sql索引实例
Posted 哈喽!树先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql索引实例相关的知识,希望对你有一定的参考价值。
1.创建表并插入数据
在Sql Server2008中创建测试数据库Test,接着创建数据库表并插入数据,sql代码如下:
USE Test IF EXISTS (SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = ‘emp_pay‘) DROP TABLE emp_pay GO USE Test IF EXISTS (SELECT name FROM sys.indexes WHERE name = ‘employeeID_ind‘) DROP INDEX emp_pay.employeeID_ind GO USE Test GO CREATE TABLE emp_pay ( employeeID int NOT NULL, base_pay money NOT NULL, commission decimal(2, 2) NOT NULL ) INSERT emp_pay VALUES (1, 500, .10) INSERT emp_pay VALUES (2, 1000, .05) INSERT emp_pay VALUES (6, 800, .07) INSERT emp_pay VALUES (5, 1500, .03) INSERT emp_pay VALUES (9, 750, .06)
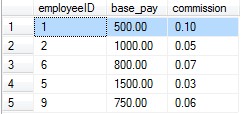
执行完上述sql代码以后我们会发现在Test数据库中多出了一张emp_pay表,数据库表的内容如下图所示:
2.无索引查找
从上图我们可以看出数据库中存储的数据排列顺序与我们插入的先后顺序一致。接下来我们查询employeeID=5的字段,执行如下sql代码:
USE Test SELECT * FROM emp_pay where employeeID=5
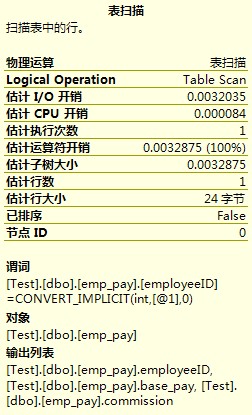
在SQL SERVER MANAGEMENT STUDIO中我们点击“显示估计的查询计划”,会出现如下图所示的查询计划图:

其中表扫描的内容为:
3.创建索引
接下来我们为上述表添加聚集唯一索引,代码如下:
SET NOCOUNT OFF CREATE UNIQUE CLUSTERED INDEX employeeID_ind ON emp_pay (employeeID) GO
在执行完上述创建索引的代码以后,我们再次查询emp_pay的数据内容,如下图所示:

从上图我们可以发现数据内容已经按照employeeID进行了排序。
我们继续执行前面关于employeeID=5的查询,点击“显示估计的执行计划”,出现如下图所示内容:

聚集索引查找的内容为:

总结:
当我们为数据库表中的某一个字段创建索引,并且在查询语句中where子句中用到这样一个字段,那么查询效率会有所提高,我们上述实验因为数据量的关系查询效率提高不明显。
补充
我们上面添加的索引是唯一聚集索引,因此当插入的数据在employeeID字段出现重复时会报错。假如我们在创建索引之前数据字段出现重复,那么就不能创建唯一索引。
创建索引以后的排序(PS:2012-5-28)
执行如下sql语句
update emp_pay set employeeID=7 where employeeID=1;
然后再次执行全表查询,我们发现查询结果如下所示:
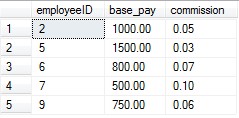
只要我们更新了employeeID,那么最后的更新结果都会按照employeeID的值进行升序排序。这是因为我们在employeeID上创建了索引的缘故。
删除索引(PS:2012-6-4)
我们可以通过sql server management studio这个工具删除索引,也可以通过sql语句进行索引的删除,假设我们要求删除在前面创建的索引employeeID_ind,那么sql语句如下代码所示:
DROP INDEX employeeID_ind ON emp_pay;
以上是关于sql索引实例的主要内容,如果未能解决你的问题,请参考以下文章