网络编程
Posted c++,c随笔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络编程相关的知识,希望对你有一定的参考价值。
字节序的概念
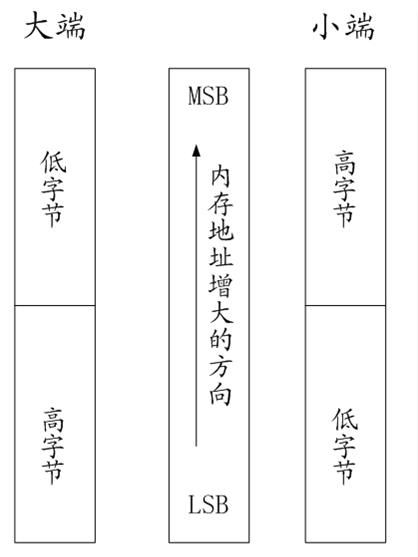
字节序是指多字节数据的存储顺序,在设计计算机系统的时候,有两种处理内存中数据的方法:大端格式、小端格式。
小端格式(Little-Endian):将低位字节数据存储在低地址。
大端格式(Big-Endian):将高位字节数据存储在低地址。
例如:
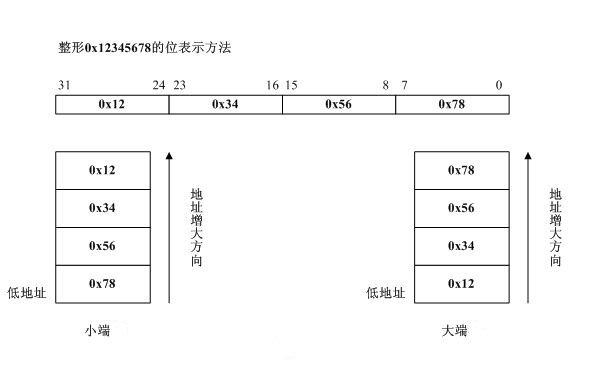
注:int类型是4字节,char类型是1字节,
因此 int a = 0X1234 ;(即 int a = 0X00001234)
char *p = &a; (由于char类型是1字节,因此它会去取int类型的低位)
去判断*p是 00, 还是34,即可判断是大端还是小端
网络字节是大端,网络编程将主机字节数据转化为网络字节数据。
套接字概述
套接字是一种通信机制(通信的两方的一种约定),凭借这种机制,不同主机之间的进程可以进行通信。我们可以用套接字中的相关函数来完成通信过程。
套接字的特性有三个属性确定,它们是:域(domain),类型(type),和协议(protocol)。
套接字的域
域指定套接字通信中使用的网络介质。最常见的套接字域是 AF_INET(IPv4)或者AF_INET6(IPV6)。
套接字类型
流套接字(SOCK_STREAM):
流套接字用于提供面向连接、可靠的数据传输服务。流套接字之所以能够实现可靠的数据服务,原因在于其使用了传输控制协议,即TCP。
数据报套接字(SOCK_DGRAM):
数据报套接字提供了一种无连接的服务。该服务并不能保证数据传输的可靠性,数据有可能在传输过程中丢失或出现数据重复,且无法保证顺序地接收到数据。数据报套接字使用UDP(User Datagram Protocol)协议进行数据的传输。由于数据报套接字不能保证数据传输的可靠性,对于有可能出现的数据丢失情况,需要在程序中做相应的处理。
原始套接字(SOCK_RAW):
原始套接字与标准套接字(标准套接字指的是前面介绍的流套接字和数据报套接字)的区别在于:原始套接字可以读写内核没有处理的IP数据包,而流套接字只能读取TCP协议的数据,数据报套接字只能读取UDP协议的数据。因此,如果要访问其他协议发送数据必须使用原始套接字。
套接字协议(协议类别)
只要底层的传输机制允许不止一个协议来提供要求的套接字类型,我们就可以为套接字选择一个特定的协议。通常使用默认即可(也就是最后一个参数填“0”)。
需要头文件:#include <sys/socket.h>
int socket(int family,int type,int protocol);
功能:创建一个用于网络通信的 socket 套接字(描述符)
参数:
family:协议族(AF_UNIX、AF_INET、AF_INET6、PF_PACKET等)。最常见的套接字域是 AF_UNIX 和 AF_INET,前者用于通过 Unix 和 Linux 文件系统实现的本地套接字,后者用于 Unix 网络套接字。AF_INET 套接字可以用于通过包括因特网在内的 TCP/IP 网络进行通信的程序。
type:套接字类型(SOCK_STREAM、SOCK_DGRAM、SOCK_RAW等)。
protocol:协议类别(0、IPPROTO_TCP、IPPROTO_UDP等),设为 0 表示使用默认协议。
返回值:成功:套接字 失败(<0)
套接字地址: 每个套接字(端点)都有其自己的地址格式,对于 AF_UNIX 套接字来说,它的地址由结构 sockaddr_un 来描述,该结构体定义在头文件 sys/un.h 中
以上是关于网络编程的主要内容,如果未能解决你的问题,请参考以下文章