###################################################
当我们系统架构出现瓶颈的时候一般扩展方法分为:
纵向扩展也可以叫垂直扩展,比如扩充服务器的cpu 1颗到2颗 内存8G到16G 磁盘容量扩容...
横向扩展也可以叫水平扩展,比如web服务器从1台,增加到2台...
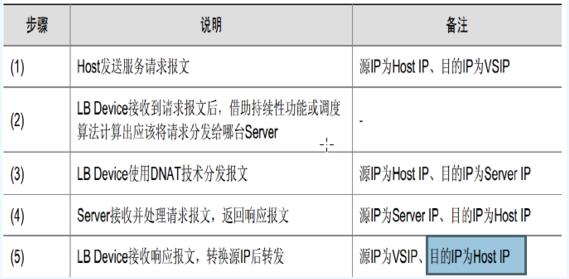
###################################################负载均衡实现方法 之 http的header头 DNS轮询
http header头里面有location域 可以重定向http请求,可以在程序端操作 比如用php来实现,具体方法网上查查。场景 为下载业务提供http代理 下载的时候判断客户端ip然后再重定向到后端下载web服务器,#还有就是CDN的边缘节点,有时候获取的可能locadns的ip?
腾讯cdn白皮书:
作为一名技术人员一定要用合适的技术解决问题
赵班长提供的案例:cdn数据用rsync同步过去,可以认为是一个伪源站,这样就避免了cdn出问题的是,全部回源带宽堵死或服务器压力太大等问题
用dns轮询做负载的场景还是有的 1.DNS轮询ip本身就是高可用 2.某些时候dns轮询可以解决多机房问题
我们再做负载均衡-健康检查 重试次数和频率 一般都是根据实际情况配置 有时候是经验值
在nginx用负载均衡器的时候 当一台web服务器被踢出集群---如果恢复还会自动加入 nginx上面有个等待时间继续检查
负载均衡算法:轮询 加权轮询 ,最小连接数,url(hash)每次请求可能不一样
如果后端服务器是缓存服务器, url(hash)在内存有url-hash表 -马蓉出轨了 被命中的缓存可能会蹦掉,开源的没有解决方案(nginx和haproxy),如果想自动解决的只能二次开发,正常情况用uslhash,负载高的时候用轮询。
网关负载均衡,链接负载均衡 一般都是用硬件去解决实现
#################################################负载均衡实现方法之 nginx haproxy lvs
lvs nat模式 lb负载均衡器要设置为后端服务器的网关
进行了双向的数据包的改写,都是内核基本的改写 可以忽略,实际是和dr模式效率差不多,但是瓶颈主要在带宽,一般内网千兆的
DR模式
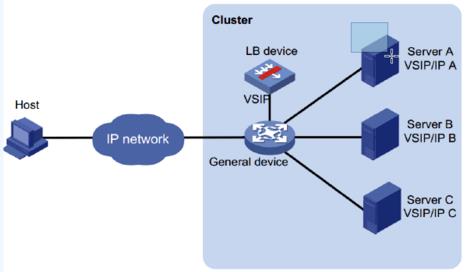
下载站 肯定用dr模式,LB和rserver必须在同一网段,交换机解决冲突域,泛洪,dr 也可以说是二层负载
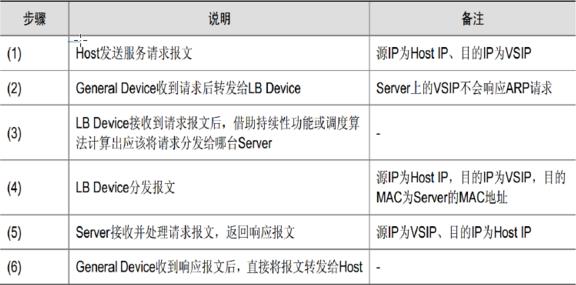
四层负载均衡和七层负载均衡,七层是2个独立的tcp连接,只是一个代理,后端服务器返回给代理,代理返回给用户

haproxy支持4层和7层
双臂路由,单臂路由 服务器直接插在负载均衡端口上
dr模式出现的瓶颈一般是前面的防火墙,因为防火墙有最大连接数限制,可以把防火墙撤销了,可以直接nginx对外,只开80端口。
单一技术栈:反向代理nginx 缓存也是nginx web服务器还是nginx
好处:架构的单一 1.降到成本 2.减少运维对象 3.管理方便 4.减少故障点
架构需要考虑到很多东西: 业务模型 网络环境等等 架构没有固定好了,只有合适的
################web集群中Session处理方案

Session id 一般会存在用户的cookie中
大公司可能会有自己的session框架,tomcat在session存储很大的时候会有问题?
生产环境基本都用redis,memcache有单点故障 /解决问题不要增加架构的复杂度和故障点,技术不是唯一,赵班长在这里引申出了IT管理的ppt
有时候运维坐姿可能导致一个故障,比如没有做好,不小心碰到了回车键,或椅子坏了等等导致意外的键盘错误输入,引发的血案(哈 很有可能,我遇到过开发人员执行rm -rf 都时候手一抖敲到回车了 还好是测试机)
ORM 英语:(Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换
安全问题 性能攻击 研究哪个请求访问数据库,而且可能时间长的 多并发请求
SOA dubbo 阿里有官方支持 熟悉框架,知道运维模式, 京东在去dubbo
常用的搜索可以静态化
cookies记录
在没有登录的时候,购物车放在一下临时的地方,登录的时候可能会在分布式缓存中或数据库
电商网站 系统很复杂,服务架构设计,搜索服务:前端商品搜索 用户搜索
秒杀:1.拉新 找新客户 2.粉丝得到优惠
流量变现,增加用户的粘性
打分平台 进入 异常平台 然后人工审核(比如购买几万的商品,需要客服确认)
推荐系统:
页面前端 用js把用户的行为记录下来,然后放在hoodop里面,然后再推荐
1.让客户买更多的商品
2.推荐一下 存货
是一个营销的收到,技术实现有很多
视频点播
拆单系统,京东是自动拆单
人的资源是最贵的,能不用人就不用
如果官网出现400电话,说明这个网站流量说明不大,如果大400会被打爆的。
沟通的不对等,在工作中是最大的问题。很重要
有时候不涨工作和技术没有关系,你可能觉得自己厉害,但是领导认为你不厉害
做架构尽量少的访问数据库,
数学家 哲学家 计算机专家
有的大公司 一个工作必须2个人,轮询 +备份 哲学观
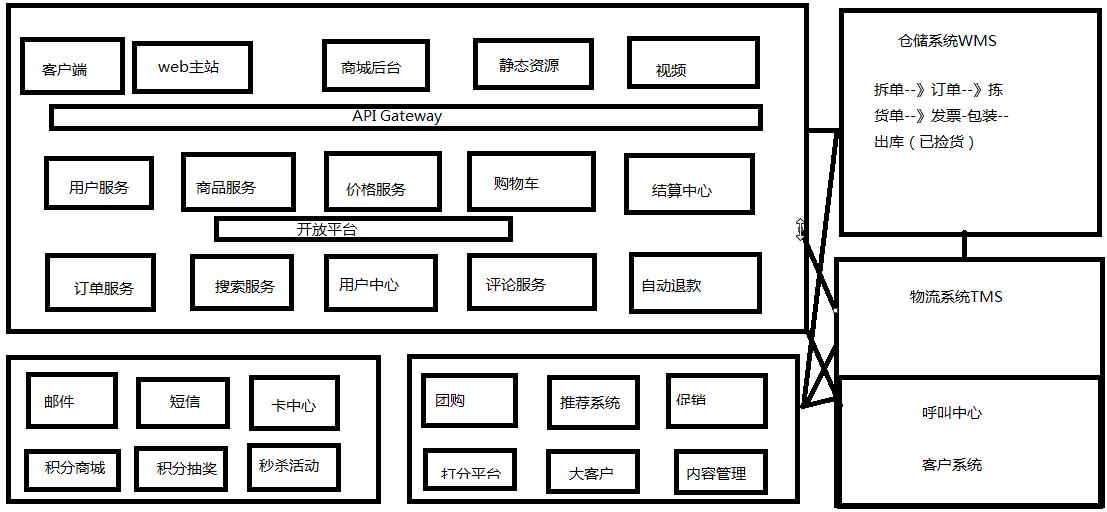

仓储是多级的 前店后仓,和缓存机制是相同的
#######共有云
运维产品化,内部服务 商品化
视频直播很多 公有云都提供了 门槛很低了,没有计算壁垒
学的所有的开源软件,公有云上都有
如果一个新技术,不懂就去公有上看看有没有相关的产品介绍
上云就很难下来了,消息队列等可能不兼容 等等其它问题
####################
来自赵班长的总结
当用户使用代理访问web服务器时候,web服务器只能获取到用户的代理ip,而无法获取的用户的真实ip
公司可以建设一个 评分系统,严格的防止作弊,使用使用代理的都应该减分,进入异常队列,继续进行评分或者人工进行审核
####################haproxy
生产环境除了代理其它后端web都不用80端口,因为80端口需要root启动
运维就是有问题解决问题,需要有这个能力

hatop是一个haproxy的开源工具
haproxy 在线维护 socat 通过unix socket 上线下线等 后端服务器 (#详细配置见群里提供的haproxy配置文档)
echo "help"| socat stdio /var/lib/haproxy.sock 查看帮助
keepalive最早是给lvs做高可用的,所有给haproxy可以不加lvs支持功能 (#详细知识点见群里的keepalive权威指南)
postfix 是keepalive 邮件服务
echo 1 > /proc/sys/net/ipv4/ip_nonlocal_bind 开启允许绑定非本机的IP
keepalive可以管理多个vip
master可以设置恢复抢占或不抢占,默认是抢占的
##########到一个新公司第一件是考虑数据容灾方案,如果没有相关方案,数据出问题那就是大事了
容灾方案常规原则:
1.核心业务,非核心业务
2.从重要数据到非重要数据
3.从下往上(先数据库)
4.灾备演练
5.徘徊在冷备和双活之间,在灾备机房所有的服务都是正常的,可以先切1%的流量,数据回写看是否正常
专线:内部专线(比如世纪互联内部的已经实现好的。),vpn(基于互联网不稳定),运营商专线(mstp按照公里数收费)
问题:
1.流量控制,比如master突然写大量的sql很有可能把专线跑慢了
2.vpn网络延迟大,redis复制永远复制不过去,redis有个backxxx(1.加带宽 2.把内存调小)
3.服务如果是用的ip,灾备要更改ip比较复杂
可以备在云上,支持动态扩展
各大公有云一般都有拉专线服务,一般建议可以远程写
备份数据的删除:
记录在excel表里 找开发确认,然后再删除
备份方案写全了找各部门确认,然后还要定期巡检
运维被黑锅,就是自己做的不好,背锅原因一般是找不到问题的原因
给领导一个可控的方案
单点故障:架构 数据备份 人
思考:
haproxy 主down 所有的连接都没有
有没有有这个机制能保持不断开这些连接
#########
信息系统灾难恢复规范GBT20988-2007 和 跟赵班长学高性能Web架构-集群篇.pdf