HBase原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase原理相关的知识,希望对你有一定的参考价值。
数据模型
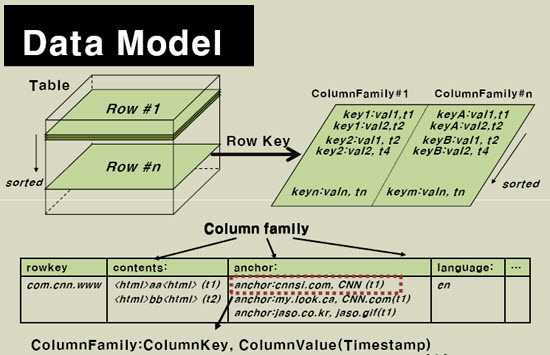
逻辑模型
物理模型
问题:
数据在更新时首先写入Log(WAL log)和内存(MemStore)中,MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。于此同时,系统会在zookeeper中记录一个redo point,表示这个时刻之前的变更已经持久化了。(minor compact)
当系统出现意外时,可能导致内存(MemStore)中的数据丢失,此时使用Log(WAL log)来恢复checkpoint之后的数据。
这个checkpoint 和 redo point 怎么用?
redo point 记录持久化到那里了
先写Hlog再写内存?
些Hlog不影响速度吗?不是随机读写,是顺序写入,连续写入 ; 异步
Regin 信息放在zookper中,HBAse的元数据信息,表,列族信息也在zookper中
hbase中的数据flush到hfile之后还修改吗?这个时候如果再更新是怎么做的?又是怎么做到更新后依然排序的?
物理存储
split
compact
为什么HBASE快
数据模型
HBase以表的形式存储数据。表有行和列组成,列划分为若干个列族,如图所示:
- 逻辑数据模型
- 物理数据模型
物理存储
- HBase所有行按照Rowkey进行字典排序,Table在行的方向分割为多个region
- Region 按照大小进行分割,每个table最初只有一个Region,随着数据的不断插入,Region不短增大,当增加到一定阈值后,从中间分裂成两个Region。 Table中的数据不断增加,就会有越来越的Region
- Region是HBase分布式存储和负载均衡的最小单元,一个region只能在一个RegionServer上。
- Region虽然是分布式存储的最小单元,但不是存储的最小单元(内部有更详细的结构)。内部划分为多个Store,一个Store对应一个Column Family。 Store内部又分为一个MemStore和零到多个Storefile。Storefile以Hfile的形式存储在HDFS上
系统架构
系统架构细化如下:
也可以细化如下:
- Client
Client 包含访问HBase的接口
维护cache加快对HBase的访问
- Zookeeper
保证集群中只有一个HMaser;
监控HRegion Server的状态,及时将上线下线的HRegion Server信息通知HMaster;
记录所有HRegion的寻址入口;
存储Schema信息,包括有哪些表,表有哪些column family
- HMaster
为
HRegion 分配HRegion Server;
负责
HRegion
Server的负载均衡;
发现失效的HRegion Serve,并重新分配其上的Region;
GSF上的垃圾文件回收;
处理Schema的更新处理请求
- Region Server
处理region的IO请求
对到达阈值的HRegion进行分裂
所以Client访问HBase的数据不需要HMaster的参与。从Zookeeper中寻址,然后到HRegion Server上进行读写操作。
HRegion Server上线
HMaster通过Zookeeper来追踪HRegion Server的状态。
HRegion Server 上线时,首先在Zookeeper的server目录中创建自己的文件,并取得文件的独占锁。
由于HMaser订阅了server目录,当目录下有文件增加或者删除时,HMaster能收到来自Zookeeper的实时通知,因此当HRegion Server上线时HMaster能马上得到消息。
HRegion Server下线
HRegion server下线时,它断掉了Zookeeper的通讯,Zookeeper便会释放代表server的文件的独占锁。
HMaster轮询Zookeeper server目录下文件的独占锁。 当HMaster发现某个Region server丢失了自己的独占锁(或者HMaster与HRegion server连续几次通讯都不成功), HMaster将尝试获取该文件的读写锁,一旦获取成功,说明
- 该HRegion server与Zookeeper通讯已经断开
- 该HResion server挂了
无论哪种情况,HMaster将删除Server目录下代表该server的文件,并将该server的所有region,并将其分配给其他或者的server。
如果HRegion server因为临时网络断开丢失了锁,并很快恢复与Zookeeper的通讯,只要代表其的文件没有被删除,它会继续尝试或许该文件的锁,一旦获取成功,它就可以接着服务
HRegion serve
Region 分配
HMaster负责为Region 分配Region Server,一个Region 只能分配给一个Region server。 HMaster中 记录:
- 哪些Region 已经分配到哪些Region Server中
- 哪些Region server 可用
- 哪些Region 尚未分配
当HMaster发现有尚未分配的Region,并有Region server可用时,会向改server发送请求,server收到请求后对改region提供服务。
Region 定位
Region的name:
<表名,startRowkey,创建时间>, 如:quote_data,3,1473384408919
(因此一个region只能记录一个表?一个表可以有多个 region,但是一个region只能记录一个表的数据???)
(1)0.94- 版本
之前讲到,Zookeeper中记录了所有Region的寻址入口,此处说的是入口,不是真正的Region地址。真正的地址存放在.META.表中
HBASE中有两张特殊的表:.META. 和-ROOT-表,这两张表跟HBase其它表在访问上没有任何区别,只是他们记录了HBase中的系统信息。Region分配到那个Region Server是随机的,因此需要一种机制对Region进行定位。
- .META.表
用户表的所有Region信息记录在.META.表中,表中的一条记录对应一条region的详细信息,包括server的具体地址等:
--Rowkey:Region的name,其中包含了表名等信息
--Column Family:info, 包含了如下三列:regioninfo,server和serverstartcode。 其中
regioninfo包含了 NAME, STARTKEY, ENDKEY 等信息。
- -ROOT-表
当用户表非常大的时候,.META.的region也会不断增加,HBase引入了第二张特殊表-ROOT-,用来记录.META.的Region信息。-ROOT-表的结构与.META.的结构一样。
由于只有一个region,regioninfo字段中的开始字段startkey和结束字段endkey都为空。根据region的命名规则,知道-ROOT-中记录的都是。META.表的信息,所以从上图可以看到-ROOT-的rowkey类似于.META.,,1,只是它的rowkey里没有时间戳,而直接是一个数字。
等等,如果-ROOT-表太大了,要被分成多个Region怎么办?HBase认为-ROOT-表不会大到那个程度,因此-ROOT-只会有一个Region,这个Region的信息也是被存在HBase内部的,具体是存放在Zookeeper中
/hbase/rs下的,因为-Root-表的Region只有一个,所以不存在寻址问题,直接记录在Zookeeper中,寻址过程如图所示:
可以将-ROOT-表看成是简表,.META.表看成是详表:
这就是HBase的三级定位寻址法(最多三次,如果已经在Memstore中就不需要再访问这么多次了)
(2)0.96+版本
hbase0.96版本后删除了root 表,因为觉的目的是根据root表获取meta地址,过程是通过zookeeper获取root表地址,再根据root表记录meta表地址进行访问,还不如和zookeeper通讯一次。新增了namespace,详细见patch设计。
同时将.META.表重命名为:hbase:meta (放在名为hbase的表空间下), 在hbase:meta表中的column family info中增加了一列:
seqnumDuringOpen. 而且rowkey(region 的name )重新定义如下:
<表名,startRowkey,创建时间时间戳+"."+encode值+"."> (旧版的不包含encoded值)
如下为hbase:meta表的一条记录:rowkey=iqm:instrument_common_index,66666660,1474393055082.adcf19159f1116c6e1e194b3d10a7c79., 该记录的encoded值为:
adcf19159f1116c6e1e194b3d10a7c79
- startKey,region的开始key,第一个region的startKey是空字符串;
- endKey,region的结束key,最后一个region的endKey是空字符串;
- encode值,该值会作为hdfs文件系统的一个目录,假设encode值为: da1aec29c13725e29786e920bcc2d7b0 ,存放如下如图:
- 用来存放region的文件夹的名字是region name的哈希值,因为region的name中有startkey,所以可能含有非法字符,所以取它的hash值来作为目录名称存放region文件。
改造后的寻址示意图如下:
HRegion命名的相关知识背景:
HRegion是按照表名+开始/结束主键,即表名+主键范围来区分的。由于主键范围是连续的,所以一般用开始主键就可以表示相应的HRegion了。
不过,因为我们有合并和分隔操作,此时,如果正好在执行这些操作的过程中出现死机,那么就可能存在多份表名和开始主键相同的数据,这样的话,只有光靠开始主键就不够了,这就需要通过HBase的元数据信息来区分哪一份才是正确的数据文件。
为此,为了区分这样的情况,每个HRegion都有一个‘regionId‘来标识它的唯一性。所以一个HRegion的表达符,最终是:表名+开始主键+唯一Id,即tablename+startkey+regionId。
用户表的region名中regionId使用时间戳标识的,.META.表的region名的regionId是直接用数字标记的。
HRegion Sever和HMaster上下线(http://blog.csdn.net/gaijianwei/article/details/46271011)
读写过程
- 写入
首先在HLog中记录日志,然后写入到MemStore中,直接返回成功,不需要等待写入HDFS的结果,所以速度很快。
MemStore中的记录达到一定阈值时,会创建一个新的MemStore,并将旧的MemStore添加到Flush队列,有专门的线程负责Flush到StoreFile中去,同时在Zookeeper中记录redo point,表明这之前的记录都已经持久化过
写入到StoreFile中的文件只能写入,不能修改(由HDFS的特性决定的), 因此数据修改的过程是不断创建Storefile的过程,因此对应于同一记录,可能有很多历史版本,很多可能是垃圾数据。当Storefile个数到一定阈值时,系统会进行合并,将同一记录的垃圾数据清理掉。 当合并的文件大小超过一定阈值时,进行分裂,防止文件过大。
系统崩溃时,系统会根据redo point /check point? 和HLog中的记录来恢复MemStore中丢失的数据
- 读出
读出的数据是MemStore和Storefile中的数据的总和。 由于是按照Rowkey排序的,所以合并也很快。而且真正的合并是索引的合并,所以很快
分裂
压缩
压缩
参考文献:
以上是关于HBase原理的主要内容,如果未能解决你的问题,请参考以下文章