_sed命令
Posted it芮菜鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了_sed命令相关的知识,希望对你有一定的参考价值。
三大文本处理工具:grep,sed(流编辑器),awk(报告文本生成器)
sed基本用法:sed是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有 改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
sed:Stream EDitor
用来操作纯ASCII码的文本,逐行编辑
行编辑器
逐行读取到内存空间,在内存中做处理然后显示到屏幕上来
这段内存空间称模式空间,sed按行处理,不一定每一行都会读取到内存中去,符合条件的读进模式空间做模式条件匹配,如果被条件匹配到了,在模式空间中使用后面的编辑命令对其完成编辑并且将编辑的结果输出到屏幕上来。
默认不编辑原文件,仅对模式空间中的数据做处理;而后,处理结束后,将模式空间打印至屏幕
sed [options] \'AddressCommand\' file ...
-n:静默模式,不再默认显示模式空间中的内容
-i:直接修改原文件
-e SCRIPT -e SCRIPT:可以同时执行多个脚本
-f /PATH/TO/SED_SCRIPT
sed -f /path/to/scripts file
-r:使用扩展正则表达式
Address:
1、StartLine,Endline
eg1,100从第1行到第100行
$:最后一行
$-1:倒数第二行
2、使用模式
/RegExp
/^root/:找以root开头的行
3、/pattern1/,/pattern2/
第一次被模式1匹配到的行开始到第一次被模式2匹配到的行结束,这中间的所有行
4、LineNumber
指定的行
5、StartLine,*N
从StartLine开始,向后的N行
Command:
d:删除符合条件的行,这样被匹配到的就不显示,匹配到的才显示
!注:因为sed默认不编辑原文件,所以删除符合条件的行,原文件中的行是没有被删掉的,删掉的只是模式空间中符合条件的行,然后将模式空间打印至屏幕
p:显示符合条件的行

在此可以发现,符合条件——开头是/的行显示了两次,为什么?
模式空间显示一次,p命令显示一次。
那么怎么只打印符合条件的行呢?
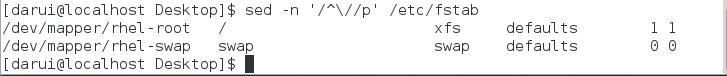
加-n选项,不再显示模式空间中的内容
a \\string:在指定的行后面追加新行,内容为string
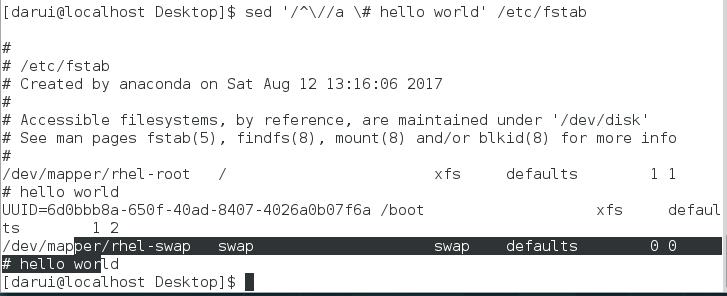
i \\string:在指定的行前面添加新行,内容为string
r FILE:将指定的文件的内容添加到符合条件的行处
w FILE:将指定范围内的内容另存至指定的文件中

s/pattern/string/修饰符:查找并替换,默认只替换每行中第一次被模式匹配到的字符串
加修饰符
g:全局替换
i:忽略字符大小写
s///:s###,s000:以上命令中字符/在sed中作为定界符使用,也可以使用任意的定界符,即s/pattern/string/=s#pattern#string#
\\(\\), \\1, \\2 :子串匹配标记 ,匹配给定样式的其中一部分
eg

个人理解,如有错误,还望指出:1、首先查找digit \\( [ 0-9]\\),查找到为digit 7
2、又因为\\1在此匹配子串[0-9],即匹配子串7
3、因此结果是查找到digit 7然后用7替换

这里需要注意到的,对于匹配到的第一个子串就标记为\\1,依此类推匹配到的第二个结果就是\\2
所以可以理解为:1、首先从全局上看,是将符合([a-z]+\\) ([A-Z]+\\) 条件的子串替换成\\2 \\1
2、又因为匹配到的第一个子串就标记为\\1,依此类推匹配到的第二个结果就是\\2,所以在此\\([a-z]\\+\\)匹配到为\\1,\\([A-Z]\\ +\\)匹配到为\\2
3、所以替换成\\([A-Z]\\ +\\)\\([a-z]\\+\\),即BBB aaa
l..e:like-->liker
love-->lover

like-->Like
love-->Love

&:引用模式匹配整个串

以上是关于_sed命令的主要内容,如果未能解决你的问题,请参考以下文章