互联网级监控平台之内存存储的设计和优化
Posted I love .net
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了互联网级监控平台之内存存储的设计和优化相关的知识,希望对你有一定的参考价值。
上两篇文章我们介绍了时序数据库Influxdb在互联网级监控系统下的应用:
互联网级监控系统必备-时序数据库之Influxdb集群及踩过的坑
在我们监控平台V1.0和V2.0版本的演进过程中,设计上,我们在监控引擎端引入了内存存储的理念,即监控数据内存槽。
为什么需要一个内存存储来做监控数据的内存槽,它的应用场景是什么?
一. 从实际应用场景出发
首先,我们看一个实际的监控图表:配置中心服务的TPM
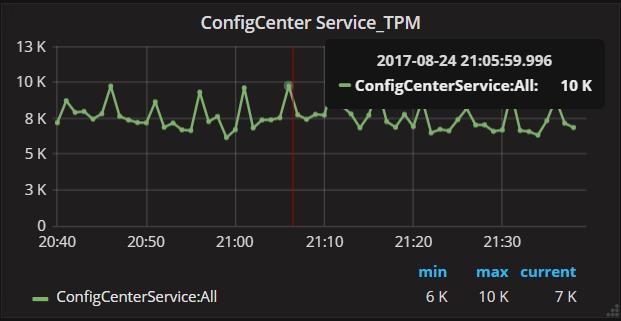
横轴是时间,纵轴是数值。每分钟一个点,当然也可以每10s一个点,一段时间区间内所有的点,连接成一条曲线,如图所示:一段时间内配置中心服务的TPM实时监控图表。
在我们的服务容器中,每次服务调用我们都会上报一次监控数据,即服务的耗时和相关的容器数据、纬度数据等。
由点及线,我们看每个点背后的数据:上图中,21:05:59:996这个时间点配置中心服务的TPM是10K,即这一分钟内发生了1W次调用,上报了1W个监控数据!
我们统计了每 1 Minute内服务的调用次数,类似的我们还可以统计每30s, 10s, 1s的调用次数。无论1 Minute,30s,20s,1s,这都代表了一个Time Window:时间窗口。
有了这些上报的监控数据,我们就可以在一个Time Window范围内进行监控数据的采样、分析。监控数据采样主要是在各个纬度下取这个Time Window下所有监控数据的最大值、最小值、个数、合计值、平均
值、最新值、第一个值等,示例中的TPM则是取的一分钟内的监控数据的个数,同样的,如果取平均值,即代表了服务的平均响应时间。采样后的数据写入Influxdb就可以展现了。
因此,在监控引擎内部需要一个内存结构来存储每个Time Window的监控数据,用于后续的监控数据采样和分析。
目前,我们的监控平台有2000+的监控项,这么大的监控体量,每天上报2TB的监控数据,折合每分钟1.42GB监控数据。这个内存存储结构应该如何设计?如何保证监控的准确性、实时性、有序性和并发性?
二. 言归正传,用演进的角度看监控内存存储结构的设计
1. 监控数据结构优化
海量的监控数据实时地从各个服务器上报到监控引擎中。首先我们要保证监控数据尽可能的小:这样才能传输的更快、更多。
- 不需要的数据不要上报
- 采用ProtoBuf序列化,尽可能的降低数据序列化带来的性能消耗,保证序列化后的数据的体量要小
2. 连续的内存还是分布的内存
监控引擎接收到上报的监控数据后,首先要将数据缓存到内存中,这时有两种选择:一直连续写?分布并行写? 孰优孰劣?
一直连续写:内存相对来说是连续的,但这是暂时的,当数据到达一定数量后,很多集合要Double扩容,内存瞬间的压力会很大!同时,数据写入是并发的,要保证线程安全,防止写入失败!
分布并行写:以空间换时间,同时降低了并行写入产生的锁争用问题,同时可以避免内存Double、频繁扩容的问题,唯一的劣势就是,内存占用多一点,需要实现内存的分布式管理
监控数据必须快速、及时的得到处理,实时性要求很高,同时,内存的成本基本可控,因此,我们选择了分布并行写的策略!
3. 内存存储的Sharding设计
在内存存储的设计上,我们借鉴了数据库Sharding的思路。为什么要做Sharding?假如将所有的监控数据都存储在一个内存集合中,每一类监控项在采样时,都要访问这个内存集合,线程争用很大,
必须加锁控制,此时会产生类似数据库阻塞的“内存线程阻塞”。因此:
按监控项做垂直拆分:每个监控项拥有自己单独的内存存储空间。内存的Sharding Key就是监控项。这样的设计,提升了内存操作的并行度,同时减少了锁争用。采样的各个线程操作各自的内存,只有线
程内存的计算处理,采样线程间没有交叉争用。一个监控项一个内存存储后,数据写入和采样数据读取依然有线程争用问题!数据在实时不断的写入,同时采样线程在实时指定Time Window的数据进行采样。
继续优化改进。
按时间做水平拆分:每一个监控项一个内存存储,同时再按分钟进行水平拆分,每分钟又是一个单独的子存储。即一个内存槽下60个槽点。每分钟一个槽点。
此时,监控数据接收时,首先根据监控数据对应的监控项,定位到对应的内存槽,第二步根据监控数据上的时间,定位到具体分钟槽点。数据写入的速度又提升了。同时,采样线程读取指定Time Window
下的数据时,可以快速根据时间纬度,找到指定的槽点。读取的速度也提升了!
4. 内存中读写分离设计
将内存中监控数据的读写分开,降低数据的读写争用。
数据写线程:实时并行写入各个内存槽和槽点中(监控项和时间纬度)
采样读线程:读取指定监控项对应的Time Window下的数据。
监控数据采样有个前提:例如要对上一分钟的数据进行采样,首先要保证上一分钟的数据尽可能的全部到位,这样数据才会准确。因此有个延迟时间的问题,例如5s延迟,21:57:05时,我们认为21:56的数
据已经全部到位。这样的话,我们就可以采用一个较小的延迟时间,来保证数据的准确性的同时,降低数据读写的争用。
通过设置了一个合理的延迟时间(5s),21:57:05时:
采样读线程:读取21:56对应槽点下的数据进行采样分析
数据写线程:将监控数据写入21:57对应的内存槽点中。
读写分开,内存争用非常少,性能和并行度再一次提升!!
5. 多线程优化
基于线程池,线程内的执行逻辑尽可能的快,使用完后立即放回线程池中。防止线程占用带来的线程暴涨问题!
三. 代码分享
1. 监控数据本地存储
1 public class MonitorLocalStore 2 { 3 private Dictionary<int, Queue<MonitorData>> cache; 4 5 private static object syncObj = new object(); 6 7 //监控元数据ID 8 private string metaDataID; 9 10 public DateTime CreateTime; 11 /// <summary> 12 /// 构造函数 13 /// </summary> 14 /// <param name="metaDataID">监控元数据ID</param> 15 public MonitorLocalStore(string metaDataID) 16 { 17 this.metaDataID = metaDataID; 18 cache = new Dictionary<int, Queue<MonitorData>>(); 19 for (int i = 0; i < 60; i++) 20 { 21 cache.Add(i, new Queue<MonitorData>()); 22 } 23 CreateTime = DateTime.Now; 24 } 25 26 public void Add(MonitorData value) 27 { 28 if (!cache.ContainsKey(value.Time.Minute)) 29 { 30 throw new Exception("Cannot find Time slot: " + value.Time.ToString() + ", Current slots: " + string.Join(",", cache.Keys)); 31 } 32 cache[value.Time.Minute].Enqueue(value); 33 } 34 35 public void Add(IEnumerable<MonitorData> valueSet) 36 { 37 Parallel.ForEach(valueSet, (i) => 38 { 39 cache[i.Time.Minute].Enqueue(i); 40 } 41 ); 42 } 43 44 public List<MonitorData> Get(params int[] scope) 45 { 46 var valueSet = new List<MonitorData>(); 47 foreach (var item in scope) 48 { 49 while (cache[item].Count > 0) 50 { 51 MonitorData data = cache[item].Dequeue(); 52 if (data != null) 53 { 54 valueSet.Add(data); 55 } 56 } 57 //valueSet.AddRange(cache[item]); 58 cache.Remove(item); 59 cache.Add(item, new Queue<MonitorData>()); 60 } 61 62 return valueSet; 63 } 64 65 /// <summary> 66 /// 获取本地缓存的总容量 67 /// </summary> 68 /// <returns>本地缓存的总容量</returns> 69 public long GetCapcity() 70 { 71 var length = 0; 72 foreach (var item in cache) 73 { 74 length += item.Value.Count; 75 } 76 77 return length; 78 } 79 80 public void Ecvit(params int[] scope) 81 { 82 lock (syncObj) 83 { 84 foreach (var item in scope) 85 { 86 cache[item] = new Queue<MonitorData>(); 87 } 88 } 89 } 90 91 public Dictionary<int, Queue<MonitorData>> GetCache() 92 { 93 return cache; 94 } 95 }
2. 监控存储分布式管理
1 class MonitorLocalStoreManager 2 { 3 private static object syncObj = new object(); 4 private ConcurrentDictionary<string, MonitorLocalStore> storeDic; 5 private List<string> metaDataList; 6 7 /// <summary> 8 /// 输出方法委托 9 /// </summary> 10 public Action<string> Output { get; set; } 11 /// <summary> 12 /// 构造函数 13 /// </summary> 14 private MonitorLocalStoreManager() 15 { 16 storeDic = new ConcurrentDictionary<string, MonitorLocalStore>(); 17 } 18 19 //监控数据本地存储管理器实例 20 private static MonitorLocalStoreManager instance; 21 22 /// <summary> 23 /// 获取监控数据本地存储管理器实例 24 /// </summary> 25 /// <returns>监控数据本地存储管理器实例</returns> 26 public static MonitorLocalStoreManager GetInstance() 27 { 28 if (instance == null) 29 { 30 lock (syncObj) 31 { 32 if (instance == null) 33 { 34 instance = new MonitorLocalStoreManager(); 35 } 36 } 37 } 38 39 return instance; 40 } 41 42 /// <summary> 43 /// 加载监控元数据存储 44 /// </summary> 45 /// <param name="metaDataList">监控元数据列表</param> 46 internal void LoadMetaDataStore(List<string> metaDataList) 47 { 48 this.metaDataList = metaDataList; 49 foreach (var metaDataID in metaDataList) 50 { 51 GetOrCreateStore(metaDataID); 52 } 53 } 54 55 /// <summary> 56 /// 根据监控元数据ID获取本机缓存Store 57 /// </summary> 58 /// <param name="metaDataID">监控元数据ID</param> 59 /// <returns>本机缓存Store</returns> 60 public MonitorLocalStore GetOrCreateStore(string metaDataID) 61 { 62 MonitorLocalStore store = null; 63 if (!storeDic.ContainsKey(metaDataID)) 64 { 65 lock (syncObj) 66 { 67 if (!storeDic.ContainsKey(metaDataID)) 68 { 69 if (!metaDataList.Contains(metaDataID)) 70 { 71 LocalErrorLogService.Write("Find New MetaData:" + metaDataID); 72 } 73 store = new MonitorLocalStore(metaDataID); 74 storeDic.TryAdd(metaDataID, store); 75 } 76 } 77 } 78 else 79 { 80 storeDic.TryGetValue(metaDataID, out store); 81 } 82 83 return store; 84 } 85 86 internal ConcurrentDictionary<string, MonitorLocalStore> GetStore() 87 { 88 return storeDic; 89 } 90 }
总结:
监控引擎使用了内存存储来接收缓存上报上来的监控数据。
使用场景:监控数据实时写入,大批量写入,定时采样归集。
技术挑战:快速写入、多线程读写安全、内存快速分配和释放,防止内存暴涨带来的Full GC和高CPU。
设计上的一些好的经验:
- 内存存储采用Sharding分区,每个监控项一个内存槽,每个内存槽分为60个槽点:以空间换时间,同时避免大内存分配。
- 多线程写入时,以监控项作为分区键,路由定位到指定的内存槽,以监控数据上的时间(分钟)作为二次分区键,存储到指定内存槽的槽点。实现多线程并行写入,最大程度上避免了多线程写入时的锁争用。
- 读写线程分离,读线程设置一个最佳的延迟时间(5~10s),读取内存槽点的已就绪的数据,此时数据没有写入,毫秒级读取,近乎实时的监控数据采样。
周国庆
2017/8/24
以上是关于互联网级监控平台之内存存储的设计和优化的主要内容,如果未能解决你的问题,请参考以下文章