storm 事务机制
Posted ulysses_you
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了storm 事务机制相关的知识,希望对你有一定的参考价值。
前言
为了保证tuple的强有序和exactly-once语义,storm提供了事务机制,为每个tuple提供一个id
设计方法1
为每个tuple设置一个事务id,在数据库保存事务id和当前处理的id做比较。
1.两个id不一样,由于事务的强有序特点,判断出该tuple没有出现过,所以更新id
2.id一样,重复出现,可以不用处理
问题:
这样做会导致新能很低,每个tuple都必须处理完后才能处理下一个tuple(否则会影响和下一个tuple的顺序),并且每个tuple还得至少访问一次数据库
设计方法2
单个性能慢,很自然的就想到了多个一起处理。多个tuple形成一个batch。这样也可以保证强有序性
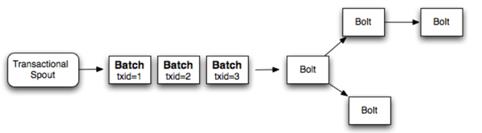
这样性能就提高了很多,如果一个batch处理了1000个tuples,那么性能就提高了1000倍。但是这还是没有更好的把资源利用充分。每个batch都是一个个处理,第二个batch必须等第一个batch完全处理完之后才能开始处理。

设计方法3
(storm选择的设计方法)
通过前两中设计方法,我们意识到了一个关键的思想,并不是所有的处理过程都需要保证强有序。只要保证最终执行完的那瞬间是强有序就ok。抽象出每次处理都需要两步。
1.计算一个batch的部分次数
2.在数据库更新该batch的部分次数
storm实现把对一个batch的计算分成了两块
1.处理。在此环节可以并发处理多个batch
2.提交。在此环节只能处理1个batch。这样就保证了强有序。
当这两块的其中某块出现问题,该事务都会被重新执行。
其实这跟设计方法二有点相似,都用了batch的思想。并结合分治思想,把整体尽可能的拆成许多小碎片,对每一个碎片都用最优的方法处理。
设计细节
1.storm把事务相关的信息存储在zookeeper中
2.storm会管理所有事务的处理或提交时机
3.关于容错。storm利用ack机制,会在合适的时候自动回放失败的事务。使用者不需要做任何acking
回放失败的事务需要一个tuple源的队列,比如kafka。
整体运行流程
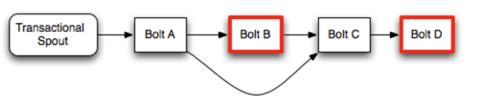
Processer必须等前一个Committer完成提交后才能调用finishBatch。
关于事务失败
由于事务框架屏蔽了Ack接口,提供了另一种方式,可以 throw FailedException.
关于配置
有两个重要配置
1.事务依赖的zookeeper,默认和storm集群依赖的一样,可以通过以下key修改
transactional.zookeeper.servers
2.同时处理batch的个数,默认是1,可以通过以下key修改
topology.max.spout.pending
参考资料
http://storm.apache.org/releases/1.1.1/Transactional-topologies.html
以上是关于storm 事务机制的主要内容,如果未能解决你的问题,请参考以下文章