)
Posted Elon.Yang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了)相关的知识,希望对你有一定的参考价值。
原文链接:http://coding-geek.com/how-databases-work/#Buffer-Replacement_strategies
先翻译高速缓存章节,后续有时间再翻译其它章节。翻译内容在原文的目录:
一、数据管理器
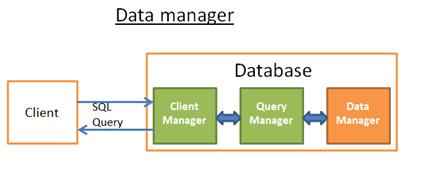
数据查询器执行查询操作,从数据表中获取数据,它向Data Manger发送请求,获取数据。其中存在2个问题:
- 关系型数据使用事物模型,当数据库在执行修改操作时,不能执行查询操作。避免查询出脏数据。
- 数据提取是最慢的数据库操作,因为数据要从磁盘上读取。因此,数据库必须要有一个非常强大的数据缓存系统。
本章,我们将看一下关系数据是如何解决这两个问题的。我们不会探讨数据库是如何从磁盘加载数据的,这个不是本文的重点(受篇幅所限,不展开分析)。
二、高速缓存器
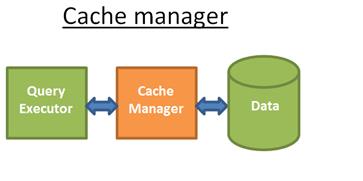
正如我之前所言,数据库的性能瓶颈是I/O。为了提升性能,现代数据库都使用了高速缓存。
数据查询器从Cache Manger中获取数据,而不是直接从磁盘文件中读取数据。Cache Manger管理着一片内存区域,叫缓存池。 直接从内存获取数据,使得访问数据库的性能突飞猛进。但是,很难评估使用高速缓存的重要性有多大,这取决于你要做什么样的数据库操作。
- 顺序访问 VS 随机访问。
- 读操作 VS 写操作。
以及数据库使用的是什么样的磁盘
- 7.2k/10k/15k rpm HDD
- SSD
- RAID 1/5/…
但是,我敢说使用内存高速缓存比不适用缓存直接从磁盘读数据快100到10万倍。
这也导致另外一个问题(所有的数据库都有这个问题……), 高速缓存器需要在查询器访问数据之前预取数据,否则查询器需要挂起,等待高速缓存器把数据从磁盘加载到内存先。
三、缓存数据预取
问题的核心就在“数据预取”。数据查询器清楚需要哪些数据,因为它了解每一次查询操作的具体要求,也清楚数据库表的存储结构。数据预取的基本逻辑是这样的:
- 数据查询器在获取第一批数据时通知Cache Manger提前加载第二批数据到缓存中。
- 数据查询器在获取第二批数据时通知Cache Manger提前加载第三批数据,而第一批数据可以从缓存中移除了。
- …….
Cache Manger存储所有的数据在缓存池中。为了确定缓存池中数据是否正在被使用,Cache Manger需要维护一些关于这些数据的额外信息(被称之为锁的东西)。
但有时,数据查询器不清楚下一步需要什么数据,或者数据库没有提供指定预取哪些数据的功能。取而代之,数据库提供的是随机预取功能(例如,查询了数据1,2,3后,它因为你可能还需要7,8,9,提前把7,8,9加载到缓存中)或者顺序缓存功能(执行一次查询后,将磁盘上查询数据临近的其它数据也预取到缓存中)。
为了评估Cache Manger预期机制工作的效果,现代数据库系统提供一个指标度量:缓存命中率。缓存命中率描述查询器从缓存中拿到数据的几率(在不需要读磁盘文件的情况下)。
说明:糟糕的缓存命中率,并不总是意味Cache工作得不好。更多信息可参考Oracle说明文档。
但是,高速缓存内存大小是受限的,缓存内容需要不断吐故纳新。缓存数据的加载和移除都需要消耗磁盘I/O和网络I/O资源。如果某个查询操作要经常执行,缓存数据频繁的加载和移除是非常低效的。为了解决这个问题,现代数据库都使用了一些缓存置换策略。
四、缓存置换策略
大多数现代数据库缓存置换策略都使用LRU算法,至少SQL Server, mysql, Oracle and DB2是这样的。
1. LRU
LRU的意思是非最近当前使用。这个算法的是基于这样一种假设:最近使用过的数据,在将来被再次使用的概率很大,需要驻留在缓存中;反之,非最近当前使用的数据可移除。
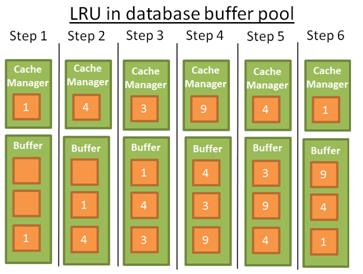
为了方便理解,我们假设缓存中的数据未被加锁(因此可被移除)。举个例子说明它的工作原理,这个简单的示例中缓存池能容纳3个数据。
- Cache Manger使用数据1后,将1放入缓存。
- Cache Manger使用数据4后,将4放入缓存。
- Cache Manger使用数据3后,将3放入缓存。
- Cache Manger使用数据9后,将9放入缓存。由于缓存已满,需要先移除一条数据;移除哪一条?
根据LRU原则,1是最远当前使用的数据,移除1后加入9。 - Cache Manger使用数据4后放入缓存,4变成了最近被使用过的数据。调整顺序。
- Cache Manger使用数据1后放入缓存,1变成了最近被使用过的数据。3被移除。
- ……
算法OK,但有一些限制,如果读取的是一张大表呢? 换言之,读取的表数据太大,超过了缓存空间的大小。使用该算法将清除缓存之前所有的数据,即使新加载上来的这张大表数据只会使用一次就不再使用。
2. 算法改进
为解决这个问题,一些数据库管理系统加了一些特殊规则。例如:Oracle规则说明:
对于超级大表的读取,直接从磁盘文件中读取数据,避免是用高速缓存。对于中型表,可以从磁盘文件直接读也可以用缓存;如果使用缓存应该把读取的数据放到LRU列表末尾(这样,新加入缓存数据时将先把该表的数据移除)。
LRU算法有高级版本,叫LRU-K。例如SQL Server使用的LRU-K, K=2。K代表的是考虑最近时间段,数据访问的次数。
前面的例子是LRU-K算法最简单的例子,只考虑一次访问,K = 1。LRU-K的原理如下:
- 记录数据的最近访问次数(最多记录K次)。
- 根据数据访问次数,设置一个权值。最近访问次数越多的权值越大。
- 当一批新的数据加载到缓存中时,权值大的数据不会被移除,即使该数据是很早就加载到缓存中的。
- 如果数据长时间未被再使用,权值会逐渐降低。
权值的计算是很耗资源的,这也是为什么 SQL Server使用K=2的原因。这种设置方式,投入产出比较高。
想更深入的了解LRU算法,可以参考一下算法文档(文档google)。
3. 其它算法
还有一些其它算法策略,用于管理高速缓存器。
- 2Q(类似LRU-K算法)
- CLOCK(类似LRU-K算法)
- MRU(用得比较多的算法,逻辑类似LRU,用的是另一套规则)
- LRFU(最近、最频繁使用算法)
- ……
一些数据库允许你使用除默认算法外的其它算法。多种方式可选。
五、写缓存器
前讨论的最多的是读缓存器,它在数据使用之前将其提前加载到内存。数据库中还存在一种写缓存器,它将多次操作修改的数据存储累计起来,一次写到磁盘文件。降低对磁盘IO的频繁访问(数据库瓶颈在I/O)。
谨记,高速缓存中存储的是分页数据而不是人们直观印象中的行数据。如果缓存中的某一页数据被修改了,还没有保存到磁盘上,这页被称为“脏页”。有多种策略算法能评估脏页数据写到磁盘上的最佳时机,而这也和事物强相关(事务是下一章节将展开的内容)。
以上是关于)的主要内容,如果未能解决你的问题,请参考以下文章
Java AWT 图形界面编程LayoutManager 布局管理器 ① ( 布局管理器引入 | 布局管理器提高程序的适配性 | LayoutManager 布局管理器类 )
Java AWT 图形界面编程LayoutManager 布局管理器 ① ( 布局管理器引入 | 布局管理器提高程序的适配性 | LayoutManager 布局管理器类 )