Flume实时监控目录sink到hdfs
Posted kwz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flume实时监控目录sink到hdfs相关的知识,希望对你有一定的参考价值。
目标:Flume实时监控目录sink到hdfs,再用sparkStreaming监控hdfs的这个目录,对数据进行计算
1、flume的配置,配置spoolDirSource_hdfsSink.properties,监控本地的一个目录,上传到hdfs一个目录下。
agent1.channels = ch1
agent1.sources = spoolDir-source1
agent1.sinks = hdfs-sink1
# 定义channel
agent1.channels.ch1.type = memory
agent1.channels.ch1.capacity=10000
agent1.channels.ch1.transactionCapacity=1000
# 定义source
agent1.sources.spoolDir-source1.channels = ch1
agent1.sources.spoolDir-source1.type = spooldir
agent1.sources.spoolDir-source1.spoolDir = /home/hadoop/flumeDir
agent1.sources.spoolDir-source1.fileHeader = false
agent1.sources.spoolDir-source1.interceptors=i1 i2
agent1.sources.spoolDir-source1.interceptors.i1.type=timestamp
agent1.sources.spoolDir-source1.interceptors.i2.type=static
agent1.sources.spoolDir-source1.interceptors.i2.key=k
agent1.sources.spoolDir-source1.interceptors.i2.value=v
# 定义sink
agent1.sinks.hdfs-sink1.channel = ch1
agent1.sinks.hdfs-sink1.type = hdfs
agent1.sinks.hdfs-sink1.hdfs.path = hdfs://192.168.1.123:9000/user/hadoop/hdfsSink/%Y-%m-%d
agent1.sinks.hdfs-sink1.fileType = DataStream
agent1.sinks.hdfs-sink1.writeFormat=TEXT
agent1.sinks.hdfs-sink1.filePrefix = flumeHdfs
agent1.sinks.hdfs-sink1.batchSize = 1000
agent1.sinks.hdfs-sink1.rollSize = 10240
agent1.sinks.hdfs-sink1.rollCount = 0
agent1.sinks.hdfs-sink1.rollInterval = 1
agent1.sinks.hdfs-sink1.useLocalTimeStamp = true
2、测试本地目录中的文件是否能被监控传入到hdfs目录
1>、启动flume命令:bin/flume-ng agent --conf conf/ --conf-file conf/spoolDirSource_hdfsSink.properties --name agent1 -Dflume.root.logger=INFO,console &

启动成功!
2>、往/home/hadoop/flumeDir中touch一个文件,d.txt。
flume会监控到这个目录里添加了新文件,就会把这个文件收集到hdfs相应目录下,在hdfs的位置如下图所示:

运行完成的文件,flume会把文件标记为完成,如下所示:

3>、这时候运行的sparkStreaming就会监控到hdfs上的变化,运行必要的逻辑,这里我们是实现简单的计数。
结果如下:
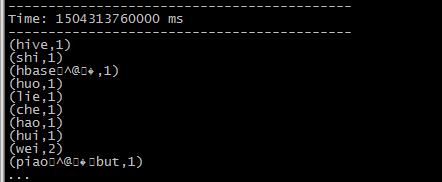
4>、sparkStreaming的代码如下:
package hdfsStreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.Seconds
import org.apache.spark.SparkContext
/**
* 监控HDFS一个目录下的文件,有一定的时间间隔,隔一段时间执行一次
* 要等待执行完成
* 离线的批量流式处理
*/
object HdfsStreaming {
def main(args: Array[String]) {
if(args.length !=1){
println("Usage: <inputPath>");
System.exit(1)
}
//构造配置对象,获取系统默认的配置对象
val conf=new SparkConf
val sc=new SparkContext(conf)
//构造sparkStreaming上下文对象,参数一是配置,参数二是时间间隔30s
val scc=new StreamingContext(sc,Seconds(30))
//指定接收器,参数为hdfs目录
val datas=scc.textFileStream(args(0))
//业务逻辑
val rs=datas.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//打印结果集
rs.print
//启动任务,需要使用上下文对象启动
scc.start
//等待任务完成
scc.awaitTermination
}
}
以上是关于Flume实时监控目录sink到hdfs的主要内容,如果未能解决你的问题,请参考以下文章