集合框架
Posted 菜鸡蔡文姬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集合框架相关的知识,希望对你有一定的参考价值。
一、集合框架图
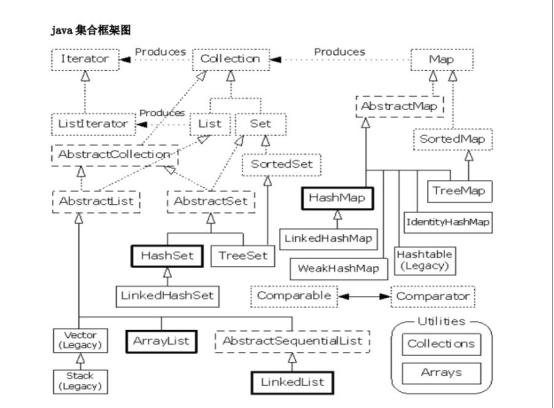
标准框架图:
精简集合框架图:
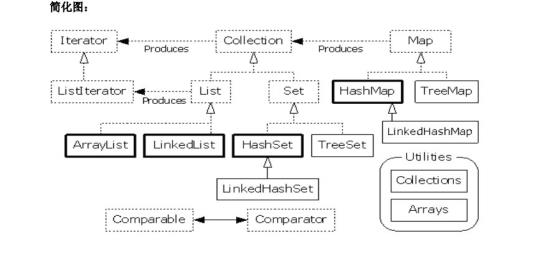
从以上图可以看出Java集合类主要有以下几种:
1.List结构(实现了list接口)的集合类(ArrayList、LinkedList、Vector、Stack),一般称为列表
2.Map结构(实现了Map接口)的集合类(HashMap、HashTable),一般称为映射
3.Set结构(实现了Set接口)的集合类(HashSet、TreeSet),一般称为集
4.Queue(实现了Queue接口)结构的集合,一般称为列
注意:所有的集合add方法存储的都是对象的引用,也就是说存入的是基本数据类型(int、float、double、char、String)的变量a时候,一旦存入了,我们改变变量a,集合中的值还是不变。而我们存储的是其他类对象A(包括集合对象)的时候,我们对A发生改变,集合中的值会跟着变。
二、部分集合类详解
1.ArrayList类
①.创建 ArrayList arrayList=new ArrayList();
②.增加 arrayList.add(Object);//尾部添加,并使长度加一
arrayList.add(Index, Object);//指定位置添加,将原来位置及其后面的后移。
arrayList.addAll(Collection); //复制集合Collection中所有对象到arrayList尾部
arrayList.addAll(Index, Collection);////复制集合Collection中所有对象到arrayList指定位置后
③.删除 arrayList.remove(Index)//根据下标(0开始)删除
arrayList.remove(Object);//删除第一个跟Object相等的对象(从头到尾数)
arrayList.removeAll(Collection); //删除所有跟集合Collection包含对象相等的对象
arrayList.removeAll(arrayList); //清空arrayList。
④.取出 Object object = arrayList.get(Index);
⑤.遍历 for(int i=0;i<arrayList.size();i++){
Object object = arrayList.get(i);
}
或者直接System.out.println(arrayList);
注意:
i.ArrayList中可以添加已存在的对象并使集合长度+1。
ii.ArrayList中add方法比较特殊,不管add的对象多大,就算add一个长度100的集合,也只会使ArrayList长度增加1,因为ArrayList会把这个集合仅仅当作一个对象来管理。
Iii.arrayList.addAll(Collection); 是将原集合中的所有值复制存储到arraylist中去,原集合中每一个变量都会使arraylist长度加一,而且我们以后修改这个Collection并不会影响ArrayList。
2.LinkedList类
①.创建 LinkedList linkedList=new LinkedList();
②.增加 (除与ArrayList相同的外)
linkedList.addFirst(Object);
linkedList.addLast(Object);
③.删除 (除与ArrayList相同的外)删除头、删除尾.
④.取出 (除与ArrayList相同的外)取头、取尾
⑤.遍历 (与ArrayList相同)
注意:linkedList同样可以添加已存在的对象并使集合长度+1,addFirst和addLast性质同add。
区别:ArrayList和LinkedList在性能上各有优缺点,都有各自所适用的地方,总的说来可以描述如下:
i.对ArrayList和LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对ArrayList而言,主要是在内部数组中增加一项,指向所添加的元素,偶尔可能会导致对数组重新进行分配;而对LinkedList而言,这个开销是统一的,分配一个内部Entry对象。
ii.在ArrayList的中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在LinkedList的中间插入或删除一个元素的开销是固定的。
iii.LinkedList不支持高效的随机元素访问。
iv.ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
可以这样说:当操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能;当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
3.Vector类
①.创建 Vector vector=new Vector();
②.增加 (同ArrayList)
vector.addElement(Object)用法与add一样
vector.insertElementAt(obj, index)用法与add(Index, Object)一样
③.删除 (同ArrayList) vector.removeElement(Object)用法与remove一样
④.取出 (同ArrayList) vector.elementAt(Index)与get(Index)的用法一样
⑤.遍历 (同ArrayList)
//使用枚举类(Enumeration)的方法取得向量对象的每个元素。
Enumeration elements = vector.elements(); while(elements.hasMoreElements()){ System.out.print(elements.nextElement()+" "); }
⑥.设置 vector.setSize(int); //重新设置vector的大小,多余的元素被抛弃
⑦.判断 vector.isEmpty();//判断vector是否为空
注意:Vector同样可以添加已存在的对象并使集合长度+1,Vector的效果与Arraylist差别不大。
ArrayList和Vector都是java的集合类,都可以用来存放java对象,这是他们的相同点,但是他们也有区别:
i.同步性,Vector是同步的。这个类中的一些方法保证了Vector中的对象是线程安全的,而ArrayList是异步的,因此ArrayList中的对象并不是线程安全的。因为同步的要求会影响执行的效率,所以如果你不需要线程安全的集合那么使用ArrayList较好,这样可以避免由于同步带来的不必要的性能开销,从而提高效率。
Ii.数据增长,从内部实现机制来讲ArrayList和Vector都是使用数组Array来控制集合中的对象,当你向这两种数据类型中增加元素的时候,如果元素的数目超过了内部数组目前的长度它们需要扩展内部数组的长度,Vector缺省情况下自动增长原来一倍的数组长度,ArrayList是原来的50%,所以最后你获得的这个集合所占的空间总是比你实际需要的要大,所以如果你要在集合中保存大量的数据那么使用Vector有一些优势,因为你可以通过设置集合的初始化大小来避免不必要的资源开销。
4.Stack类(继承自Vector)
Stack是Vector的子类,Vector能用的方法,在Stack中也同样能用。
除去相同的部分,Stack还有以下特有方法:
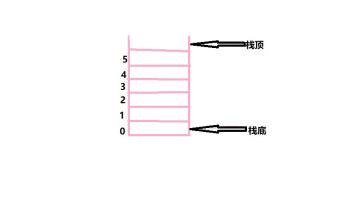
①创建Stack stack = new Stack();
②入栈stack.push(Object);等于stack.add(Object);
③出栈stack.pop()等于LinkedList的removeLast();
④取得stack.peek()等于LinkedList的getLase();
⑤清空栈
while(!stack.isEmpty()){
stack.pop();
}
注意:功能上来说,感觉HashMap其实就是LinkedList的精简版,同样可以加入已存在的对象。
5.HashMap
HashMap是Map结构,一个键值对应一个对象,即存放的都是<键值,对象>这样的键值对,与list结构的集合不同。
①创建HashMap hashMap=new HashMap();
②放入hashMap.put(Key, Object); //放入的时候需提供键和值,键和值均可以为null,一个键对应一个值,若后面存入键相同的另一个对象,则会覆盖前者。
③判断是否存在 hashMap.containsKey(Key)和hashMap.containsValue(Object)
④取出 Object object = hashMap.get(Key);//只能根据键的值来取
⑤删除 hashMap.remove(Key);//也只能通过键值来删除
⑥遍历
Iterator iterator=hashMap.keySet().iterator(); while(iterator.hasNext()){ Object key=iterator.next(); Object object = hashMap.get(key); }
//取出需要使用迭代器iterator,而且取出是按照一种特殊的的顺序。
6.Hashtable
HashTable用法基本与HashMap一样。
注意:HashMap和HashTable都是java的集合类,都可以用来存放java对象,这是他们的相同点,但是他们也有区别:
i.历史原因,Hashtable基于陈旧的Dictionary类,HashMap是java1.2引进的Map接口的一个实现。
ii.同步性,HashTable是同步的,这个类的一些方法保证了HashTable中的对象是线程安全的,而HashMap则是异步的,因此HashMap中的对象并不是线程安全的。因为同步的要求会影响执行的效率,所以如果你不需要线程安全的集合那么使用HashMap较好,这样可以避免由于同步带来的不必要的性能开销,从而提高效率。
iii.值,HashMap是可以让你将空值作为一个表的条目的key或Value,HashTable不允许存放null(会报空指针异常).
7.list集合类与map集合类小结:
①如果需要线程安全,使用Vector,HashTable
②如果不要求线程安全,使用ArrayList、LinkedList、HashMap
③如果要求键值对,则使用HashMap、HashTable
④如果数据量很大,又要线程安全,则考虑使用Vector
8.HashSet
Set类的集合特点就是插入已存在的对象相当于没有插入。因为是一个集,而不是一个列表。插入的时候会检测插入的对象的引用是否已存在,如果已存在就不再插入。所以,相同数值的数字、相同数据的字符、内容完全一样的两个类对象,都是无法再次插入的。
①创建HashSet hashSet=new HashSet();
②存入hashSet.add(Object);
③取出 无法取出指定单个
④判断 hashSet.isEmpty();
⑤遍历
Iterator iterator = hashSet.iterator(); while(iterator.hasNext()){ Object object = iterator.next(); }
以上是关于集合框架的主要内容,如果未能解决你的问题,请参考以下文章
text 来自Codyhouse框架的Browserlist片段源代码