梯度下降优化算法综述(翻译)
Posted warrioR_wx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了梯度下降优化算法综述(翻译)相关的知识,希望对你有一定的参考价值。
原文题目:An overview of gradient descent optimization algorithms
原文链接:http://sebastianruder.com/optimizing-gradient-descent
博文地址:http://blog.csdn.net/wangxinginnlp/article/details/50974594
梯度下降是最流行的优化算法之一并且目前为止是优化神经网络最常见的算法。与此同时,每一个先进的深度学习库都包含各种算法实现的梯度下降(比如lasagne's, caffe's, 和 keras'的文档)。然而,这些算法经常作为黑盒优化程序使用,所以难以感受到各种算法的长处和不足。
此博文旨在为你提供对不同梯度算法的直观感受,以期会帮助你更好地使用不同的梯度下降算法。首先,我们会罗列各种梯度下降算法的变种并简单地总结算法训练阶段的挑战。然后,我们会通过展示解决问题的动机和依据这些动机来推导更新法则,以介绍最常见的优化算法。我们也顺带罗列下并行分布式环境下的算法和体系结构。最后,我们会讨论其他有利于梯度下降优化算法的策略。
梯度下降是一种以通过在目标函数梯度 的反向上更新模型参数,来最小化模型参数的目标函数
的反向上更新模型参数,来最小化模型参数的目标函数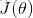 的方法。学习速率
的方法。学习速率 决定了我们前往(局部)极小值的步长。换言之,我们沿着目标函数所构造曲面的斜面按向下的方向走动,直到我们到达山谷。如果你对梯度下降不熟悉,你可以点击此处点击打开链接去了解一篇关于优化神经网络的介绍。
决定了我们前往(局部)极小值的步长。换言之,我们沿着目标函数所构造曲面的斜面按向下的方向走动,直到我们到达山谷。如果你对梯度下降不熟悉,你可以点击此处点击打开链接去了解一篇关于优化神经网络的介绍。
梯度下降算法变种
存在三种梯度下降的变种,他们不同之处在于我们在计算目标函数梯度时所用数据量的多少。依据数据的规模,我们在更新参数的准确性和执行一次更新所用时间之间进行一种折中。
批量梯度下降
普通的梯度下降,也称批量梯度下降,利用所有的训练数据计算目标函数的梯度。
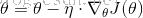
由于我们每进行一次参数更新需要计算整体训练数据的梯度,批量梯度下降会变得很慢并且一遇到内存吃不下数据就挂了。同时批量梯度下降也无法支持模型的在线更新,例如,新的样本不停的到来。
代码中,批量梯度下降大概长这样:
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad对于一个预先定义迭代轮数,我们首先以整体数据计算损失函数的梯度向量weights_grad关于参数向量params。值得注意的是先进的深度学习库提供对一些参数进行自动求导可以有效地计算梯度。如果你是自己来推梯度,梯度检查是一个不错的注意。(点击点击打开链接查看关于如何正确地检查梯度的建议)
我们随后以梯度的反方向更新我们的参数,此时学习速率决定着我们每次执行多大的更新。批量梯度下降可以保证在convex error surfaces 条件下取得全局最小值,在non-convex surfaces条件下取得局部极小值。
随机梯度下降
随机梯度下降(SGD)以一个训练样例 和标签
和标签 进行一次参数更新。
进行一次参数更新。

由于在每次参数更新前对相似的样例进行梯度重复计算, 批量梯度下降会在大数据集上进行冗余计算。SGD通过每次计算一个样例的方式避开这种冗余。因此,SGD速度会更快并支持在线学习。
SGD频繁的执行更新所伴随的高方差(a high variance)会导致目标函数如图1所示的剧烈波动。

图1. SGD波动
批量梯度下降收敛到盆面的极小值,SGD的波动一方面能够使(损失函数)跳到一个全新并且可鞥呢更优的局部极小值,另一方面这种波动由于一直overshooting终究会很难收敛到确切的极小值。然而,(实验)表明当我们慢慢地减小学习速率时SGD表现出和批量梯度下降同样的收敛行为,几乎确定地在non-convex and convex optimization中各自收敛到一个局部或者全局极小值在。
SGD的代码片段简单在训练实例上套一个循环并评估每一个训练样例的梯度。值得注意的是我们在每轮迭代时候会打乱训练数据,相关解释见点击打开链接
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_gradMini-batch gradient descent
Mini-batch gradient descent 吸收了上述两个算法的长处,利用小批量训练样例执行一次更新。

以这种方式,它可以 a) 减小参数更新的方差,导致更平稳的收敛。b) 利用先进深度学习库中常见的高度优化矩阵操作来高效地计算小批量的梯度。普通小批量的规模在50到256之间,但在不同的应用中会变化。Mini-batch gradient desent 是训练神经网络的经典选择,采用mini-bathes时常常也会称为SGD。注意在后文中SGD改进中,为简单起见,我们省略参数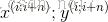 。
。
代码中,我们每轮迭代的mini-bathes规模设置为50。
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad挑战
然而,普通的mini-batch gradient descent不能保证较好的收敛性,这一点引出了下述挑战:
- 选择一个合适的学习速率是很难的。学习速率太小会导致收敛慢,太大会阻碍收敛并导致损失函数在极小值周围波动甚至背离。
- 尝试通过设置调度在训练时候调整训练速率,比如,模拟退火按照预先定义好的调度算法或者当相邻的迭代中目标变化小于一个阈值时候减小学习速率。但是这些调度和阈值需要预先设置,无法对数据集特征进行自适应。
- 除此之外,对所有的参数更新都按照同一个学习速率也是一个问题。如果我们的数据很稀疏并且我们的特征出现的次数不同,我们可能不会希望所有的参数以某种相同的幅度进行更新,而是针对很少出现的特征进行一次大幅度更新。
- 在神经网络中常见的极小化highly non-convex error functions的一个关键挑战是避免步入大量的suboptimal local minima。Dauphin等人认为实践中的困难来自saddle points而非local minima。所谓saddle points是指那些维度梯度不一致的点。这些saddle points经常被一个相等误差的平原包围,导致SGD很难摆脱,因为梯度在所有方向都近似于0。
以上是关于梯度下降优化算法综述(翻译)的主要内容,如果未能解决你的问题,请参考以下文章