Java Nio 十一Java NIO:非堵塞服务器
Posted 大军001
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java Nio 十一Java NIO:非堵塞服务器相关的知识,希望对你有一定的参考价值。
最后更新时间:2015-10-23
甚至如果你理解JAVA NIO的非堵塞特点的工作方式(Selector,Channel,Buffer等等),而设计一个非堵塞服务器也是难得。相对堵塞IO来说,非堵塞IO包含几个挑战。这个非堵塞服务器教程将会讨论非堵塞服务器的主要挑战,并且对于他们描述一些潜在的解决方案。
关于设计一个非堵塞服务器发现一些好的信息是难得。因此在这个教程中提供的解决方案是基于我自己的工作经验和想法。如果你有一些另类的或者更好的想法,我将会很高兴的听到关于这些想法。你可以写一个评论在这个文章下方或者给我发邮件,或者在twitter上找我。
在这篇教程中描述的思想你围绕着Java NIO设计的。然而,我相信这些思想也可以在其他的语言中重用,只要他们也有一些像selector这种概念的东西。就我知道的而言,一些概念是在操作系统底层被提供的,以至于这里有一些好的机会,你也可以在其他的语言中使用这些。
非堵塞服务器 - github资源库
我已经创建了一些简单的这些思想的概念验证呈现在这篇教程中,并且为了让你们可以看到我把他们放到了github资源库上了。这里是GitHub资源库地址:
https://github.com/jjenkov/java-nio-server
非堵塞IO管道
一个非堵塞IO管道是一系列处理非堵塞IO的组件。这个在非堵塞模式下既包括读IO也包括写IO。这里有一个简化的非堵塞IO管道的图示:
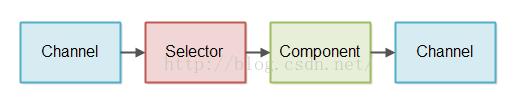
一个组件使用一个Selector去检查当一个Channel有数据去读的时候。然后这个组件读取进来的这个数据并且建立在输入的基础上生成一些输出。这个输出再一次被写到一个Channel中。
一个非堵塞IO的管道不需要既要读取数据又要写数据。一些管道可能只是读数据,一些可能只是写数据。
上面的图只是显示了一个单独的组件。一个非堵塞IO管道可能会不只是有一个组件去处理进来的数据。一个非堵塞IO管道的长度依赖于这个管道需要做什么。
一个非堵塞IO的管道可能也会同时从多个Channel中读取数据。例如,从多个SocketChannel中读取数据。
上面图示的控制流也是简化的。它是来自于Channel通过Selector开始读数据的组件。它不是把数据推入到Selector的Channel,也不是从Channel进入组件,尽管那个是上面图示建议的东西。
非堵塞IO VS 堵塞IO管道
一个非堵塞IO和一个堵塞IO管道之间最大的不同就是数据怎么样从潜在的Channel(socket或者file)中去读。
IO管道典型的是从一些流中读取数据(从socket或者file中),并且把数据分成连贯的信息。这个对于为了分析使用一个分词器去打破一个数据流成为符号是类似的。代替的,你打破一个数据流进入更大的信息。我将会为了一个Message Reader去调用组件打破这个流进入信息中。这里有一个图示,一个Message Reader打破一个流进入信息:

一个堵塞IO的管道可以使用一个像InputStream接口,这里一次可以只有一个字节从潜在的Channel中去读,并且在像InputStream接口的这个地方会堵塞到直到有数据可以读取了。这个结果在一个堵塞的Message Reader中实现。
对于一个流使用一个堵塞IO接口将会简化很多一个Message Reader的实现。一个堵塞的Message Reader不用不得不处理没有数据从流中读取的这种场景,或者只是一部分信息从流中读取的场景,并且信息解析需要在后面重新开始。
同样的,一个堵塞的Message Writer(一个组件写数据进入流中)不用不得不处理只是一部分信息被写的场景,以及正在写的信息不得不在后面进行恢复。
堵塞IO管道的缺陷
当一个堵塞的Message Reader很容易被实现的时候,对于每个需要去分离信息的流需要一个分开的线程是一个不幸运的缺陷。这个是必要的原因是每一个流的IO接口都会堵塞到有数据可以读取。那就意味着一个单独的线程不能尝试着从一个流中读数据,并且如果这里没有数据,就从另外一个流中读数据。只要一个线程尝试着从一个流中读数据,这个线程就会堵塞到确实有些数据可以读取了。
如果这个IO管道是一个不得不处理很多并发连接的服务器的一部分,那么这个服务器对于每一个活跃的进来的连接都要需要一个线程。这可能不是一个问题,如果服务器在任何时候有上百个并发的连接。但是,如果这个服务器有成千上万个并发的连接,这种类型的设计就不会很好的衡量。每一个线程对于他们的堆栈将会花费在320K(32位 JVM)和1024K(64位JVM)内存之间。以至于,1000000线程将会花费1T的内存。并且那个是在服务器为了处理进来的消息已经使用的任何内存之前(例如,在消息处理期间对象使用的内存分配)。
为了使得线程的数量下降,许多服务器使用这样的设计,这个服务器保持一个线程池(例如100)来每次一个的从进来的连接到读取消息。进来的连接被保持在一个队列里面,并且这些线程按顺序处理进入到队列里面的每一个连接的消息。这个设计的图示如下:
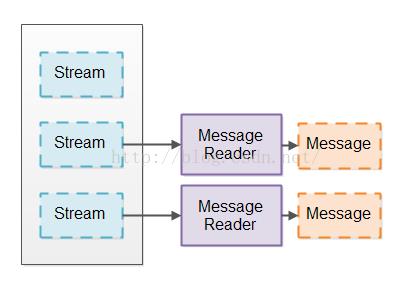
然而,这个设计需要进来的这些连接经常合情合理的发送数据。如果这个进来的连接很长一段时间可能处于不活动状态,那么会有很多不活动的连接可能事实上会堵塞线程池中所有的线程。这就意味着服务器响应会变得很慢或者甚至没有响应。
一些服务器试着通过在线程池中有一些灵活数量的线程来缓解这个问题。例如,如果这个线程池耗尽了这些线程,这个线程池就会开启更多的线程去处理这个负载。这个解决方案意味着将会带来很多数量的慢的连接去使得服务器不响应的。但是,请记住,这里仍然有一个上限去控制你可以有多少个线程。以至于,伴随着1000000个慢的连接将会不是很好的衡量。
基础的非堵塞IO管道设计
一个非堵塞IO管道可以使用一个单独的线程从多个流中读取数据。这个就需要把这个流转化为非堵塞模式。当在非堵塞模式下的时候,当你尝试去读取数据的时候,一个流可能会返回0或者更多的字节。如果这个流没有数据去读取就会返回0个字节。当这个流中确实有一些数据可以被读取就会返回大于1的字节。
为了避免检查流中有0个字节去读,我们使用JAVA NIO Selector。一个或者更多的SelectableChannel实例可以使用Selector注册。当你调用select()或者selecNow()方法的时候,Selector将只会给你返回SelectableChannel实例,这个里面事实上有数据可以读取。这个设计的图示见下图:
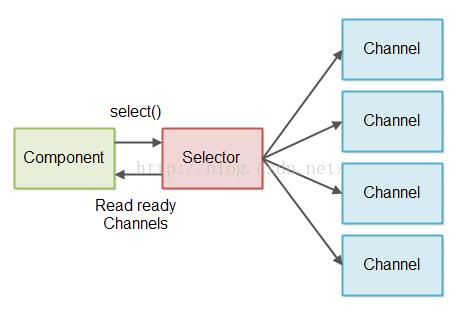
读取部分信息
当我们从一个SelectableChannel中读取一批数据的时候,我们不知道这个数据块包含的数据是否比原来的信息多还是少。一个数据块可能潜在的只是包含一部分信息(比原来的信息少些),一个完整的信息,或者比原来的信息多,例如1.5倍或者2.5倍的信息。各种各样的信息可能如下图所示:
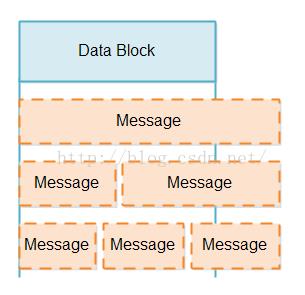
在处理部分信息的时候,这里有两个挑战:
- 检测在数据块中是否是完整的信息。
- 如何处理部分信息直到剩余的信息到达。
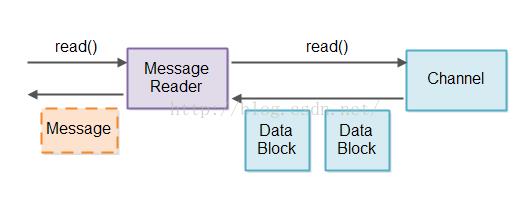
取回一个有数据从Selector中读取的Channel实例之后,然后这个Message Reader关联到那个Channel读数据并且尝试着将它分解成信息。如果那个结果在任何的完整信息中被读,这些信息可以被传递到读管道让任何组件需要处理他们。
一个Message Reader当然是一个协议特定的。一个Message Reader需要知道它正在尝试读取的消息的消息格式。如果我们的服务器实现在协议中是可以重用的,它需要能够有一个Message Reader实现接入-可能从某种方式上通过接收一个Message Reader工厂作为配置参数。
存储部分信息
现在我们已经建立了那个,它是Message Reader的责任去存储部分信息直到完整的信息已经到达了,我们需要指出这些部分信息存储应该怎么样被实现。
这里有两个设计应该被考虑到的事情:
- 我们想尽可能少的拷贝消息数据。因为拷贝越多,性能越差。
- 我们想让完整的信息存储在连续的字节序列中去使得分析信息更容易。
这里有几种方式去实现一个可变大小的缓冲区。他们中的所有都是有优点和缺点的,以至于我们将会在接下来的部分中讨论他们。
通过拷贝调整大小
去实现一个可变大小的缓冲区的第一种方式就是从一个例如4KB的小的缓冲区开始。如果一个信息不能符合这个4KB的缓冲区,一个例如8KB的更大的缓冲区将会被分配,并且来自于4KB的缓冲区的数据将会拷贝进更大的那个缓冲区中。
通过拷贝实现可变大小的缓冲区的好处就是对于一个信息的所有数据都会保持在一起在一个单独的连续的字节数组中。这个将会使得解析信息更容易。
通过拷贝实现可变大小的缓冲区的缺点就是对于更大的信息来说将会导致更多的数据拷贝。
为了降低数据拷贝你可以去解析流经你系统的信息的大小去发现一些缓冲区大小,这样可以降低拷贝的次数。例如,你可能看到大部分的信息小于4KB,因为他们包含非常小的请求和响应。那就意味着第一个缓冲区大小应该为4KB。
然后你可能看到如果一个信息大于4KB,它经常是因为包含一个文件。你然后可能注意到经过你系统的大部分文件都是小于128KB。然后你使得第二个缓冲区的大小为128KB是有意义的。
最后你可能看到一旦一个信息超过了128KB,那么这儿就没有真的一个模式判断这个信息多大,以至于最后的缓冲区大小应该只是最大的信息大小。
伴随着这些3个缓冲区的大小建立在流经你的系统的信息大小的基础上,你将会稍微降低一些数据拷贝。在4KB以下的信息将不会被拷贝了。对于1000000并发的连接,那个将会导致1000000 * 4KB = 4GB,这个在大多数服务器的今天(2015)是合理的。信息在4KB和128KB之间的将会拷贝一次,并且只是4KB的数据将会需要拷贝进入到128KB的缓冲区。信息在128KB和最大的信息之间将会拷贝两次。第一次是4KB将会被拷贝,第二次是128KB的将会被拷贝,以至于对于更大的信息一共是132KB的拷贝。假设这里没有那么多的信息超过128KB的,这个可能是可以接受的。
一旦一个信息已经完全的被执行,那么这个分配的内存应该再一次被释放。那样的话,接收到来自于相同连接的下一个信息再一次以最小的缓冲区开始。这个是需要的去确定这个内存在连接之间可以被更有效率的共享。可能不是所有的连接同时都会需要大的缓冲区。
我有一个完成的教程关于如何实现这样一个内存缓冲区去支持可变数组,地址在这里:http://tutorials.jenkov.com/java-performance/resizable-array.html。这个教程也包含GitHub代码仓库的一个连接,显示了一个工作的实现。
通过追加调整大小
另外一种方式去调整一个缓冲区的大小是使得这个缓冲区由多个数组组成。当你需要调整这个缓冲区大小的时候,你就需要仅仅分配另外一个字节数组然后写数据进去就可以了。
这里有两种方式可以去生成这样的一个缓冲区。一种方式就是去分配分离的字节数组,并且保持一系列这些字节数组。另外一种方式就是去分配一个更大的几片,共享的字节数组,然后保持一系列的这样的片段分配给这个缓冲区。就我个人而言,我感觉这个切片的方式稍微好一些,但是区分很小。
通过追加分离的数组或者切片去生成一个缓冲区的好处就是在写期间没有数据需要拷贝。所有的数据可以直接拷贝来自于Socket(Channel)的数据进入一个数组或者一个切片。
这种方式去生成一个缓冲区的缺点就是数据不会被存储在单独的连续的数组中。这样使得信息解析更难,因为解析器不仅需要去寻找每一个单独的数组的结尾处,同时还要去寻找所有数组的结尾处。因为你需要在写的数据中寻找一个信息的结束处,所以这个模型也不会太简单去实现。
TLV编码信息
一些协议信息格式使用一个TLV格式(类型,长度,值)被编码的。那就意味着,当一个信息来到的时候,这个信息的整个长度被存储到这个信息的开始。那就意味着你会立刻知道对于这个整个的信息分配多少内存。
TLV编码使得内存管理更加简单。你可以马上知道要分配多少内存给这个信息。不会有内存在缓冲区的结尾处被浪费了。
TLV编码一个不好的地方就是,在这个信息的所有数据到达之前你就已经分配了这个信息的所有内存。几个慢的连接发送大的信息从而分配你可用的所有的内存,使得你的服务器不能响应了。
对于这个问题的一个方案就是可以使用一个内部包含多个TLV字段的信息格式。从而,内存被分配到了每一个字段,而不是整个信息,并且只是当字段到达的时候内存才会被分配。同样的,一个大的信息中的一个大的字段在你的内存管理中同样也会有相同的影响。
另外一个方案就是对于还未到达的信息设置超时时间,例如10-15秒。这个就可以使得你的服务器从巧合的,同时的到达许多大的信息中恢复。但是这样仍然会使得你的服务器有一会儿不能响应。此外,一个刻意的Dos攻击仍然会导致你的服务器整个内存都会被分配。
TLV编码存在不同的变化。精确的有多少个字节被使用,这样可以依赖每一个单独TLV编码指定一个字段的类型和长度。这里也会出现TLV编码首先放置字段的长度,然后是类型,最后是数据(一个LTV编码)。虽然字段的顺序是不同的,但是它仍然是一个TLV变种。
事实上,TLV编码使得内存管理更加容易,这也是为什么HTTP1.1是这样的一个糟糕的协议的原因之一。那个也是他们尝试去修复在HTTP2.0中的数据在LTV编码框架中传输的一个问题。这个也是为什么我们为了我们的项目使用一个TLV编码已经设计了我们自己的网络协议。
写部分信息
在一个非堵塞IO的管道中,写数据也是一个挑战。当你在非堵塞模式下调用write(ByteBuffer)写到通道中。这里不能保证大概在ByteBuffer中的多少字节被写入。这个write(ByteBuffer)方法返回多少字节被写,以至于它是可能跟踪写字节的数量。并且那个是一个挑战:一直保持部分写信息的跟踪,以至于一个信息的所有字节都被发送了。
为了管理部分信息的写入到管道中,我们将会创建一个Message Writer,就像Message Reader一样,我们写信息的每一个通道都需要一个Message Writer。在里面的每一个Message Writer,我们将会精确的保持跟踪当前正在写的信息有多少字节被写了。
假如比起它可以直接写到通道的信息,更多的信息到达了Message Writer,在Message Writer内部的这些信息将会排队等候。这个Message Writer尽可能快的写信息到通道中。
这里有一个图示显示迄今为止这个部分信息的写是怎么样被实现的。
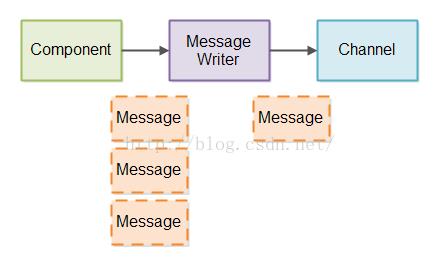
为了使得Message Writer能够早些发送部分信息,这个Message Writer需要不时地被调用,以至于它可以发送更多的数据。
如果你有许多的连接,那么你将会有许多的Message Writer实例。检查例如一个百万的Message Writer实例去看是否他们写任何数据是慢的,首先,Message Writer实例中的许多可能还没有任何信息去发送。我们不想去检查那些实例。第二,并不是所有的Channel实例准备好写入数据。我们不想浪费时间尝试去写数据到无论如何不能接受任何数据的Channel。
去检查是否一个Channel准备好了写数据,你可以使用Selector注册一个Channel。然而,我们不想注册所有的Channel实例。想象如果你有1000000个连接,而他们部分是空闲的,而所有的1000000连接注册到selector中。然后,当你调用这些Channel实例中的大部分select()方法准备写(他们大部分是空闲的,记住了?)你将会不得不检查所有的那些连接的Message Writer是否有数据可以写了。
为了避免检查所有的Message Writer实例,以及无论如何也不会有信息发送给他们的Channel实例,我们使用这两步方法:
- 当一个信息被写到一个Message Writer的时候,这个Message Writer注册它的相关的Channel用selector(如果它还没有被注册)。
- 当你的服务器有时间的时候,它检查这个selector去看哪个注册的channel实例准备好了写。对于每一个准备好写的Channel,它的关联的Message Writer是被需要写数据到Channel中。如果一个Message Writer写了所有它的信息到Channel中,这个Channel将会再一次是未注册的。
- 这个读的管道检查来自于打开连接的进来的数据。
- 这个执行的管道执行任何一个接收到的完整信息。
- 这个写的管道检查是否它可以写任何外部的信息到打开连接的任何一个。

翻译地址:http://tutorials.jenkov.com/java-nio/non-blocking-server.html
以上是关于Java Nio 十一Java NIO:非堵塞服务器的主要内容,如果未能解决你的问题,请参考以下文章