Selenium运用-漫画批量下载
Posted Freeman耀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Selenium运用-漫画批量下载相关的知识,希望对你有一定的参考价值。
今天我们要爬去的网站是http://comic.sfacg.com/。漫画网站一般都是通过javascript和AJAX来动态加载漫画的,这也就意味着想通过原来爬取静态网站的方式去下载漫画是不可能的,这次我们就来用Selenium&PhantomJS来下载漫画。
分析:我们通过Selenium模拟打开漫画网站,找到每一章每一页漫画图片地址,按章节目录分类,下载图片。
下面我们随便打开一个漫画如下
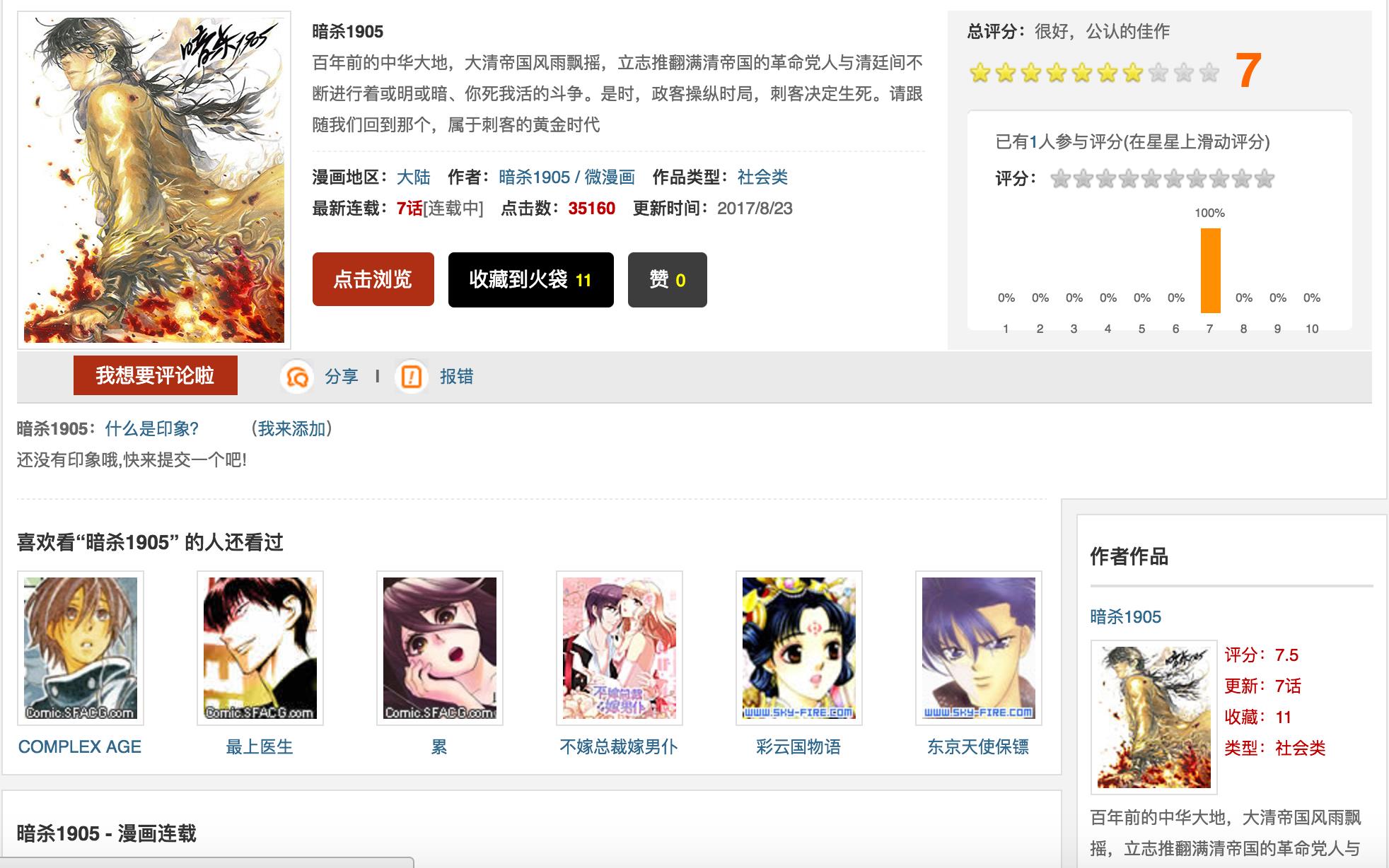
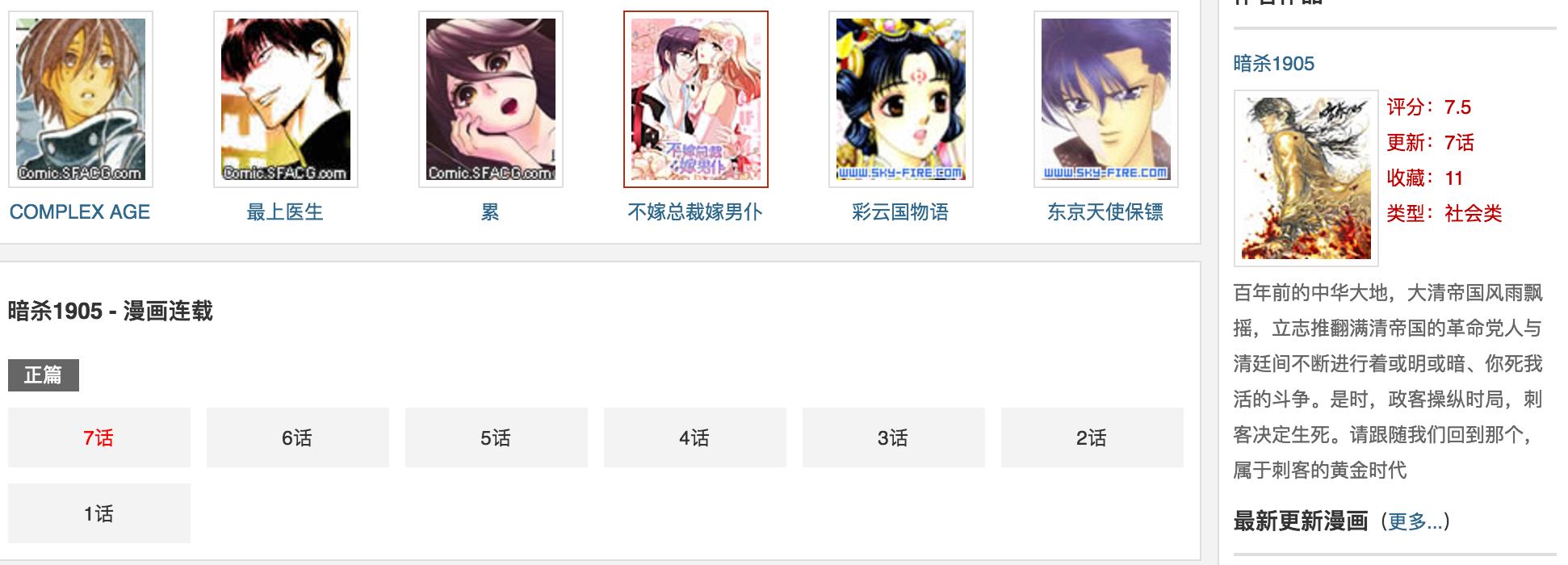
使用谷歌浏览器检查一下发现每一个章节都在下面标签里,这样我们很容易获取到每一章节地址了。
<div class="serialise_list Blue_link2">
下面进入代码编写过程:
首先创建目录和图片保存
1 def mkdir(path): 2 \'\'\' 3 防止目录存在 4 :param path: 5 :return: 6 \'\'\' 7 if not os.path.exists(path): 8 os.mkdir(path) 9 10 11 def SavePic(filename,url): 12 \'\'\' 13 图片的保存 14 :param filename: 15 :param url: 16 :return: 17 \'\'\' 18 content = requests.get(url).content 19 with open(filename,\'wb\') as f: 20 f.write(content)
获取每一章节的链接保存到字典里
1 def get_TOF(index_url): 2 url_list = [] 3 browser = webdriver.PhantomJS() 4 browser.get(index_url) 5 browser.implicitly_wait(3) 6 7 title = browser.title.split(\',\')[0]#获取漫画标题 8 mkdir(title)#创建目录 9 10 comics_lists = browser.find_elements_by_class_name(\'comic_Serial_list\')#找到漫画章节 11 for part in comics_lists:#找到每一章节所在的标签信息 12 links = part.find_elements_by_tag_name(\'a\') 13 for link in links: 14 url_list.append(link.get_attribute(\'href\'))#获取每个单独章节链接 15 browser.quit() 16 Comics = {\'name\':title,\'urls\':url_list} 17 return Comics
下面是代码的核心部分,通过selenium打开漫画找到漫画的地址,下载漫画图片,找到漫画中下一页按钮,点击并获取下一页图片,循环这个过程。当循环到最后一页到时候,仍然有下一页到按钮,因此需要计算一下漫画有多少页。
1 def get_pic(Comics): 2 comic_list = Comics[\'urls\'] 3 basedir = Comics[\'name\'] 4 5 browser = webdriver.PhantomJS() 6 for url in comic_list: 7 browser.get(url) 8 browser.implicitly_wait(3) 9 dirname = basedir+\'/\'+browser.title.split(\'-\')[1] 10 mkdir(dirname) 11 #找到漫画一共有多少页 12 pageNum = len(browser.find_elements_by_tag_name(\'option\')) 13 #找到下一页按钮 14 nextpage = browser.find_element_by_xpath(\'//*[@id="AD_j1"]/div/a[4]\') 15 for i in range(pageNum): 16 pic_url = browser.find_element_by_id(\'curPic\').get_attribute(\'src\') 17 filename = dirname+\'/\'+str(i)+\'.png\' 18 SavePic(filename,pic_url) 19 nextpage.click() 20 print(\'当前章节\\t{} 下载完毕\'.format(browser.title)) 21 browser.quit() 22 print(\'所有章节下载完毕!\')
下面是主函数到编写
1 if __name__ == \'__main__\': 2 url = str(input(\'请输入漫画首页地址:\\n\')) 3 Comics = get_TOF(url) 4 #print(Comics) 5 get_pic(Comics)
结果展示:
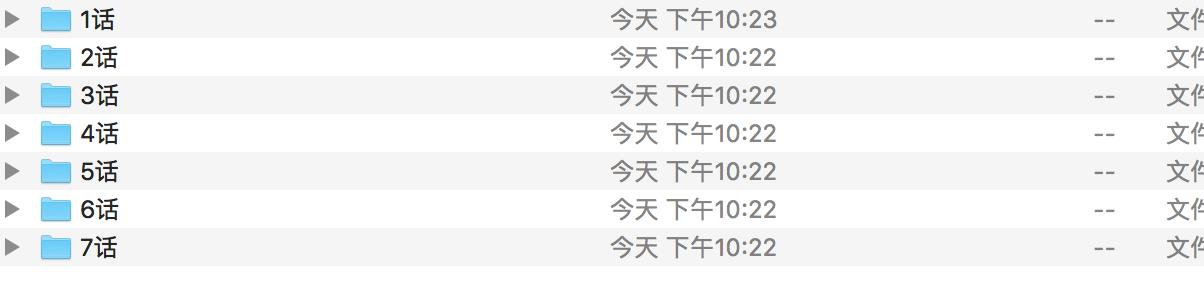
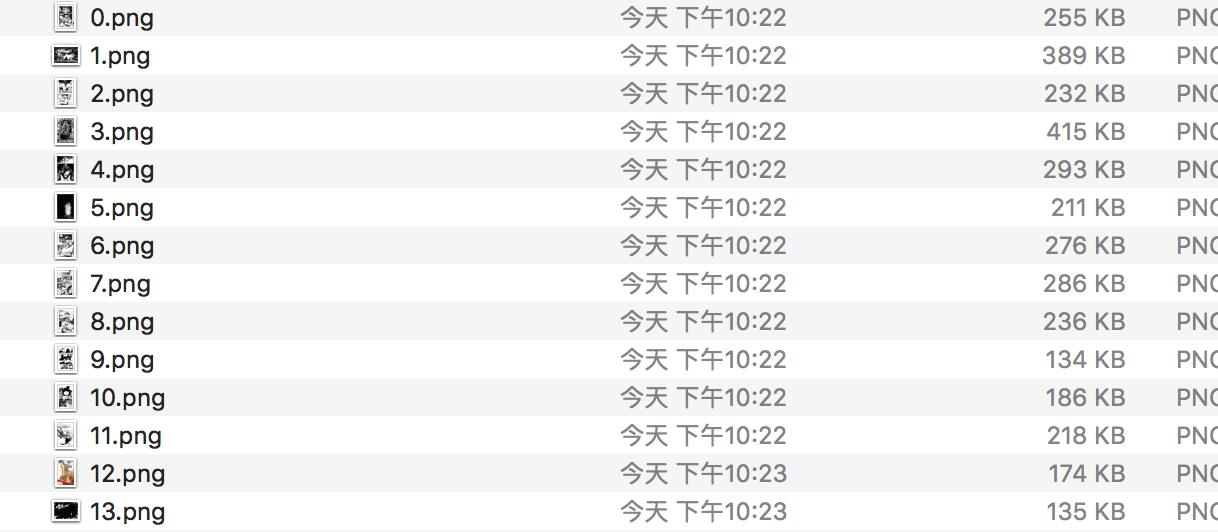
下面是1话里面到图片
 Selenium爬虫虽然能模拟浏览器加载JS动态页面,但是其速度就十分堪忧了和Scrapy库、requests更完全不能比了。
Selenium爬虫虽然能模拟浏览器加载JS动态页面,但是其速度就十分堪忧了和Scrapy库、requests更完全不能比了。
以上是关于Selenium运用-漫画批量下载的主要内容,如果未能解决你的问题,请参考以下文章