Spark是否会替代Hadoop?
Posted 程序员学架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark是否会替代Hadoop?相关的知识,希望对你有一定的参考价值。
我经常会从客户或者网上听到这个问题,尤其是最近几年。那么关于spark哪些被我们神化了,哪些又是真实的,以及它在“大数据”的生态系统中又是怎样的?

说实话,其实我把这个问题作为标题是有问题的,但是我们经常会这样问。Hadoop并不是一个单独的产品而是一个生态系统,而spark也是一样的。下面让我们来一个一个解释。目前Hadoop生态系统主要包括:
- HDFS—Hadoop分布式文件系统。它是一个分布式的、面向块的、不可更新的、高度伸缩性的、可运行在集群中普通硬盘上的文件系统。此外,HDFS还是一个独立的工具,它可以独立于Hadoop生态系统中其他组件而运行(但是如果我们想要使HDFS高可用时,还需要依赖zookeeper和日志管理器,但这又是另外一码事了)。
- MapReduce框架—这是一个基本的在集群中一组标准硬件上执行的分布式计算框架。我们没必要一定在HDFS张使用它—因为文件系统是可插拔的;同样的,我们也没必要一定在yarn中使用它,因为资源管理器是可插拔的:例如我们可以用Mesos来替换它。
- YARN—Hadoop集群中默认的资源管理器。但是我们可以在集群中不使用yarn,而是将我们的mr(译注:map/reduce)任务运行在Mesos之上;或者仅仅在集群中运行不需要依赖yarn的hbase。
- Hive—Hive是一个构建在MapReduce框架之上的类sql查询引擎,它可以将hiveQL语句转换为一系列运行在集群中的mapReduce任务。此外,hdfs也不是唯一的存储系统,也不一定非得使用MapReduce框架,比如在这里我么可以替换为Tez。
- Hbase—基于HDFS的键值对存储系统,为Hadoop提供了联机事务处理(OLTP)能力。Hbase仅仅依赖HDFS和zookeeper;但是Hbase只能依赖于HDFS吗?不是的,Hbase除了可以运行在HDFS上之外,还可以运行在Tachyon(内存文件系统)、MapRFS、IBM GPFS以及其他一些框架之上。
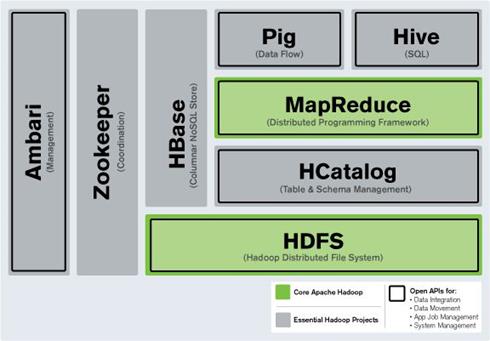
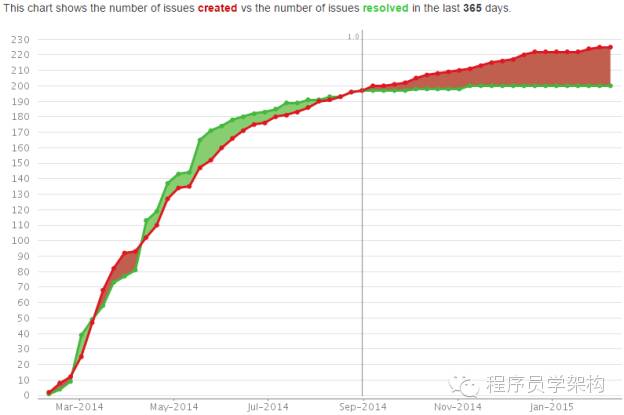
就这么多了。此外你可能还会想到storm可以处理数据流,但是它完全独立于hadoop,可以独立运行;你可能还会想到运行于MapReduce之上的机器学习框架Mahout,但它在之前被社区关注的越来越少。下图为Mahout被反馈的问题(红色)和被解决的问题(绿色)趋势图:
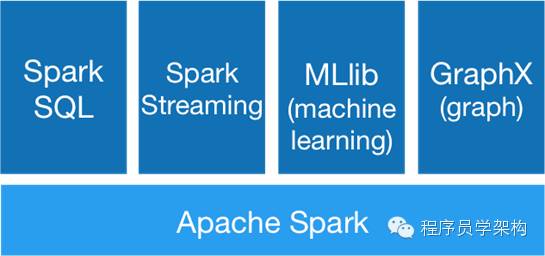
下面我们来说说spark,它主要包含以下几个方面: - Spark Core – 用于通用分布式数据处理的引擎。它不不依赖于任何其他组件,可以运行在任何商用服务器集群上。
- Spark Sql – 运行在Spark上的SQL查询语句,支持一系列SQL函数和HiveQL。但是还不是很成熟,所以不要在生产系统中使用;而HiveQL集成了需要的hive元数据和Hive相关的jar包。
- Spark Streaming – 基于spark的微批处理引擎,支持各种各样数据源的导入。唯一依赖的是Spark Core引擎。
- MLib – 构建在spark之上的机器学习库,支持一系列数据挖掘算法。
此外我们这里还要讲到的是一个关于spark的重要误区—“spark是基于内存的技术”。它不是基于内存的技术;spark是一个管道式的执行引擎,而且在shuffle的过程中会将数据写入磁盘(比如说,如果我们想针对某个字段做聚合操作)、如果内存不够的话也一样会内存溢出(但是内存可以调整)。因此,spark之所以比MapReduce快主要是因为它是管道式处理方式而不是有些人说的“基于内存的优化”。当然,spark在内存中做了缓存来提高性能,但这不是spark真正工作快的原因。
现在,我们再来完整比对一下: - MapReduce可以被Spark Core替换?是的,它会随着时间的推移被替代,而且这种替代是合理的。但是spark目前还不是特别成熟能完全替代MapReduce。此外,也没有人会完全放弃MapReduce,除非所有依赖MapReduce的工具都有可替代方案。比如说,想要在pig上运行的脚本能在spark上执行还是有些工作要做的。
- Hive可以被Spark SQL替换?是的,这又是对的。但是我们需要理解的是Spark SQL对于spark本身来说还是比较年轻的,大概要年轻1.5倍。相对于比较成熟的Hive来说它只能算是玩具了吧,我将在一年半到两年之内再回头来看Spark SQL.。如果我们还记得的话,两到三年前Impala就号称要终结Hive,但是截止到目前两种技术也还是共存状态,Impala并没有终结Hive。在这里对于Spark SQL来说也是一样的。
- Storm可以被Spark Streaming替换? 是的,可以替换。只不过平心而论storm并不是Hadoop生态系统中的一员,因为它是完全独立的工具。他们的计算模型并不太形同,所以我不认为storm会消失,反而仍会作为一个商业产品。
- Mahout可以被MLib替换?公平的讲,Machout已经失去了市场,而且从过去的几年来看它正在快速失去市场。对于这个工具,我们可以说这里是Spark真正可以替换Hadoop生态系统中的地方。
因此,总的来说,这篇文章的结论是: - 不要被大数据供应商的包装所愚弄。他们大量推进的是市场而不是最终的真理。Hadoop最开始是被设计为可扩展的框架,而且其中很多部分是可替换的:可以将HDFS替换为Tachyon,可以将YARN替换为Mesos,可以将MapReduce替换为Tez并且在Tez之上可以运行Hive。这将会是Hadoop技术栈的可选方案或者完全替代方案?倘若我们放弃的MR(MapReduce)而使用Tez,那么它还会是Hadoop吗?
- Spark不能为我们提供完整的技术栈。它允许我们将它的功能集成到我们的Hadoop集群中并且从中获益,而不用完全脱离我们老的集群方案。
- Spark还不够成熟。我认为在过三到四年我们就不会再叫“Hadoop栈”而是叫它“大数据栈”或者类似的称呼。因为在大数据栈中我们有很广泛的选择可以选出不同的开源产品来组合在一起形成一个单独的技术栈使用。
译注:原文发表于2015-2-11
- 本文由程序员学架构翻译
- 转载请务必注明本文出自:程序员学架构(微信号:archleaner)
- 更多文章请扫码:

(长按上图识别二维码)
以上是关于Spark是否会替代Hadoop?的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop对Spark:正面比拼报告(架构性能成本安全性和机器学习)