基于headless chrome的游戏资源下载实现 (初版)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于headless chrome的游戏资源下载实现 (初版)相关的知识,希望对你有一定的参考价值。
 上周介绍了实现前端资源下载的思路,今天给一个简单的初版代码。
上周介绍了实现前端资源下载的思路,今天给一个简单的初版代码。
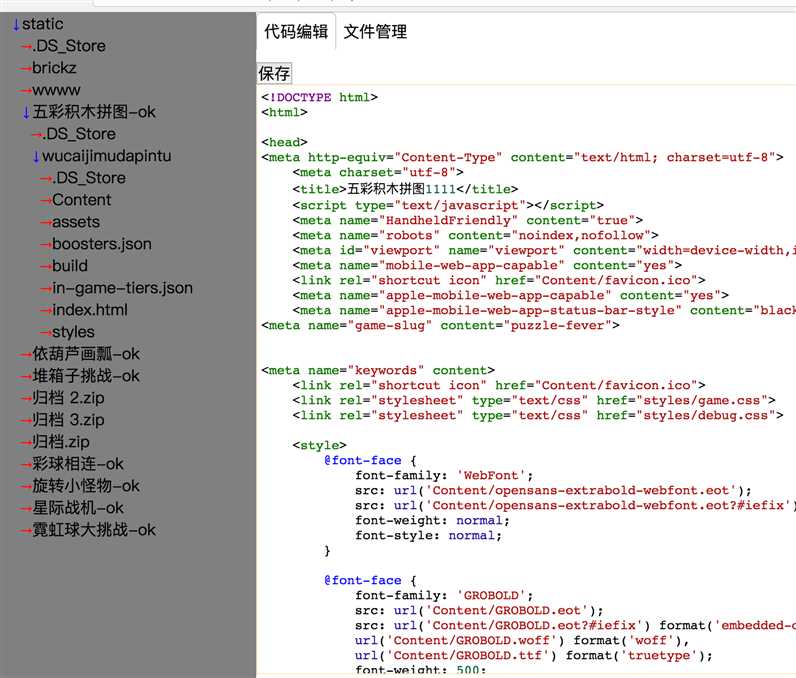
首先 基于express启动一个服务端容器,用于处理前端路由和后段逻辑处理,目录结构如下:

其中gameDir是游戏存放的地址,node_modules是存放用到插件的module,server内部目录结构如下

app.js是程序的启动代码
common 存放公用的方法
public 存放静态资源
routes 存放express路由信息
config存放一些配置信息
downLoadGame存放游戏下载的逻辑代码
view是ejs试图存放的地方
bin(可以删掉)
dist和react存放react相关代码,后期用react实现前端页面
目前程序只是初版存在很多问题主要如下:
1.下载过程没有进度信息
2.如果资源下载失败没有提供单独下载入口
3.对页面url解析不智能
4.不支持游戏列表倒入下载
5.音频转码没有默认只下载url检测到的音频格式
6.程序的容错处理不完善
在实现下载过程总遇到的问题:
1.由于是基于node实现,需要考虑异步调用问题。
2.需要对下载资源进行队列操作,避免io错误。
3.对监测到的url进行进行预处理,避免不必要的?查询参数和错误的url开头
由于代码还是初版还有很多地方需要修改,暂且不上传。
另:同事提供了另外解决思路 及可以编辑webkit内核源码,自动完成资源下载过程
最后附上 页面截图
第一个截图包括下载功能 下载到本地游戏的启动功能 下载目录浏览功能
第二个截图对应目录浏览
第三个截图对应启动游戏功能


以上是关于基于headless chrome的游戏资源下载实现 (初版)的主要内容,如果未能解决你的问题,请参考以下文章