理解也就是一个训练集中的每个训练样本),
- 下面定义一个成本函数
- 它衡量的是在全体训练样本上的表现,这个成本函数J,根据之前得到的两个参数w和b,J(w,b)等于所有的训练样本的损失函数的和的平均数
- y^是用一组特定的参数w和b,通过logistic回归算法得出的预测输出值,
- 损失精度函数适用于单个训练样本,而成本函数,基于参数的总成本,所以在训练logistic回归模型的是时候,我们需要找到合适的参数w和b,让下面这里的成本函数尽可能的小,
- 这一节我们看到了logistic回归算法的过程,以及训练样本的损失函数,还有和参数相关的总体成本函数,结果表明,logistic回归可以被看作是一个非常小的神经网络,
- 下一节讲解,神经网络能够做什么,看看如何将logistic回归看做一个非常小得神经网络,
以上是关于2.2 logistic回归损失函数(非常重要,深入理解)的主要内容,如果未能解决你的问题,请参考以下文章