kafka内部结构笔记
Posted wyett
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafka内部结构笔记相关的知识,希望对你有一定的参考价值。
集群架构
搭建一套测试集群,共三个节点,每个节点上面都有procuder/broker/consumer角色。没有WebUI页面,架构如下:
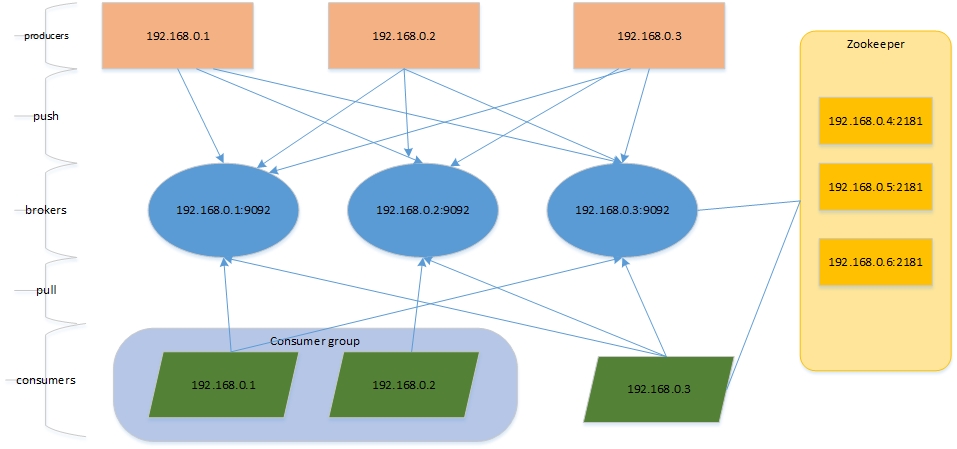
kafka架构
在系统架构中,将消息系统独立可起到架构解耦、易扩展、灵活性强、可恢复、数据冗余、异步通讯等优点。
kafka是分布式消息系统软件,实现了消息发布/订阅功能。还有一些其他的消息队列软件,比如RabbitMQ、Redis、ZeroMQ、ActiveMQ、RocketMQ等。这些消息系统各有优缺点。
kafka的优点如下:
- 时间复杂度为O(1);性能与数据量多少无关;
- 高吞吐,100k条/s;
- 消息分区
- 分布式消费。
- Scale out。
组件
producers(生产组件,消息来源)
producers是消息来源,提供消息写入接口,与zookeeper来实现数据的写入均衡。具体的写入过程见。
与producers有关的内容有:
- 写入流程;
- 如何实现均衡写入;
- 修改topic的分布;
- 维护存储的
producers和borders的数据写入方式是push。
consumers(消费组件,消息流出)
consumers是消息系统的流出接口,多个consumers逻辑上组成consumer Group。CG的目标是实现同一需求的消费吞吐量。
同一个topic的message,只能被同一CG的一个Consumer消费;但可以被不同多个CG消费;
比如上图中,一条message被CG中的的C161消费,或者被C163消费,但不能同时被C161和C163消费。因为同一CG在zk中维护共同维护对一个topic的消费pos。
与consumers相关的内容有:
- topic实现广播与单播。
- 消费的负载均衡。
- message的消费实现。
brokers(消息管理,存储/删除/)
brokers的物理结构
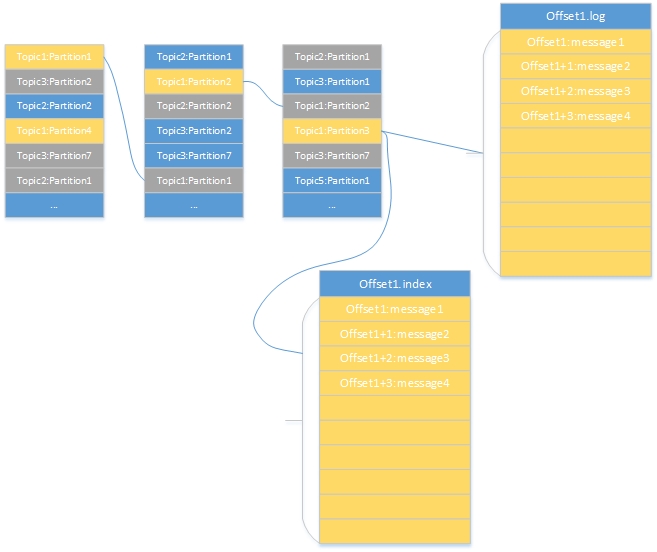
图片备注:
- 一共三个broker,存储了不同的topic;
- 以topic1为例,topic1有多个partitions,图中黄色部分为partition1-4,存储在不同的brokers上,这些是partition的Leader;
- 灰色的topic1:partition1-4,作为partition的replica,图中我们的的副本数为2,在server.properity配置文件中由参数offsets.topic.replication.factor控制;
- topic1:partition3有一个segments,由一个offset.index和offset.log组成。
- offset.log有多个message顺序写入,命名是起始message的offset。
brokers的存储内容归纳如下:
- broker——>topics——>partitions——>segments(index and logs)
- 一个broker上存储不同的topic;
- topic是逻辑结构,相当于query,不同的topic由多个连续的partition组成,每个partition对应一个物理文件夹;
- kafka实现replica的单元是partitions,由参数offsets.topic.replication.factor控制,默认是3,Leader提供读写,由zk配合进行Leader的选举,选举过程见;
- 每个partition由多个segments组成(index和log),命名为起始message的offset;
需要了解
- 信息存储,message的存储格式,
- Replica的数据同步
- Leader选举
- HA方案与故障恢复
- 过期数据清理
组件
zookeepers(负责选举,均衡,meta记录,消费记录)
zookeeper在集群中与broker和consumer进行交互,维护数据和集群高可用。
- 记录consumer消费message的位置信息;
- partitions故障时进行Leader Election
- kafka的meta信息在zookeeper如何存储
kafka在zookeeper的结构图如下:
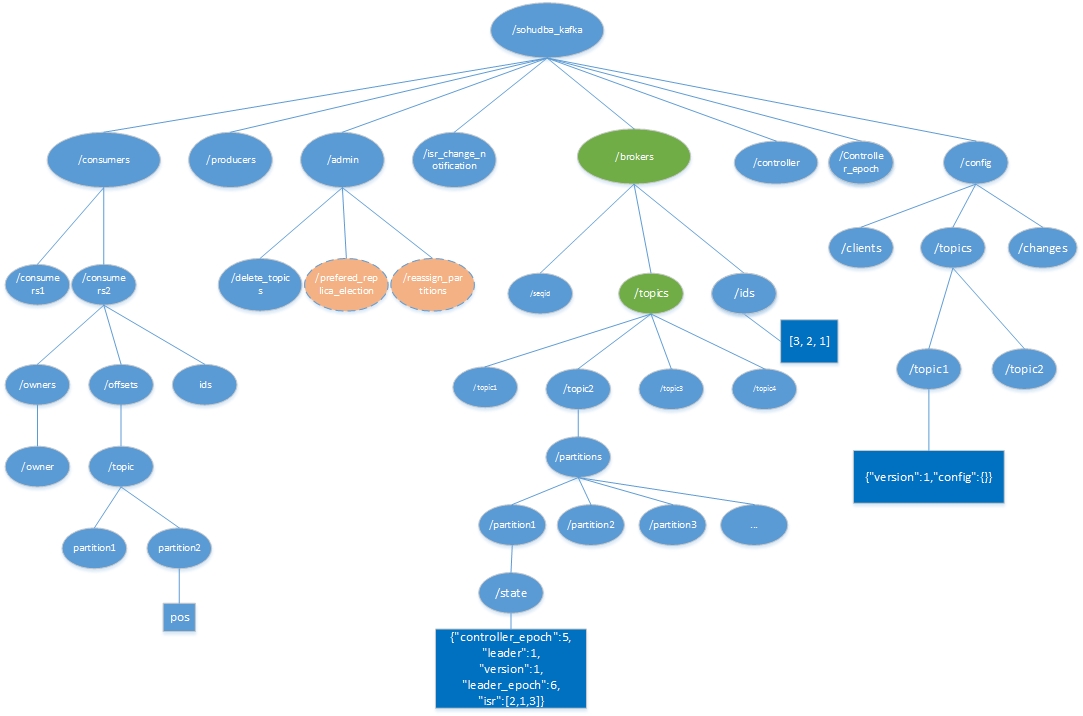
三级目录是一些组件:
- consumers consumers的信息,记录对partition访问偏移量,由consumer自己维护,目录/sohudba_kafka/consumers/[consumer]/offsets/[topic]/[partition]
- broders 维护broders的信息,包含borders下的partition,每个partition的ISR,当前leader,目录结构比较复杂,我们后面细说;
- producers producers的信息,当前zookeeper未记录任何信息
- admin admin维护删掉的topic,partition的重新分配(过后删除),partition选举Leader(过后删除)
- config
- controlers 增删topic/重新分配replica/RPC通知其他broker
- controler_epoch
- isr_change_notifications
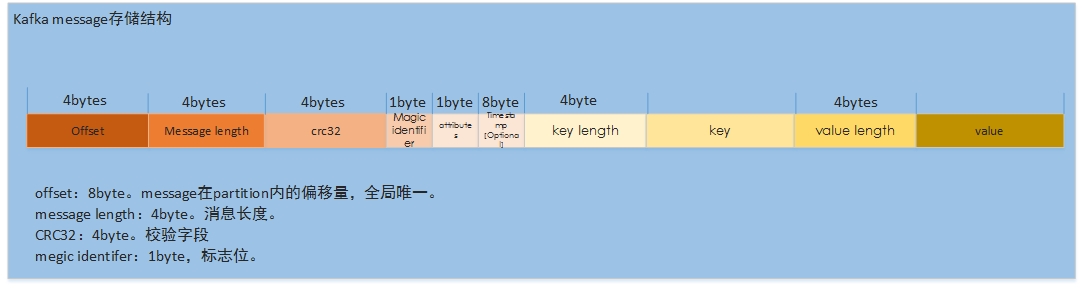
信息存储
message结构
zookeeper对各节点的数据存储
borker数据存储目录:/borker/topics/[topic]/partitions/[partition]/state
state数据结构:
{"controller_epoch":5, ##表示kafka集群中的中央控制器选举次数
"leader":1, ##当前partition的leader所在的borker id
"version":1, ##版本编号默认为1
"leader_epoch":6, ##leader选举次数
"isr":[2,1,3] ##当前partition的In-sync replica,副本组的borker id列表
}
borker数据存储示例:


{"version":1,
"partitions":{
"45":[2,1,3],
"34":[3,2,1],
"12":[2,3,1],
"8":[1,2,3],
"19":[3,1,2],
"23":[1,3,2],
"4":[3,2,1],
"40":[3,2,1],
"15":[2,1,3],
"11":[1,3,2],
"9":[2,1,3],
"44":[1,2,3],
"33":[2,1,3],
"22":[3,2,1],
"26":[1,2,3],
"37":[3,1,2],
"13":[3,1,2],
"46":[3,2,1],
"24":[2,3,1],
"35":[1,3,2],
"16":[3,2,1],
"5":[1,3,2],
"10":[3,2,1],
"48":[2,3,1],
"21":[2,1,3],
"43":[3,1,2],
"32":[1,2,3],
"49":[3,1,2],
"6":[2,3,1],
"36":[2,3,1],
"1":[3,1,2],
"39":[2,1,3],
"17":[1,3,2],
"25":[3,1,2],
"14":[1,2,3],
"47":[1,3,2],
"31":[3,1,2],
"42":[2,3,1],
"0":[2,3,1],
"20":[1,2,3],
"27":[2,1,3],
"2":[1,2,3],
"38":[1,2,3],
"18":[2,3,1],
"30":[2,3,1],
"7":[3,1,2],
"29":[1,3,2],
"41":[1,3,2],
"3":[2,1,3],
"28":[3,2,1]
}
}
数据操作
为避免broker挂后造成数据丢失,kafka实现了高可用方式。
- 基于partition实现Replica。并与zookeeper配合实现Leader的选举。
- 通过算法,将partition的Leader与Fellowers分散于不同的broker。
replica实现
在“brokers的物理结构”中,replication有多个follewers,分散于不同的brokers。通过增量日志实现。
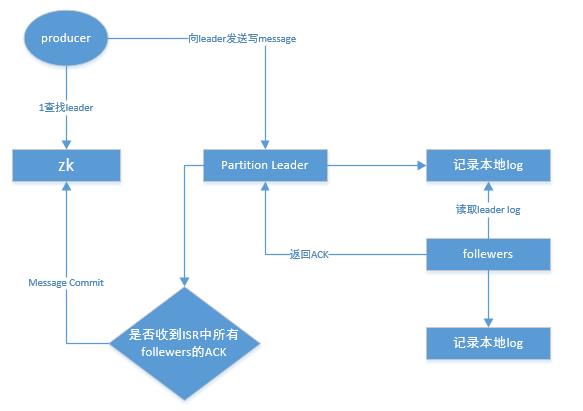
partition的log记录是顺序的,通过server.properties中log.retention.hours参数定义日志保留时长,过期则删除。新写入的message append记录在partition中。
为提升效率,
- follewers会在message未写入log时,读到message则将ACK发送给Leader,因此只能保证存在Replica,不能保证数据一定持久化了。
- 批量复制
ISR是In-Sync Replicate 记录与Leader保持同步的列表。
Leader Election
判断Replica活着,(1)与zk有心跳通讯;(2)与Leader通讯及时。两者有一不满足,fellower都会从ISR中移除。
选举算法
一般的leader选举算法,有Majority Vote/Zab/Raft/PacificA。kafka采用的即PacificA,kafka维护多个ISR,但不不像Majorty Vote算法,限制最少的2N+1节点和N+1以上投票。
即使只有1个follewer,也可完成Leader选举。
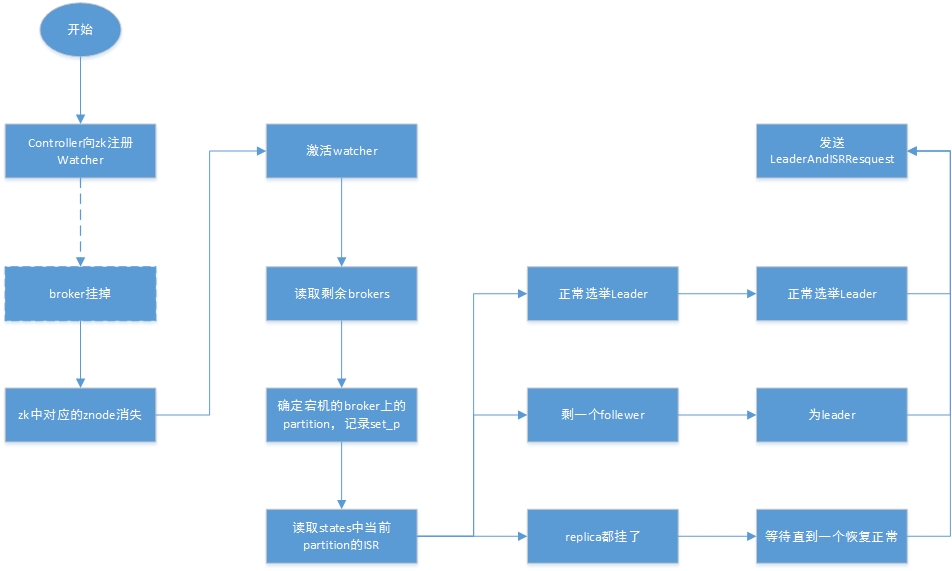
选举过程
以上是关于kafka内部结构笔记的主要内容,如果未能解决你的问题,请参考以下文章