storm学习笔记
Posted 路漫漫其修远兮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了storm学习笔记相关的知识,希望对你有一定的参考价值。
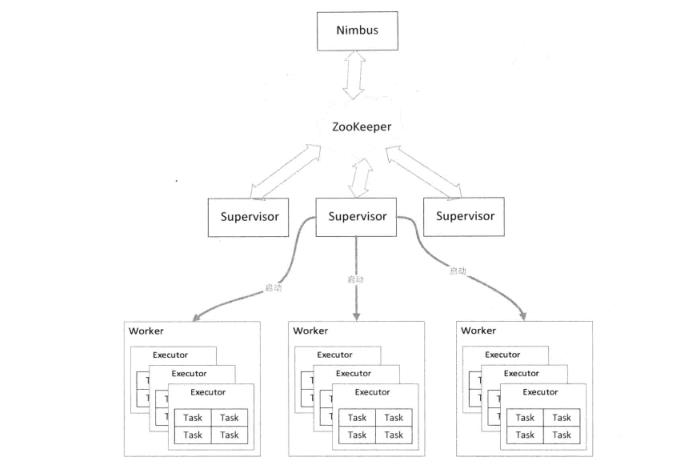
1、Nimbus
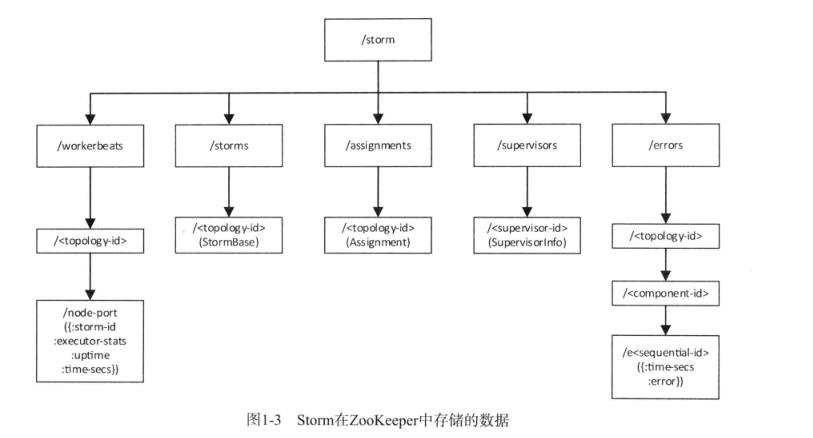
Nimbus创建时会创建以下三个节点:
a、/storm/workbeats/topology-id
b、/storm/storms/topology-id
c、/storm/assignments/topology-id
其中对于Nimbus只会创建目录不会设置数据(数据是worker设置的),b和c在创建的同时设置数据。a和b只有再提交新的topology的时候才会创建,并且b中的数据设置完后就不会再变化,
c是再第一次为该topology分配任务的时候创建,若任务分配计划有变,Nimbus就会更新它的内容
Nimbus从zk中获取数据时的路径,包括:
a、/storm/workbeats/topology-id
b、/storm/supervisor/topology-id
c、/storm/errors/topology-id
Nimbus需要从路径a中读取当前已被分配的Worker的运行状态。根据该信息可以得知Worker的状态以及Worker下面所有Executor的统计信息,这些信息会通过UI呈现给用户。
从路径b可以获取所有的Supervisor的状态,当有Supervisor不再活跃时会将它的任务分配到其它的空闲的Supervisor上去。
从路径c中获取所有的错误信息并通过UI呈现给用户
Storm集群中的机器数量时可以动态增减,当机器增减的时候会引起zookeeper中元数据的变化,Nimbus通过从zk中读取这些元数据不断地调整任务分配,所以Storm具有良好的可扩展性。
当Nimbus挂掉时,其他的节点时可以继续工作的,但是不能提交新的Topology,也不能重新进行任务的分配和负载调整,因此目前Nimbus存在单点的问题
2、Supervisor
supervisor除了zk\'来创建和获取元数据外,还可以监控制定的本地文件来检测有它启动的所有的Worker的状态。
-
-
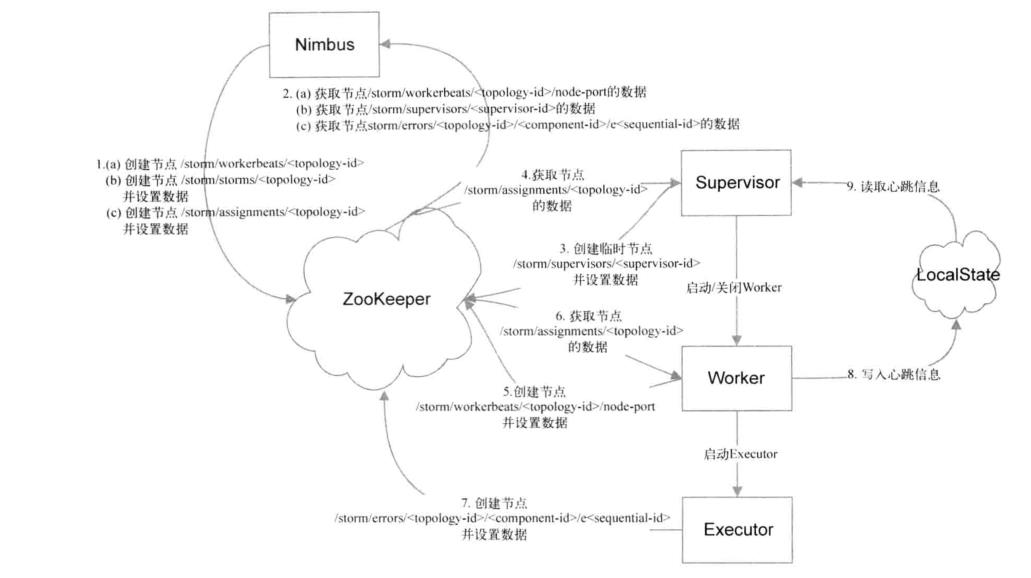
- 箭头3表示Supervisor在zk中创建的节点时/storm/supervisor/topology-id,当有新节点加入时会在该路径下创建一个节点。但是这个节点是临时的,当Supervisor和zk的链接稳定时,这个节点会一直存在,当和zk的连接断开时,该节点会被自动删除。所以该目录下都是当前活跃的机器,。这是Storm可以进行任务分配的基础,也是Storm具有容错性以及扩展性的基础
- 箭头4表示Supervisor需要获取元数据的路径是/storm/assignments/topology-id,它是Nimbus写入的对Topology任务分配的信息,Supervisor可以从该路径获取Nimbus分配给他的所有任务。Supervisor在本地保存着上次的分配信息,对比这两部分的信息可以得知分配信息是否有变化。若发生变化,则需要关闭被移除任务所对应的所有Worker,并启动新的Worker执行新的任务
- 箭头9表示Supervisor会从LocalState中获取由它启动的所有Worker的心跳信息。Supervisor会每隔一段时间检查一次这些心跳信息,当没有某个Worker的心跳信息时,这个Worker就是被kill掉,然后由Nimbus重新分配这个Worker的任务
-
3、Worker
-
-
- 箭头5表示Worker在zk中创建的路径是/storm/workbeats/topology-id/node-port,当Worker启动时将创建一个对应的节点。Nimbus在创建的时候只会创建/storm/workbeats/topology-id节点,但是不会设置里面的数据,里面的数据由Worker创建,这样做的目的时避免多个Worker同时创建路径冲突
- 箭头6表时Worker会从/storm/workbeats/topology-id节点中获取分配给它的任务并执行
- 箭头8表示Worker在Local State中保存心跳信息,这些心跳信息都保存在本地文件中,Worker用这些信息和Supervisor保持心跳,每隔几秒会更新一次心跳信息
-
4、Executor
Executor只会利用zk来记录错误信息
-
-
- 箭头7标志Executor在zk中创建的路径是/storm/errors/topology-id/componemt-id/sequential-id,
-
5、总结
-
-
- Nimnus和Supervisor之间通过/storm/supervisor/topology-id对应的数据进行心跳保持。Supervisor在创建这个路径时采用的时临时节点模式,只要Supervisor死掉这个节点就会被删除,Nimbus就会将分配给这个Supervisor的任务重新进行分配
- Worker和Supervisor之间/storm/workbeats/topology-id/node-port中的数据进行心跳的维持,NImbus会每隔一段时间获取该路径下的数据,同时Nimbus还会在它的内存中保存上一次的信息。如果发现某个Worker的心跳信息有一段时间没有更新就认为该worker已经死掉,就会将分配给该Worker的任务重新分配
- Worker和Supervisor之间维持心跳时通过本地文件(基于LocalState)
-
以上是关于storm学习笔记的主要内容,如果未能解决你的问题,请参考以下文章