全文索引Sphinx+binlog日志+Grant用户授权+读写分离和主从复制
Posted 培训机构笔记整理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了全文索引Sphinx+binlog日志+Grant用户授权+读写分离和主从复制相关的知识,希望对你有一定的参考价值。
一.全文索引Sphinx
1.什么是Sphinx
Sphinx是由俄罗斯人Andrew Aksyonoff开发的一个全文检索引擎。它是基于C语言开发出来的.中文翻译为斯芬克司斯芬克司.
Sphinx最好的应用操作系统是Linux
2.Sphinx的优势
Sphinx是一个基于SQL的全文检索引擎,可以结合mysql,PostgreSQL做全文搜索,它可以提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索。Sphinx特别为一些脚本语言设计搜索API接口,如php,Python,Perl,Ruby等,同时为MySQL也设计了一个存储引擎插件。
Sphinx 单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Sphinx创建索引的速度为:创建100万条记录的索引只需 3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
3.Sphinx的主要特性
高速索引 (在新款CPU上,近10 MB/秒);
高速搜索 (2-4G的文本量中平均查询速度不到0.1秒);
高可用性 (单CPU上最大可支持100 GB的文本,100M文档);
提供良好的相关性排名
支持分布式搜索;
提供文档摘要生成;
提供从MySQL内部的插件式存储引擎上搜索
支持布尔,短语, 和近义词查询;
支持每个文档多个全文检索域(默认最大32个);
支持每个文档多属性;
支持断词;
支持单字节编码与UTF-8编码;
4.Sphinx必须的编译工具gcc
由于安装sphinx必须要使用到gcc等编译工具,因此无论你是否已经有安装,为了保证准确性,都应该执行以下安装
yum -y install make gcc g++ gcc-c++ libtool autoconf automake imake mysql-devel libxml2-devel expat-devel
Sphinx分词技术:是一种C语言的算法技术.
比如说: 海南三亚国际大酒店
海南 海南三亚 海南酒店 海南国际
三亚 三亚国际 三亚酒店
国际 国际酒店 大酒店 国际酒
大酒店
算法比我们人工拆分的能力更强,速度更快,搜索更精准
5.安装Sphinx的源码包的步骤
第1步:Sphinx源码包的说明

第2步:Sphinx的源码安装包规定上传到/usr/local/src
这个目录在Linux操作系统是专门用于放置第3方软件包或者脚本的,所以如果Sphinx不在该目录下,那么你编译就会失败,使用ftp工具进行上传.

第3步:把install_sphinx.sh修改为777的权限

第4步:执行安装的脚本文件./install_sphinx.sh

在安装过程中出现警告信息我们全部都可以忽略,如果出现error就只能重新恢复快照进行编译了.回车就会进行编译执行,出现以下界面代表sphinx安装成功:

6.Sphinx的重要文件
sphinx的配置文件路径
/usr/local/sphinx/etc/sphinx.conf
sphinx的客户端命令工具
/usr/local/sphinx/bin
sphinx的示例数据库脚本
/usr/local/sphinx/etc/example.sql
7.导入Sphinx的测试示例库到test数据库中
语法命令: mysql -u登录名 -p登录密码 test < /usr/local/sphinx/etc/example.sql
这时使用命令把sphinx的sphinx的示例数据库脚本进行导入,执行命令如下:
mysql -uroot -p123456 test < /usr/local/sphinx/etc/example.sql
效果如下:
导入完成,在test数据可以下documents表如下图所示

使用select * from documents获取以下数据,发现这些测试数据全部是英文:

所以我们需要额外加上一些中文的测试数据在里面,方便我们学习和测试,中文的数据建议插入如下这几条:

执行结果如下:

8.配置Sphinx的数据源
sphinx的配置文件路径
/usr/local/sphinx/etc/sphinx.conf
使用vim打开配置文件

内容如下所示:


理解以上的几项之后,我们就可以对test数据库的documents表进行数据源的配置了,修改内容如下:

保存并退出(:x),sphinx如果没有链接php之前不需要做任何重启工作
9.Sphinx的生成索引工具./indexer
sphinx的客户端命令工具在该目录下:/usr/local/sphinx/bin
而生成索引工具indexer是属于sphinx的客户端命令工具
语法规则如下:./indexer [--all][--rotate]
--all 选项:
这个选项用于生成数据源中所有数据索引,这个选项是必须填写的选项
--rotate选项:
这个选项用于生成连接php的增量索引api,如果sphinx和php进行绑定操作,那么我们就需要使用这个选项,如果sphinx只是单独操作,我们不需要使用该选项
注意:这个工具必须在/usr/local/sphinx/bin目录下执行,否则这个工具是没法成功建立全文索引的
使用sphinx的./indexer工具生成test数据库下的documents表中的所有数据的全文索引,执行的命令代码如下,注意目录一定要/usr/local/sphinx/bin下完成:
命令:./indexer --all
由于我们配置的sphinx数据源本身就是test数据库的documents表,所以该命令就会自动去这张表中把数据进行全文索引,执行效果如下:

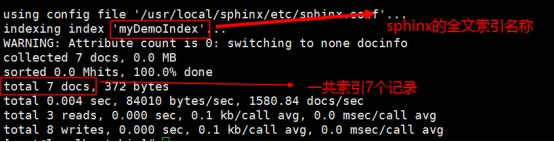
上图的出现就是代表sphinx建立全文所以成功了
10.搜索索引工具./search
sphinx的客户端命令工具在该目录下:/usr/local/sphinx/bin
而生成索引工具search是属于sphinx的客户端命令工具
语法规则如下:./search 搜索关键字
1)如果希望搜索documents表中含有four关键字的数据,那么执行以下命令就可以搜索
命令:./search four
执行效果如下:

2)如果希望搜索documents表中含有itcast关键字的数据,那么执行以下命令就可以搜索
命令:./search itcast
执行效果如下:

这时如果你细心观察可以知道,当前我们进行搜索的关键字全部都是英文的,如果你希望搜索关键字为中文会出现怎么样的结果呢??
2)如果希望搜索documents表中含有广州关键字的数据,那么执行以下命令就可以搜索
命令:./search 广州
执行效果如下:

这时如果使用sphinx搜索中文,你会发觉无法搜索出对应的内容,这个其实原因我们还灭有为sphinx打入中文词库,所以如果希望解决这个问题那么我们就需要打入coreseek中文词库,其作者是高春辉。
二.中文分词库CoreSeek
1.coreseek的简介
Coreseek为应用提供全文检索功能,目前的版本(2.x 3.x)基于Sphinx 0.9.8,支持使用Python定义数据源,支持中文分词。
2.安装Coreseek
第一步:包说明

第2步:上传文件到/usr/local/src下

第3步:修改install_coreseek.sh权限为777
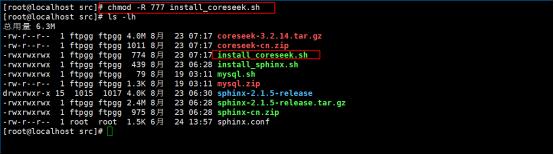
第4步:执行./install_coreseek.sh进行安装,安装成功结果如下图所示:

3.Coreseek的重要文件
Coreseek的配置文件
/usr/local/coreseek/etc/csft.conf
Coreseek的命令工具
/usr/local/coreseek/bin
4.配置Coreseek的数据源
Coreseek的配置文件
/usr/local/coreseek/etc/csft.conf
使用vim打开

配置如下图所示:

5.测试coreseek
Coreseek它有自己命令行工具,跟sphinx的命令工具是一致,但如果你想搜索是中文,那么必须使用coreseek命令行工具
Coreseek的命令工具在以下目录当中,如果希望执行indexer和search都必须在该目录中完成,否则就会失败
/usr/local/coreseek/bin
测试中文搜索的结果如下:
如果希望搜索documents表中含有广州关键字的数据,那么执行以下命令就可以搜索
详细步骤如下:
①必须使用coreseek的indexer重新生成一次中文分词的全文索引,执行命令如下
./indexer --all ,该命令必须在/usr/local/coreseek/bin执行,否则就会失败.效果如下所示

②使用命令:./search 广州
看下是否可以中文检索出documents当中的内容
执行效果如下:
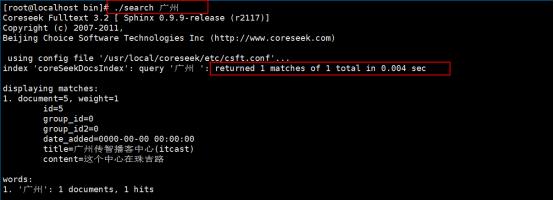
测试英文结果如下,尝试使用coreseek来全文索引documents当中的itheima关键字,结果如下:

因此我们可知如果我们做sphinx的开发其实,我们使用的就coreseek,因为我们中国人很少使用原生sphinx,然而我们刚才的所有操作都发生在命令行客户端,如果我们要使用php操作coreseek可以吗?如果希望用php操作coreseek那么我们就需要做两件事:
1)安装php的sphinx拓展
2)启动coreseek的9312端口
三.Sphinx的PHPAPI(扩展库)
1.安装sphinx的php扩展库
第1步:包说明

第2步:上传文件到/usr/local/src

上传结果如下:

第3步:修改install_php_coreseek.sh的权限为7777

修改后的结果:

第4步:执行./install_php_coreseek.sh进行安装

成功安装,界面如下图所示:

第5步:重启apache服务器
执行命令:service httpd restart

接下来在/var/www/html编写phpinfo.php脚本内容如下:

保存并退出,然后在浏览器种看phpinfo,phpinfo测试结果如下

代表sphinx扩展安装成功了
注意:必须关闭selinux的配置选项,否则php无法链接sphinx扩展,修改方法如下:
使用vim /etc/selinux/config

打开后修改内容如下:

修改完成后必须使用reboot命令,重启linux服务器selinux才能正常关闭,这个关闭是永久性的,就算你关闭selinux你会发觉php依然无法链接sphinx的中文词库coreseek,原因是如果你希望搜索中文的coreseek词库,必须要在linux当中建立coreseek服务器端服务器进程,而进程需要你开启9312端口,否则无法使用。开启的方法很简单,使用coreseek的命令工具./searchd就可以开启,如下所示:
2.开启coreseek的9312端口
Coreseek的命令工具在以下目录当中,如果希望执行searchd都必须在/usr/local/coreseek/bin目录中完成,否则就会失败
执行命令如下:./searchd

3.Linux查看端口和杀死进程的方法(拓展)
查看9312端口的方法: netstat -tunlp | grep 【端口名称|进程名称】
如果希望查看80端口是否被apache占有那么可以使用以下方法:

杀死进程的方法: pkill 进程名
如果希望杀死9312端口,那么我们就需要杀死searchd服务进程


如果希望确定是否杀死进程,那么需要重新查看9312端口的占用情况:

四.使用php操作sphinx
0.两个很实用php函数(array_keys和join)
代码详细参考:php/arr_join.php,上传到/var/www/html下进行测试

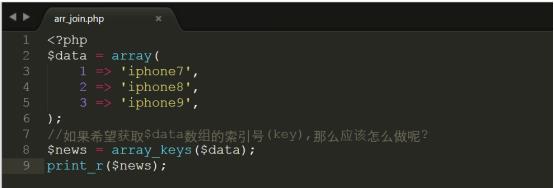
执行结果如下:

如果我希望当前返回的数组形式变成字符串的格式为“1,2,3”我们应该怎么样才能做到?
implode(替代函数join),搜索php的手册发现implode有个别名叫join

使用join去替代implode会使得代码更为直观,代码如下:

执行结果如下:

1.使用php连接sphinx(coreseek的9312端口)
代码详细参考:php/coreseek.php,上传到/var/www/html下进行测试

执行结果如下:

2.php的多种搜索sphinx的模式
SPH_MATCH_ANY 最精准的匹配模式,匹配查询词中的任意一个(重点)
SPH_MATCH_PHRASE 将整个查询看作一个词组,要求按顺序完整匹配(了解)
SPH_MATCH_BOOLEAN 使用布尔搜索模式(了解)
SPH_MATCH_EXTENDED 兼容模式,主要是为兼容php5.2(了解)
SPH_MATCH_ALL 匹配所有查询词(默认模式)(了解)
3.SPH_MATCH_ANY模式
代码详细参考:php/setMatchMode.php,上传到/var/www/html下进行测试
如果希望使用sphinx的coreseek进行全文索引那么建议使用SPH_MATCH_ANY的模式去精准搜索,但是我们该如何设置这精准模式呢?答案是使用sphinx的setMatchMode方法,方法简介如下:
模式有很多,但我们只会使用SPH_MATCH_ANY
代码编写如下所示:

执行效果如下:

然而如果你只是设置模式,但你不去使用模式搜索,那么设置模式有什么用呢?因此我们就需要通过设定的模式去查找数据,那么又该如何查找数据呢?答案是通过使用sphinx的query方法,query方法简介如下 :

参数$query:搜索关键字
参数$index:搜索coreseek搜索名称,默认是coreseekDocsIndex
参数$comment : 备注信息,一般我们不会使用
返回值是array数组形式
编写代码如下:

执行结果如下所示:

然而这个主键的id是matches这个数组的键名,那么我们应该如何获取matches数组的键名呢?答案使用array_keys函数,因此我们需要把代码修改称以下形式,获取matches数组的键名:

执行结果如下:
但是我们只是获取了数据库当中的主键,那么如何把主键转换成为数据库当中具体的记录信息呢?这时我们就需要使用pdo来进行预处理操作了,因为主键是数据库当中最具效率的索引因此通过主键来查找数据速度是很快的,pdo就是出场的时候了.
4.使用pdo操作sphinx的matches选项id
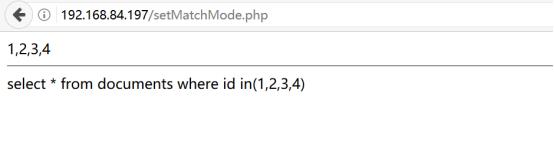
代码详细参考:php/pdoSphinx.php,上传到/var/www/html下进行测试
需要组合sql的in语句使用join函数转化ids数组变量

执行结果如下所示:

虽然我们能够使用pdo操作sphinx中的matches的id选项,然而我们是把关键字写死了,并且关键字该如何高亮显示呢?这时我们就需要进一步修改代码,并且要增加一个搜索的页面叫(index.html)和高亮显示的方法buildExcerpts
5.高亮显示sphinx的搜索关键字
代码详细参考:php/build.php,上传到/var/www/html下进行测试
Sphinx的高亮方法buildExcerpts简介如下:

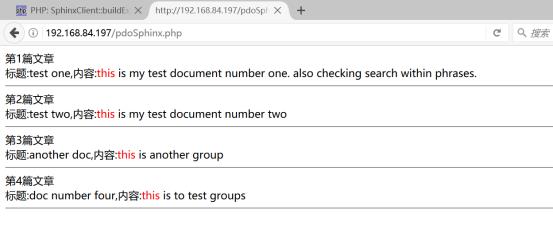
编写代码如下:

执行后,查看源代码如下:
如果我们希望修改keyswords的传值,那么我们就需要增加一个叫做index.html的页面,页面的代码如下,在index.html当中查看,是一个非常简单的搜索框样式:

把action修改为pdoSphinx.php,因此在pdoSphinx.php接收keywords的get传值参数,代码修改如下:

重新上传index.html和pdoSphinx.php文件进行测试,如下:

6.php操作sphinx的增量索引
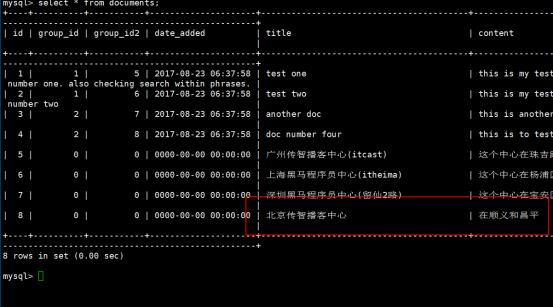
如果现在在数据库当中在插入一条信息的数据,如下:
原因就是php如果需要获取coreseek当中的全文索引,必须要使用增量索引,是方法如下,这些必须在/usr/local/coreseek/bin目录下进行:
直接使用./indexer --all就会出现错误

我们应该使用./indexer --all --rotate让php可以操作sphinx增量索引api,结果如下:
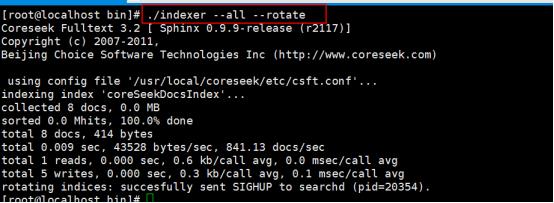
执行结果如下,发现再次成功

那么在pdoSphinx.php页面中机会出现所有与中心关键字相关的记录:
7.crontab命令定时更新sphinx增量索引api(拓展)
crontab命令其实是linux当中定时器,最早用于军事,所以这个命令不是什么新的技术
其格式如下:

crontab常用使用方法如下:
编辑命令 crontab -e
查看命令 crontab -l
格式: * * * * * [命令的详细路径]
需求:如果需要每1分更新一次sphinx的增量索引api那么我们应该怎么做呢?详细步骤如下:
使用crontab -e命令进入crontab的编辑模式,编写以下内容:

保存并退出(:x),就会1分钟定时执行一次,而且linux是非常听话和稳定的执行。
我们执行只是为了学习方便看到效果,所以我们使用1分钟,建议在实际网站开发中定义15分钟更新一次增量索引api
*/15 * * * * /usr/local/coreseek/bin/indexer --all --rotate
如果使用crontab -l就可以查看crontab的执行情况


一般定时命令不会影响cpu,所以一般工程师不会经常删除,如果你真要删除就使用crontab -e命令编辑这个命令为空即可
5.使用union all优化in语句

优化手段来自此书的in性能优化对比.
在mysql的当中如果使用in语句只有一种情况可以使用到索引,就是当mysql数据库认为当前的检索为一个范围时,就可以使用索引,如下图所示:


其他的in语句情况如果不是一个范围的检索,那么mysql就认为它等同于or条件的集合,这时他们发生的性能问题全部属于全表扫描ALL

所以不建议使用in语句在查询大数据量,建议使用union all取代in,union all使用explain执行计划查看会带来一个ALL的性能选项,如下图所示:

但要要注意的时这个ALL检索的数据是union all合并后的结果而非全表扫描,这时性能远远优于全表扫描,虽然我们知道可以使用union all来代替in语句,那么这时我们在sphinx当中应该如何组合这条语句呢,修改代码如下:
详细代码参考:code/pdoSphinx2.php

五.MySql数据中的binlog日志
binlog日志的简介
问:在现实开发当中,网站每天运行其实都会发生很多操作,但假设数据库发生了更改(delete,insert,update,alter语句的发生),我们想实时捕捉这些语句什么时候发生,那么应该怎么做呢?
答:在MySql当中有一种日志叫binlog,该日志是记录对数据发生或潜在发生更改的SQL语句,并以二进制的形式保存在磁盘中,该日志对数据获取(select)不起作用。binlog日志其实主要用于主从复制,所以如果你需要配置主从复制和读写分离,那么就必须学会binlog日志相关函数(命令)
六.binlog日志的相关函数
之前我们学过的MySql的慢查询日志有一些专门管理慢查询日志的函数(命令),那么binlog同样属于MySql当中的一种日志类型,那么MySql有专门管理binlog日志的函数(命令)吗?这个答案是肯定的。
①在MySql当中查看binlog日志的是否已经开启
使用命令: show variables like \'log_bin\'
执行命令结果如下:

在默认的情况下MySql一般不会开启binlog日志,所以该选项为OFF(代表binlog日志没有开启),如果希望开启binlog日志就需要把该选项设置为ON,那么如何才能把该选项设置为ON呢?这时就必须又要去修改mysql的配置文件了,mysql的配置文件路径(/etc/my.cnf)
②在配置文件(/etc/my.cnf)中开启binlog日志的详细步骤
使用vim打开/etc/my.cnf配置文件,内容如下所示:

找到如下配置:

修改binlog日志如下:
该选项必须写成binlog,保存并退出(:x),这时我们还需重启mysqld服务
使用命令: service mysqld restart

重启完成后,binlong日志就打开:

你会发现在/var/lib/mysql下多了2个这样的文件:

我们只需要关系binglog.000001文件即可
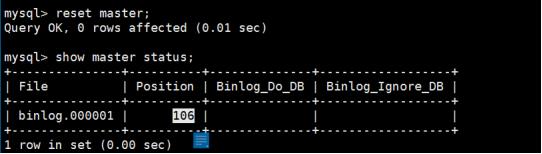
③查看binlog日志的当前情况
使用命令:show master status

选项详解:
File:表示当前正在使用的binlog日志文件是哪个,该文件存放在/var/lib/mysql目录中
Position:当前binlog日志操作的步伐,这个选项主要是在主从同步的时候拿来做参考
Binlog_Do_DB:当前正在做binlog主从复制的数据库是哪一个,如果为空代表当前并没有开启binlog主从复制的数据库
Binlog_Ignore_DB:该选项的作用跟Binlog_Do_DB一样,但这个选项向来都不知道意义何在,一般没人使用.
这时如果我们使用查询语句binlog会有变化吗?是不会改变的,然而如果做了写操作(更新)它的postion就会发生改变:


如果使用vim查看binlog日志文件中的内容,发觉是乱码,无法查看其内容,如下所示:

④查看binlog日志的二进制内容
使用命令: mysqlbinlog [binlog文件路径] | less

执行效果如下:

binlog日志开启后,能够实时捕捉你的更新操作(写操作)
难道每一次都只使用一个binlog文件吗?如果我们操作很多,一个文件就会逐渐变大,因此binlog其实有一系列的管理文件供开发者操作.
⑤保留旧的binlog日志文件,创建新的binlog日志文件
使用命令:flush logs

flush logs命令可以保存当前binlog.00001文件并且创建一个新的binlog文件来使用
只要你flush logs就会产生一个新的文件,不会删除任何旧的文件:

④删除所有的binlong日志文件,让binlog日志从头开始
使用命令:reset master
执行命令如下:
发觉旧文件被删除,而创建了一个从头开始binlog日志文件.
注意:如果希望删除binlog日志文件让binlong文件从00001开始是不能使用rm命令,否则问题很严重,会导致数据库错乱

总结:其实binlog除了记录更新操作之外,那么我们在现实开发当中拿binlog干嘛呢?我们说一般我们是使用binlog来做主从同步(读写分离),也叫主从复制.
七.Grant用户授权
1.MySql的Grant用户授权简介和服务器的克隆
在MySql当中默认存在一个安全的机制,即本地访问机制(localhost)。假设你想在本地以外访问MySql就需要通过Grant授权一个用户和IP地址。为了方便学习,我们可以通过克隆一台新的Linux服务器来进行Grant用户授权测试,详细的克隆服务器建立步骤如下所示:
第1步:要克隆必须先关机.

第2步:打开虚拟机找你要克隆的服务器(Master),右键选择管理->克隆

第3,4步:默认操作下一步

第5步:选择完整克隆然后下一步,在克隆过程当中有可能会死机,速度根据计算机的设备配置而定,耐心等待

第6步:设置克隆服务器的名称和存放的路径

点击完成后耐心等待:

等待完成后就关闭

出现slave虚拟机就代表克隆成功

注意:这时千万不要启动slave服务器,否则会很奇葩,现在只能启动master服务器
2.Grant用户授权的设置
这个技术主要也是拿来做主从复制为主的
这时Grant用户授权必须发生在Master服务器当中,并且保证Slave服务器在设置完成才能开启,否则话可能会有意想不到的bug产生.
语法规则:
GRANT ALL PRIVILEGES ON *.* TO 授权用户名@被授权服务器的IP IDENTIFIED BY \'授权密码\';
FLUSH PRIVILEGES;
设置Grant用户授权的详细步骤如下:
第1步:进入Master服务器的mysql数据库当中

第2步:开启slave服务器,并且确定slave服务器的ip地址,然而slave不能做任何的ip调整和修改,因为它是一个克隆品,遗传Master的网卡配置信息.(这个过程如果你电脑比较一般,整个系统会卡爆),通过ifconfig获取slave服务器的ip如下(192.168.84.82):

第3步:在master服务器当中进行Grant用户授权,执行以下命令配置:
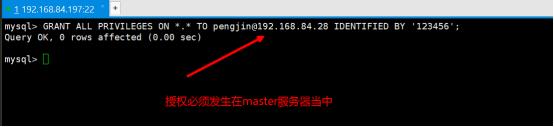
这样就对slave服务器进行了一个名为pengjin的Grant用户授权,其授权密码为123456
执行完成后,我们还需刷新授权

如果不出现任何的错误就代表grant授权成功了我们需要在Slave服务器当中进行测试
第4步:在slave服务器当中通过以下命令对grant用户授权进行测试:
mysql -u授权的用户名 -p授权的密码 -h master服务器的ip
执行命令如下:

测试结果如下:

证明了master的Grant用户授权给Slave服务器成功
3.查看Grant用户授权结果
由于mysql本身有一个系统数据库叫mysql数据库,所以当我们完成了授权后,
可以通过以下命令查看授权的结果,该命令要在master服务器中执行:
select host,user,password from mysql.user where user=’授权用户的名称’;


注意:Grant用户授权主要是为设置读写分离和主从复制,而Grant授权的测试结果不是所谓主从复制,因为其实在Slave服务器当中连接的数据库是Master而不是自己本身的数据库.
八.读写分离和主从复制
MySQL主从复制(Master-Slave)与读写分离可以说是数据库当中重要的环节,也是目前世界上所有大型网站当中必须拥有的优化手段.
如果你把数据库比喻成一个很优秀的人,它能够很好很优秀地完成很多不同的工作。但你有没想过再优秀的人都有体力耗尽的时候。
数据库也是一样的,无论你对这个数据库做了多少的优化工作,网站所有的数据响应工作都靠一个数据库去完成的话,其实数据库也会有扛不住过大访问量的时候,这就跟人一样。
但是我们如果我们有多个优秀的人一起协同工作那么是不是面对大工作量的时候我们的效率就会高了很多,也不会只有一个人累死累活的,数据库也是一样的如果有多于1个以上的数据库那么扛住大访问量就肯定提高效率。
然而多个数据库也是有代价成本的,因为这样话要有多台服务器,而服务器的费用是挺贵,多台服务器如果需要维护那么还需要有一个比较专业的运维技术团队,而运维技术团队里面的成员工资也是不低的,所以对于小成本的公司一般的老板是玩不起主从复制和读写分离。
那么什么是读写分离和主从复制呢,其实读写分离和主从复制是一个整体,读写分离是为了减轻数据库的压力,主从复制是为了数据库的数据进行同步.
读写分离和主从复制的架构图:

上图中,我们把负责写操作的数据库称为主数据库,该数据库所在的服务器我们称为主服务器,使用ip为192.168.1.1来表示,使用英文名就是Master,由于这台服务器只有写的过程没有读的过程,也就是只有insert,update,delete的过程没有select的过程,这时其实它要完成的工作就少了select,自然就压力就比原来小了.
我们把负责读操作的数据库称为从数据库,该数据库所在的服务器我们称为主服务器,使用ip为192.168.1.2来表示,使用英文名就是Slave,由于这台服务器只有读的过程没有写的过程,也就是只有select的过程没有insert,update,delete的过程,这时其实它要完成的工作就少了insert,update,delete,自然就压力也比原来小了.
然而读写分离之后,最大的问题就是,读和写的数据分布在两台不同的服务器中,所以如果希望两台服务器的数据是一样的那么就需要把主服务的数据同步复制一份到从服务器上,我们把这个复制的过程称为主从复制,也有人叫做主从同步.
如果你明白了读写分离和主从复制的架构之后,其实我们还需要理解一个问题就是主从复制的原理是什么?也就是说凭MySql懂得把主服务器当中写操作的数据同步复制到读数据库当中呢?其实这个答案就是主从同步的原理,其实是主服务器把自己的binlog日志同步给从服务器,因为binlog日志是记录主服务器的写操作的日志文件.因此主从复制的原理如下:
