windows10安装Anaconda+TensorFlow(CPU)+keras+Pycharm
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了windows10安装Anaconda+TensorFlow(CPU)+keras+Pycharm相关的知识,希望对你有一定的参考价值。
【安装Anaconda3】
下载:https://www.continuum.io/downloads,安装过程中提示failed to create anacoda menue错误时参考http://www.cnblogs.com/chuckle/p/7429624.html。
【安装TensorFlow】(须要网络链接,离线安装参考:http://www.jianshu.com/p/c245d46d43f0)
打开Anaconda Prompt,输入:
pip install tensorflow
【安装keras】(须要网络链接,参考:http://www.jianshu.com/p/c245d46d43f0)
打开Anaconda Prompt,输入:
pip install keras
这里会安装Theano,不管它。
【测试keras是否安装成功】(参考:http://www.jianshu.com/p/c245d46d43f0)
打开Anaconda Prompt,在命令行中输入:
python
再输入:
import tensorflow as tf
sess = tf.Session()
a = tf.constant(10)
b = tf.constant(22)
print(sess.run(a + b))
输出为32,TensorFlow安装成功。
再输入:
import keras
无错即keras安装成功。
【安装Pycharm并激活】
略。
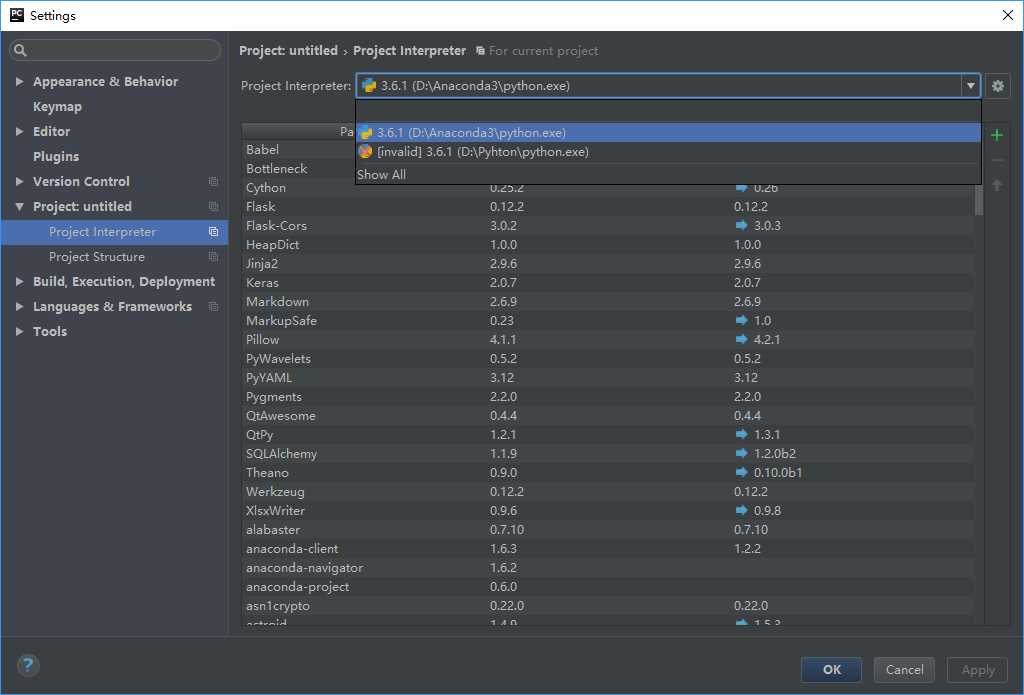
修改Python解释器路径,选择Anaconda安装目录下的python.exe:
【demo】(须要网络链接,下载数据集)
在Pycharm中新建工程,新建python file,拷贝下列代码(原作者:@渉风,http://www.cnblogs.com/surfzjy/p/6419201.html),运行。
from __future__ import print_function
# 导入numpy库, numpy是一个常用的科学计算库,优化矩阵的运算
import numpy as np
np.random.seed(1337)
# 导入mnist数据库, mnist是常用的手写数字库
from keras.datasets import mnist
# 导入顺序模型
from keras.models import Sequential
# 导入全连接层Dense, 激活层Activation 以及 Dropout层
from keras.layers.core import Dense, Dropout, Activation
# 导入优化器RMSProp
from keras.optimizers import RMSprop
# 导入numpy工具,主要是用to_categorical来转换类别向量
from keras.utils import np_utils
# 设置batch的大小
batch_size = 128
# 设置类别的个数
nb_classes = 10
# 设置迭代的次数
nb_epoch = 20
# keras中的mnist数据集已经被划分成了60,000个训练集,10,000个测试集的形式,按以下格式调用即可
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# X_train原本是一个60000*28*28的三维向量,将其转换为60000*784的二维向量
X_train = X_train.reshape(60000, 784)
# X_test原本是一个10000*28*28的三维向量,将其转换为10000*784的二维向量
X_test = X_test.reshape(10000, 784)
# 将X_train, X_test的数据格式转为float32存储
X_train = X_train.astype(‘float32‘)
X_test = X_test.astype(‘float32‘)
# 归一化
X_train /= 255
X_test /= 255
# 打印出训练集和测试集的信息
print(X_train.shape[0], ‘train samples‘)
print(X_test.shape[0], ‘test samples‘)
‘‘‘
将类别向量(从0到nb_classes的整数向量)映射为二值类别矩阵,
相当于将向量用one-hot重新编码‘‘‘
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
# 建立顺序型模型
model = Sequential()
‘‘‘
模型需要知道输入数据的shape,
因此,Sequential的第一层需要接受一个关于输入数据shape的参数,
后面的各个层则可以自动推导出中间数据的shape,
因此不需要为每个层都指定这个参数
‘‘‘
# 输入层有784个神经元
# 第一个隐层有512个神经元,激活函数为ReLu,Dropout比例为0.2
model.add(Dense(512, input_shape=(784,)))
model.add(Activation(‘relu‘))
model.add(Dropout(0.2))
# 第二个隐层有512个神经元,激活函数为ReLu,Dropout比例为0.2
model.add(Dense(512))
model.add(Activation(‘relu‘))
model.add(Dropout(0.2))
# 输出层有10个神经元,激活函数为SoftMax,得到分类结果
model.add(Dense(10))
model.add(Activation(‘softmax‘))
# 输出模型的整体信息
# 总共参数数量为784*512+512 + 512*512+512 + 512*10+10 = 669706
model.summary()
‘‘‘
配置模型的学习过程
compile接收三个参数:
1.优化器optimizer:参数可指定为已预定义的优化器名,如rmsprop、adagrad,
或一个Optimizer类对象,如此处的RMSprop()
2.损失函数loss:参数为模型试图最小化的目标函数,可为预定义的损失函数,
如categorical_crossentropy、mse,也可以为一个损失函数
3.指标列表:对于分类问题,一般将该列表设置为metrics=[‘accuracy‘]
‘‘‘
model.compile(loss=‘categorical_crossentropy‘,
optimizer=RMSprop(),
metrics=[‘accuracy‘])
‘‘‘
训练模型
batch_size:指定梯度下降时每个batch包含的样本数
nb_epoch:训练的轮数,nb指number of
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为epoch输出一行记录
validation_data:指定验证集
fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,
如果有验证集的话,也包含了验证集的这些指标变化情况
‘‘‘
history = model.fit(X_train, Y_train,
batch_size = batch_size,
nb_epoch = nb_epoch,
verbose = 1,
validation_data = (X_test, Y_test))
# 按batch计算在某些输入数据上模型的误差
score = model.evaluate(X_test, Y_test, verbose=0)
# 输出训练好的模型在测试集上的表现
print(‘Test score:‘, score[0])
print(‘Test accuracy:‘, score[1])
以上是关于windows10安装Anaconda+TensorFlow(CPU)+keras+Pycharm的主要内容,如果未能解决你的问题,请参考以下文章
在Windows10 + Anaconda中安装pip3工具