消息调度中心的学习资料汇总
Posted gcczhongduan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了消息调度中心的学习资料汇总相关的知识,希望对你有一定的参考价值。
调度中心的资料收集
大众点评网
摘要:大众点评网从2011年中開始使用Hadoop,并专门建立团队。
Hadoop主分析集群共同拥有60多个节点、700TB的容量。月执行30多万个HadoopJob。还有2个HBase线上集群。作者将讲述这各个阶段的技术选择及改进之路。
2011年小规模试水
这一阶段的主要工作是建立了一个小的集群。并导入了少量用户进行測试。为了满足用户的需求,我们还调研了任务调度系统和数据交换系统。
集群搭建好,用户便開始使用,面临的第一个问题是须要任务级别的调度、报警和工作流服务。
当用户的任务出现异常或其它情况时。须要以邮件或者短信的方式通知用户。
并且用户的任务间可能有复杂的依赖关系,须要工作流系统来描写叙述任务间的依赖关系。我们首先将目光投向开源项目Apache Oozie。Oozie是Apache开发的工作流引擎,以XML的方式描写叙述任务及任务间的依赖,功能强大。但在測试后。发现Oozie并非一个非常好的选择。
Oozie採用XML作为任务的配置。特别是对于MapReduce Job,须要在XML里配置Map、Reduce类、输入输出路径、Distributed Cache和各种參数。在执行时,先由Oozie提交一个Map only的Job,在这个Job的Map里,再拼装用户的Job,通过JobClient提交给JobTracker。
相对于Java编写的Job Runner。这样的XML的方式缺乏灵活性。并且难以调试和维护。先提交一个Job。再由这个Job提交真正Job的设计,我个人觉得相当不优雅。
还有一个问题在于,公司内的非常多用户,希望调度系统不仅能够调度Hadoop任务,也能够调度单机任务,甚至Spring容器里的任务,而Oozie并不支持Hadoop集群之外的任务。
所以我们转而自行开发调度系统Taurus(https://github.com/dianping/taurus)。Taurus是一个调度系统,通过时间依赖与任务依赖,触发任务的运行,并通过任务间的依赖管理将任务组织成工作流;支持Hadoop/Hive Job、Spring容器里的任务及一般性任务的调度/监控。
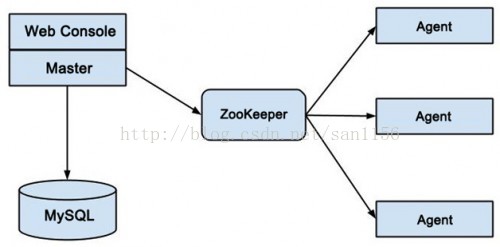
图1 Taurus的结构图
图1是Taurus的结构图。Taurus的主节点称为Master,Web界面与Master在一起。用户在Web界面上创建任务后,写入mysql做持久化存储,当Master推断任务触发的条件满足时。则从MySQL中读出任务信息。写入ZooKeeper;Agent部署在用户的机器上。观察ZooKeeper上的变化,获得任务信息,启动任务。Taurus在2012年中上线。
可视化界面
总结
图5是各系统整体结构图。深蓝部分为自行开发的系统。
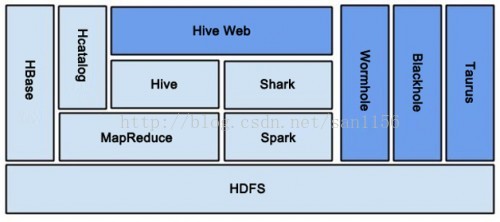
图5大众点评各系统整体结构图
在这2年多的Hadoop实践中,我们得到了一些宝贵经验。
· 建设一支强大的技术团队是至关重要的。
Hadoop的生态系统。还处在高速演化中,并且文档相当匮乏。
仅仅有具备足够强的技术实力,才干用好开源软件,并在开源软件不能满足需求时。自行开发解决这个问题。
· 要立足于解决用户的需求。用户须要的东西,会非常容易被用户接受。并推广开来;某些东西技术上非常easy,但能够解决用户的大问题。
· 对用户的培训。很重要。
架构图(还有一篇关于大众点评的数据平台的文章)
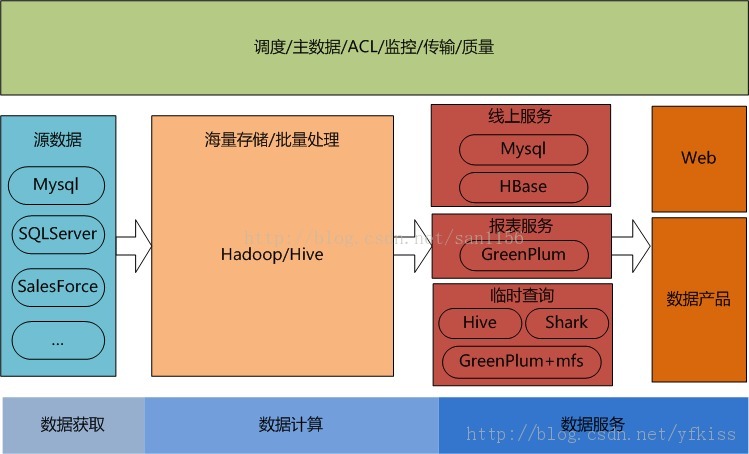
思考总结:
1、 前置条件驱动后置条件。任务的依赖关系处理有master统一管理,因此全部client的状态管理,master必须得知。
2、 Zookeeper是消息中间件。负责master与agent之间的消息传输。属于核心模块。
3、 亮点:web界面能够控制任务启动。
可是,为什么Web界面与Master在一起。
4、 框架介绍得比較清楚,关键技术不清楚。比如master与agent的通信协议(或者zookeeper的内部处理机制)、数据库模型(怎样处理任务之间的依赖。怎样避免任务依赖产生回路)
5、 调度中心、传输数据、监控是数据平台的基础组件。像快速公路一样,仅仅有铺设好了,汽车才干跑得更快。
參考文章:
大众点评的大数据实践:
http://www.csdn.net/article/2013-12-18/2817838-big-data-practice-in-dianping
大众点评数据平台架构变迁:
http://blog.csdn.net/yfkiss/article/details/16838941
阿里巴巴
淘宝海量数据产品技术架构
数据产品的一个最大特点是数据的非实时写入。正由于如此,我们能够觉得,在一定的时间段内。整个系统的数据是仅仅读的。这为我们设计缓存奠定了很重要的基础。

依照数据的流向来划分,我们把淘宝数据产品的技术架构分为五层,各自是数据源、计算层、存储层、查询层和产品层。位于架构顶端的是我们的数据来源层,这里有淘宝主站的用户、店铺、商品和交易等数据库。还实用户的浏览、搜索等行为日志等。这一系列的数据是数据产品最原始的生命力所在。
文章结束时,提到:虽然如此,整个系统中仍然存在非常多不完好的地方。一个典型的样例莫过于各个分层之间使用短连接模式的HTTP协议进行通信。
这种策略直接导致在流量高峰期单机的TCP连接数非常高。
所以说,一个良好的架构固然可以在非常大程度上减少开发和维护的成本,但它自身一定是随着数据量和流量的变化而不断变化的。
我相信,过不了几年。淘宝数据产品的技术架构一定会是另外的样子。
SKYNET
天网调度系统(SKYNET)作为淘宝数据平台的核心调度系统,承载着淘宝数据跨部门/数十条业务线/超过一万个作业的调度和运维工作,具有图形化、跨平台、自己主动部署、线上运维、智能容灾的特点,是淘宝数据平台的中枢系统。
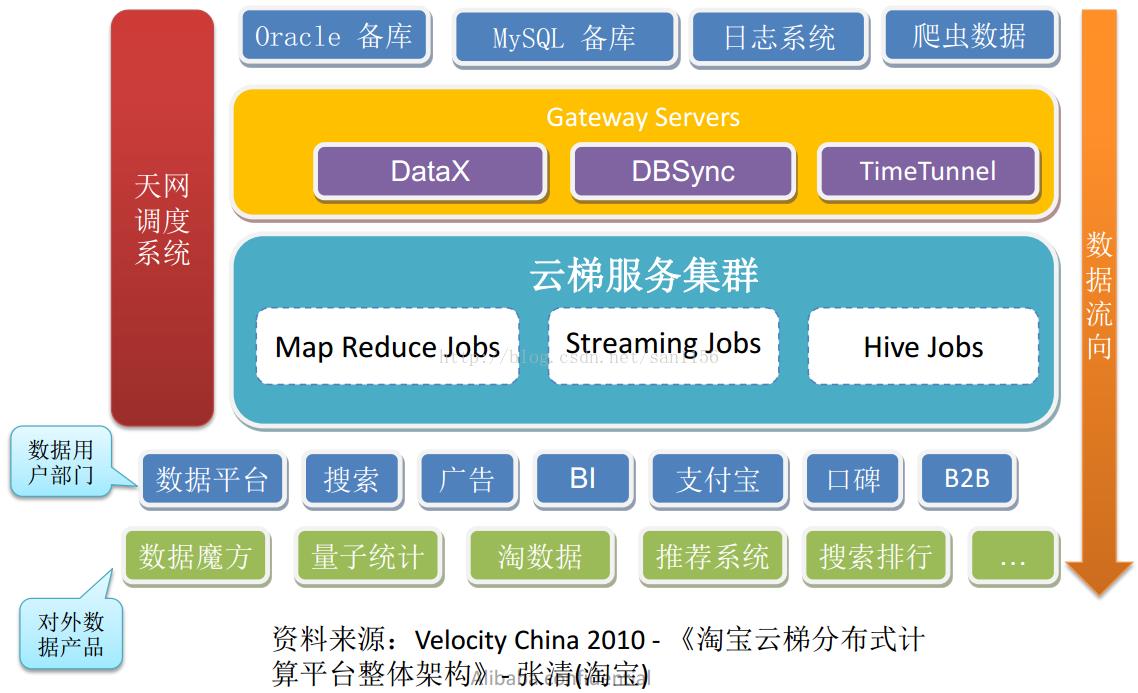
思考总结:
1)结合我们自己的数据交换平台。相同存在server单机的TCP连接数较高的问题。与王老师、郑辉、项老师讨论。考虑使用数据库连接池实现。
难度较大。
2)思考我们的数据平台,面向层级的设计须要加强。应尽可能减少各模块之间的耦合。减少维护成本。
參考文章:
淘宝数据魔方技术架构解析
http://www.alidata.org/archives/1789
阿里数据平台的技术罗列,重点查看天网调度系统:
http://www.alidata.org/about-us/tech
淘宝的数据产品:
## 淘宝魔方:http://mofang.taobao.com/
## 淘宝指数:http://shu.taobao.com/
迅雷
大数据的重要性已毋庸置疑,但大数据的採集、存储、处理、分析、研究。却不是一朝一夕炼成的!数据平台怎样建设,推荐系统怎样运算,等等,都是我们所关注的话题。
迅雷的大数据架构

# 文章简介迅雷数据平台的建设方案,分为五层:採集、原始数据存储、ETL计算、DW层存储、业务层。
# 贯穿五层的两个重要模块:认证与授权、事件驱动调度。
##一块是认证与授权,从上到下全部东西都须要经过认证和授权,作为一个公司级集中式的存储平台。每一个部门存储都会在这儿做。所以你必须保障数据安全和资源合理分配.
##还有一块是事件驱动调度:须要把后置依赖前置改成前置驱动后置,前置任务跑成功了之后,将该任务相应的“数据事件”扔到调度总线里面去,由总线把须要依赖这个“数据事件”的其它任务调起来。当然该任务可以马上跑。还要考虑究竟层计算引擎眼下的负载等情况。

上图是调度引擎大体的架构:最核心部分是调度总线,数据分为是Task和Job,Task维护计算逻辑,如运行的SQL脚本等。Job维护调度逻辑。如依赖什么“数据事件”,一个Task能够配置多个Job。
最左边是Web接口。前端通过该接口查询任务状态,以及控制任务等。最右边是计算环境的适配层。
------(没看懂)
企业大数据建设案例分享
http://www.csdn.net/article/2013-07-31/2816417-CTO-club-tecent
百度
数据平台架构

# 我们不论什么的平台和系统不可能解决全部的问题
# 仓库是攻克了增量、批量、流式这样的混杂的模型,跟全套的解决方式
# 一个系统。想做到高效。是一定有损失的。
重点是实效,一定要快,会损失什么?会损失准确,可能会是不精准。不精准的意思可能会丢。--------------不同的应用场景,对数据的要求不一样。我们的产品是基于如何的应用场景,要解决如何的问题。
刘立萍:百度大数据平台介绍
http://www.csdn.net/article/a/2012-12-01/2812397
腾讯
数据服务整体框架

參看文章:
腾讯大规模Hadoop集群实践
http://www.csdn.net/article/2014-02-19/2818473-Tencent-Hadoop
数据平台的建设思考
现状与问题分析
在数据量日益添加的情况下,数据平台须要加强服务分层处理和调度中心统筹管理。
眼下。公司的数据后台逐渐分层。
分层设计。减少了系统之间的耦合,有助于新功能的实现,有助于更好的推动业务发展。
只是。层级之间的响应须要加强。
各个层级不能各自为政,否则会导致层级之间响应缓慢,而且不便于日常维护、统一管理与新业务拓展。
问题
1、数据库job运行的问题,依赖数据库本身的job机制无法做到智能的多次处理以及有问题时及时提醒,另外,出现异常之后再人工处理耗时较多。假设能有一个完整的程序依照顺序和条件把须要补的过程有条不紊的补上会节省非常多后期补报表数据的时间。
2、数据交换平台,对实时数据的交换,採用轮训数据库的方式。简单粗暴。假设升级成消息驱动机制,能够提高系统响应速度,便于工作流、任务流的连贯运行。减少数据库的压力。
3、数据流的连贯性存在问题,层与层之间缺少运行前的条件推断。假设过于紧凑,可能出现错误。假设过于松散。会影响到效率。
数据平台的思考(完好ing)
基于以上的分析,思考数据平台的建设想法。
数据交换平台
优化后台数据库之间的关联关系,从网状结构,过渡到中心结构。
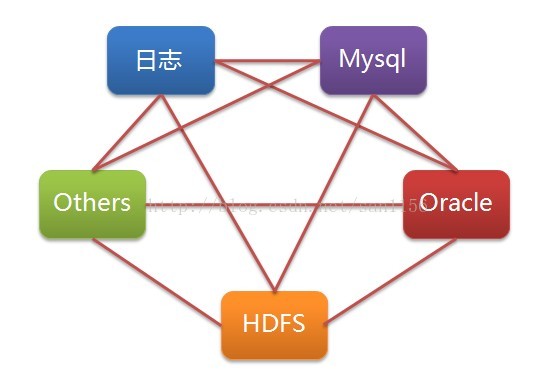
网状结构
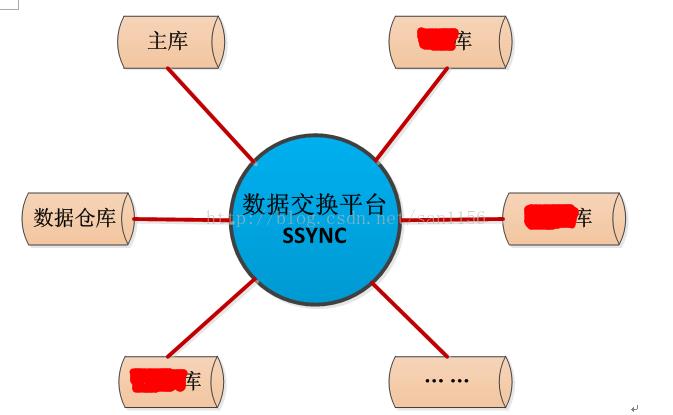
中心结构
调度中心的建设思考
调度中心的作用
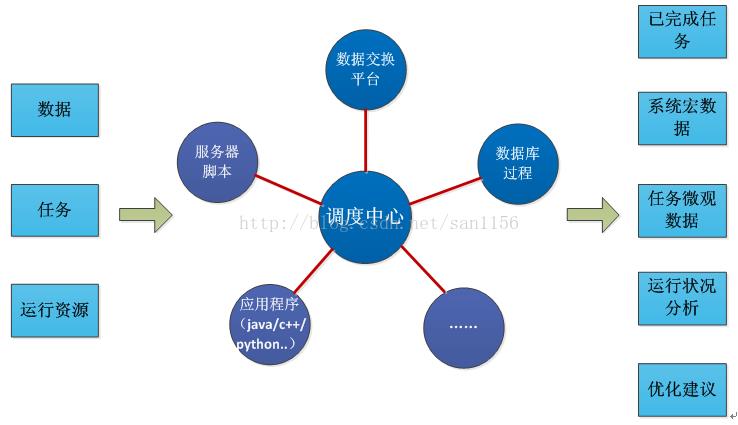
1、梳理数据流。明白任务之间的依赖关系,可视化管理。便于维护扩展。
2、任务运行连贯,系统响应速度提高。吞吐提高。server的计算能力得到较为充分的发挥。
3、日常维护便捷。调度中心提供执行的数据指标,便于监控系统及时发现问题并报警,缩短故障发现时长与处理时长。
调度中心的架构

有下面特点:
# redis:消息中间件。负责master与agent的通信,负责记录调度中心执行日志
# master:负责处理任务之间依赖关系(前置任务驱动后置任务)、日志记录、agent管理(注冊等)、异常处理,等。
# agent:agent之间互不知晓,负责运行某类别的任务。关于同一时候运行的任务个数或是否马上运行,由agent自行控制,影响因素比如自身server性能等。
# Oracle:配置数据库。持久化任务配置參数。
#WebConsole:对后台任务进行可视化地实时性地查看与管理,连接redis。
几个难点:
# 数据库模型设计,存储任务之间的依赖关系,便于对任务类别的扩展
# redis的使用预研与demo开发(使用c++操作)
# master与agent的通信协议。便于扩展
# 数据库连接池的技术实现。避免出现后期瓶颈
问题与讨论
以上是关于消息调度中心的学习资料汇总的主要内容,如果未能解决你的问题,请参考以下文章
macOS Ventura「台前调度」与原有的「调度中心」有什么不同?
macOS Ventura「台前调度」与原有的「调度中心」有什么不同?