tensorflow笔记之MNIST手写识别系列一
Posted 放羊的水瓶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tensorflow笔记之MNIST手写识别系列一相关的知识,希望对你有一定的参考价值。
tensorflow笔记(四)之MNIST手写识别系列一
版权声明:本文为博主原创文章,转载请指明转载地址
http://www.cnblogs.com/fydeblog/p/7436310.html
前言
这篇博客将利用神经网络去训练MNIST数据集,通过学习到的模型去分类手写数字。
我会将本篇博客的jupyter notebook放在最后,方便你下载在线调试!推荐结合官方的tensorflow教程来看这个notebook!
1. MNIST数据集的导入
这里介绍一下MNIST,MNIST是在机器学习领域中的一个经典问题。该问题解决的是把28x28像素的灰度手写数字图片识别为相应的数字,其中数字的范围从0到9.
首先我们要导入MNIST数据集,这里需要用到一个input_data.py文件,在你安装tensorflow的examples/tutorials/MNIST目录下,如果tensorflow的目录下没有这个文件夹(一般是你的tensorflow版本不够新,1.2版本有的),还请自己导入或者更新一下tensorflow的版本,导入的方法是在tensorflow的github(https://github.com/tensorflow/tensorflow/tree/master/tensorflow )下下载examples文件夹,粘贴到tensorflow的根目录下。更新tensorflow版本的话,请在ubuntu终端下运行pip install --upgrade tensorflow就可以了
好了,我们还是一步步来进行整个过程
首先我们先导入我们需要用到的模块
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data
然后我们用input_data模块导入MNIST数据集
mnist = input_data.read_data_sets(\'MNIST_data\',one_hot = True)

上面总共下载了四个压缩文件,内容分别如下:
train-images-idx3-ubyte.gz 训练集图片 - 55000 张 训练图片, 5000 张 验证图片
train-labels-idx1-ubyte.gz 训练集图片对应的数字标签
t10k-images-idx3-ubyte.gz 测试集图片 - 10000 张 图片
t10k-labels-idx1-ubyte.gz 测试集图片对应的数字标签
图片数据将被解压成2维的tensor:[image index, pixel index] 其中每一项表示某一图片中特定像素的强度值, 范围从 [0, 255] 到 [-0.5, 0.5]。 "image index"代表数据集中图片的编号, 从0到数据集的上限值。"pixel index"代表该图片中像素点得个数, 从0到图片的像素上限值。
以train-*开头的文件中包括60000个样本,其中分割出55000个样本作为训练集,其余的5000个样本作为验证集。因为所有数据集中28x28像素的灰度图片的尺寸为784,所以训练集输出的tensor格式为[55000, 784]
执行read_data_sets()函数将会返回一个DataSet实例,其中包含了以下三个数据集。 数据集 目的 data_sets.train 55000 组 图片和标签, 用于训练。 data_sets.validation 5000 组 图片和标签, 用于迭代验证训练的准确性。 data_sets.test 10000 组 图片和标签, 用于最终测试训练的准确性。
具体的MNIST数据集的解压和重构我们可以不了解,会用这个数据集就可以了。(当然别问我这个东西,这个过程我也不知道,嘿嘿)
这里说一下上述代码中的one_hot,MNIST的标签数据是"one-hot vectors"。 一个one-hot向量除了某一位的数字是1以外其余各维度数字都是0。所以在此教程中,数字n将表示成一个只有在第n维度(从0开始)数字为1的10维向量。比如,标签0将表示成([1,0,0,0,0,0,0,0,0,0,0])。
2.实践
我们首先定义两个占位符,来表示训练数据及其相应标签数据,将会在训练部分进行feed进去
xs = tf.placeholder(tf.float32,[None,784]) # 784 = 28X28 ys = tf.placeholder(tf.float32,[None,10]) # 10 = (0~9) one_hot
现在我们再来定义神经网络的权重和偏差
Weights = tf.Variable(tf.random_normal([784,10]))
biases = tf.Variable(tf.zeros([1,10])+0.2)
先说一下,这个神经网络是输入直接映射到输出,没有隐藏层,输入是每张图像28X28的像素,也就是784,输出是10个长度的向量,也就是10,所以权重是[784,10],偏差是[1,10].
y_pre = tf.nn.softmax(tf.matmul(xs,Weights)+biases)
我们知道虽然最后的输出结果是10个长度的向量,但他们的值可能不太直观,打个比方,比如都是0.015之类的数,仅仅是打比方哈
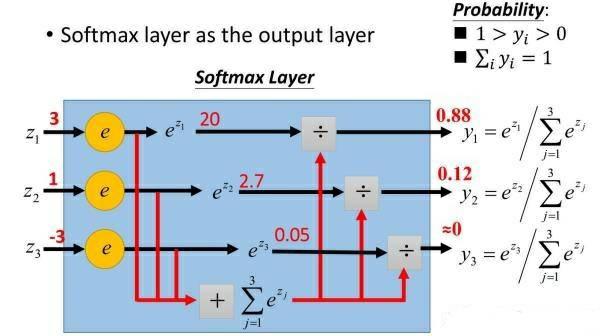
为了显示输出结果对每个数的相应概率,我们加了一个softmax函数,它的原理很简单,拿10个单位的向量[x0,x1,...,x9]为例,如果想知道数字0的概率是多少,用exp(x0)/(exp(x0)+exp(x1)+...+exp(x9)),其他数字的概率类似推导,你也可以参考我放在博客上的图片,很直观。
cross_entropy =tf.reduce_mean( -tf.reduce_sum(ys*tf.log(y_pre),reduction_indices=[1]))#compute cross_entropy
这次的损失表示形式跟之前都不太一样哈,这次是计算交叉熵,交叉熵是用来衡量我们的预测用于描述真相的有效性。我们可以想一想,以一张图片为例,y_pre和ys都是一个10个长度的向量,不同的是y_pre每个序号对应的值不为0,而ys是one_hot向量,只有一个为1,其余全为0,那么按照上述公式,只有1对应序号i(假如是i)的log(y_pre(i))保留下来了,而且y_pre(i)越大(也就是概率越大),log(y_pre(i))越小(注意计算交叉熵前面有负号的),反之越大,符合我们对损失的概念。
我试过用官方教程的交叉熵公式,打印交叉熵时出现nan,溢出了,建议用这个好一些
train = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
上面是用优化器最小化交叉熵,这里学习率的选取很重要,官方的0.01太小,收敛得慢,还没达到训练损失最小就停止了,结果就是测试集误差较大,推荐选大点,0.5左右差不多了,再大反而会发散了。
init = tf.global_variables_initializer()
上面是生出初始化init
sess = tf.Session()
建立一个会话
sess.run(init)
初始化变量
for i in xrange(1000): batch_xs,batch_ys = mnist.train.next_batch(100) sess.run(train,feed_dict={xs:batch_xs,ys:batch_ys}) if i %50==0: print sess.run(cross_entropy,feed_dict={xs:batch_xs,ys:batch_ys})

上面是程序训练过程,这里说一下xrange和range的区别,它们两个的用法基本相同,但返回的类型不同,xrange返回的是生成器,range返回的是列表,所有xrange更节省内存,推荐用xrange,python3当中已经没有xrange了,只有range,但它的功能和python2当中的xrange一样
下面我们来计算计算精度
correct_prediction = tf.equal(tf.argmax(ys,1), tf.argmax(y_pre,1))
tf.argmax 是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。tf.argmax(y_pre,1)返回的是模型对于任一输入x预测到的标签值,而 tf.argmax(ys,1) 代表正确的标签,我们可以用 tf.equal 来检测我们的预测是否真实标签匹配,这行代码返回的是匹配的布尔值,成功1,失败0
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
tf.cast将布尔类型的correct_prediction转化成float型,然后取平均得到精确度
print sess.run(accuracy, feed_dict={xs: mnist.test.images, ys: mnist.test.labels})

精确度87.79%,官方说的91%我是没达到过,我训练最高不超过89%。
3.结尾
希望这篇博客能对你的学习有所帮助,谢谢观看!同时,有兴趣的朋友可以多改改参数试试不同的结果,比如学习率,batch_size等等,这对你的理解也是有帮助的!
下一篇笔记将写用cnn去分类MNIST数据集,敬请期待!
链接: https://pan.baidu.com/s/1oWXk2Iai5f7I4U411XP8hQ
以上是关于tensorflow笔记之MNIST手写识别系列一的主要内容,如果未能解决你的问题,请参考以下文章