Xpath的使用
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Xpath的使用相关的知识,希望对你有一定的参考价值。
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
XPath 包含一个标准函数库。
XPath 是一个 W3C 标准。
语法简介:
http://www.runoob.com/xpath/xpath-syntax.html
节点介绍:
父节点/子节点/同胞节点/先辈节点/后代节点
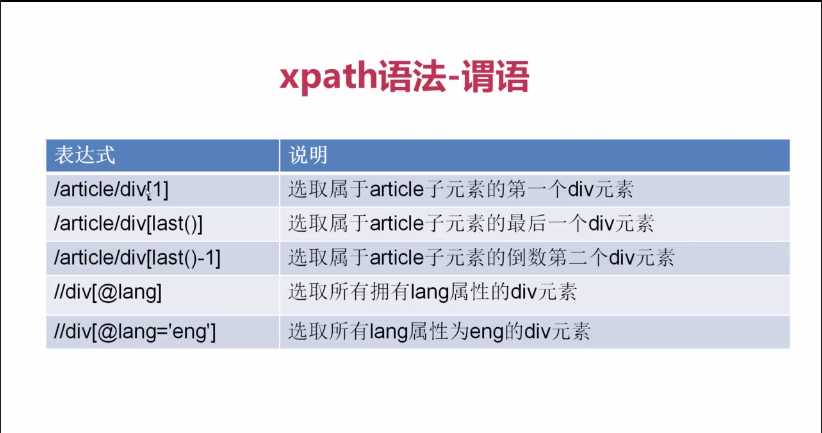
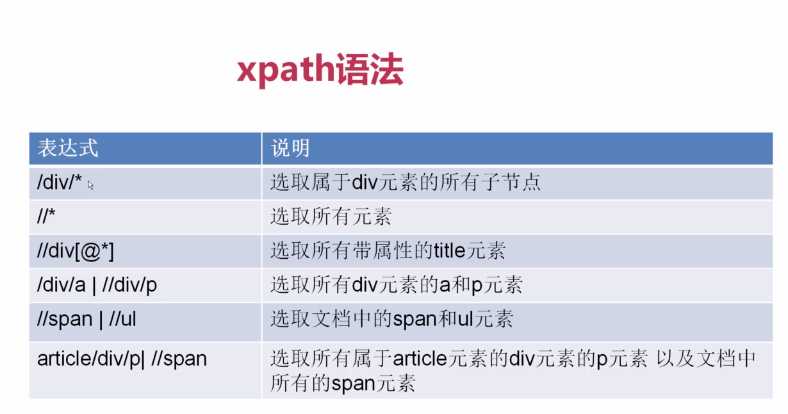
语法:
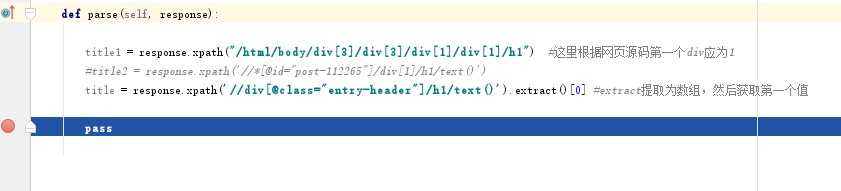
提取title
#这里注意修改start_urls def parse(self, response): title1 = response.xpath("/html/body/div[3]/div[3]/div[1]/div[1]/h1") #这里根据网页源码第一个div应为1 #title2 = response.xpath(‘//*[@id="post-112265"]/div[1]/h1/text()‘) title = response.xpath(‘//div[@class="entry-header"]/h1/text()‘).extract()[0] #extract提取为数组,然后获取第一个值
断点调试与scrapy shell
提取时间
date = response.xpath("//p[@class=‘entry-meta-hide-on-mobile‘]/text()").extract()[0].strip().replace("·","") #strip()去换行,空格
提取点赞数
#提取不到值 praise_num = response.xpath("//span[@class=‘vote-post-up‘]") #引出contains函数并向下取一层h10标签,输出数组第一个值 praise_num = response.xpath("//span[contains(@class,‘vote-post-up‘)]/h10/text()").extract()[0]
提取正文内容
#获取属性为entry的标签内容 content = response.xpath("//div[@class=‘entry‘]").extract()[0]
以上是关于Xpath的使用的主要内容,如果未能解决你的问题,请参考以下文章