Django
Posted IT乐仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Django相关的知识,希望对你有一定的参考价值。
Template
1 模板系统的介绍
你可能已经注意到我们在例子视图中返回文本的方式有点特别。 也就是说,html被直接硬编码在 Python代码之中。
def current_datetime(request):
now = datetime.datetime.now()
html = "<html><body>It is now %s.</body></html>" % now
return HttpResponse(html)
尽管这种技术便于解释视图是如何工作的,但直接将HTML硬编码到你的视图里却并不是一个好主意。 让我们来看一下为什么:
-
对页面设计进行的任何改变都必须对 Python 代码进行相应的修改。 站点设计的修改往往比底层 Python 代码的修改要频繁得多,因此如果可以在不进行 Python 代码修改的情况下变更设计,那将会方便得多。
-
Python 代码编写和 HTML 设计是两项不同的工作,大多数专业的网站开发环境都将他们分配给不同的人员(甚至不同部门)来完成。 设计者和HTML/CSS的编码人员不应该被要求去编辑Python的代码来完成他们的工作。
-
程序员编写 Python代码和设计人员制作模板两项工作同时进行的效率是最高的,远胜于让一个人等待另一个人完成对某个既包含 Python又包含 HTML 的文件的编辑工作。
基于这些原因,将页面的设计和Python的代码分离开会更干净简洁更容易维护。 我们可以使用 Django的 模板系统 (Template System)来实现这种模式,这就是本章要具体讨论的问题。
python的模板:HTML代码+逻辑控制代码
2 模板支持的语法
2.1 变量(使用双大括号来引用变量)
语法格式: {{var_name}}

----------------------------------Template和Context对象
>>> python manange.py shell (进入该django项目的环境) >>> from django.template import Context, Template >>> t = Template(\'My name is {{ name }}.\') >>> c = Context({\'name\': \'Stephane\'}) >>> t.render(c) \'My name is Stephane.\' # 同一模板,多个上下文,一旦有了模板对象,你就可以通过它渲染多个context,无论何时我们都可以 # 像这样使用同一模板源渲染多个context,只进行 一次模板创建然后多次调用render()方法渲染会 # 更为高效: # Low for name in (\'John\', \'Julie\', \'Pat\'): t = Template(\'Hello, {{ name }}\') print t.render(Context({\'name\': name})) # Good t = Template(\'Hello, {{ name }}\') for name in (\'John\', \'Julie\', \'Pat\'): print t.render(Context({\'name\': name}))
Django 模板解析非常快捷。 大部分的解析工作都是在后台通过对简短正则表达式一次性调用来完成。 这和基于 XML 的模板引擎形成鲜明对比,那些引擎承担了 XML 解析器的开销,且往往比 Django 模板渲染引擎要慢上几个数量级。


from django.shortcuts import render,HttpResponse
from django.template.loader import get_template #记得导入
# Create your views here.
import datetime
from django.template import Template,Context
# def current_time(req):
#原始的视图函数
# now=datetime.datetime.now()
# html="<html><body>现在时刻:<h1>%s.</h1></body></html>" %now
# return HttpResponse(html)
# def current_time(req):
#django模板修改的视图函数
# now=datetime.datetime.now()
# t=Template(\'<html><body>现在时刻是:<h1 style="color:red">{{current_date}}</h1></body></html>\')
#t=get_template(\'current_datetime.html\')
# c=Context({\'current_date\':now})
# html=t.render(c)
# return HttpResponse(html)
#另一种写法(推荐)
def current_time(req):
now=datetime.datetime.now()
return render(req, \'current_datetime.html\', {\'current_date\':now})
2.2 深度变量的查找(万能的句点号)
在到目前为止的例子中,我们通过 context 传递的简单参数值主要是字符串,然而,模板系统能够非常简洁地处理更加复杂的数据结构,例如list、dictionary和自定义的对象。在 Django 模板中遍历复杂数据结构的关键是句点字符 (.)。
#最好是用几个例子来说明一下。
# 首先,句点可用于访问列表索引,例如:
>>> from django.template import Template, Context
>>> t = Template(\'Item 2 is {{ items.2 }}.\')
>>> c = Context({\'items\': [\'apples\', \'bananas\', \'carrots\']})
>>> t.render(c)
\'Item 2 is carrots.\'
#假设你要向模板传递一个 Python 字典。 要通过字典键访问该字典的值,可使用一个句点:
>>> from django.template import Template, Context
>>> person = {\'name\': \'Sally\', \'age\': \'43\'}
>>> t = Template(\'{{ person.name }} is {{ person.age }} years old.\')
>>> c = Context({\'person\': person})
>>> t.render(c)
\'Sally is 43 years old.\'
#同样,也可以通过句点来访问对象的属性。 比方说, Python 的 datetime.date 对象有
#year 、 month 和 day 几个属性,你同样可以在模板中使用句点来访问这些属性:
>>> from django.template import Template, Context
>>> import datetime
>>> d = datetime.date(1993, 5, 2)
>>> d.year
1993
>>> d.month
5
>>> d.day
2
>>> t = Template(\'The month is {{ date.month }} and the year is {{ date.year }}.\')
>>> c = Context({\'date\': d})
>>> t.render(c)
\'The month is 5 and the year is 1993.\'
# 这个例子使用了一个自定义的类,演示了通过实例变量加一点(dots)来访问它的属性,这个方法适
# 用于任意的对象。
>>> from django.template import Template, Context
>>> class Person(object):
... def __init__(self, first_name, last_name):
... self.first_name, self.last_name = first_name, last_name
>>> t = Template(\'Hello, {{ person.first_name }} {{ person.last_name }}.\')
>>> c = Context({\'person\': Person(\'John\', \'Smith\')})
>>> t.render(c)
\'Hello, John Smith.\'
# 点语法也可以用来引用对象的方法。 例如,每个 Python 字符串都有 upper() 和 isdigit()
# 方法,你在模板中可以使用同样的句点语法来调用它们:
>>> from django.template import Template, Context
>>> t = Template(\'{{ var }} -- {{ var.upper }} -- {{ var.isdigit }}\')
>>> t.render(Context({\'var\': \'hello\'}))
\'hello -- HELLO -- False\'
>>> t.render(Context({\'var\': \'123\'}))
\'123 -- 123 -- True\'
# 注意这里调用方法时并* 没有* 使用圆括号 而且也无法给该方法传递参数;你只能调用不需参数的
# 方法。
2.3 变量的过滤器(filter)的使用
语法格式: {{obj|filter:param}}
# 1 add : 给变量加上相应的值
#
# 2 addslashes : 给变量中的引号前加上斜线
#
# 3 capfirst : 首字母大写
#
# 4 cut : 从字符串中移除指定的字符
#
# 5 date : 格式化日期字符串
#
# 6 default : 如果值是False,就替换成设置的默认值,否则就是用本来的值
#
# 7 default_if_none: 如果值是None,就替换成设置的默认值,否则就使用本来的值
#实例:
#value1="aBcDe"
{{ value1|upper }}<br>
#value2=5
{{ value2|add:3 }}<br>
#value3=\'he llo wo r ld\'
{{ value3|cut:\' \' }}<br>
#import datetime
#value4=datetime.datetime.now()
{{ value4|date:\'Y-m-d\' }}<br>
#value5=[]
{{ value5|default:\'空的\' }}<br>
#value6=\'<a href="#">跳转</a>\'
{{ value6 }}
{% autoescape off %}
{{ value6 }}
{% endautoescape %}
{{ value6|safe }}<br>
{{ value6|striptags }}
#value7=\'1234\'
{{ value7|filesizeformat }}<br>
{{ value7|first }}<br>
{{ value7|length }}<br>
{{ value7|slice:":-1" }}<br>
#value8=\'http://www.baidu.com/?a=1&b=3\'
{{ value8|urlencode }}<br>
value9=\'hello I am yuan\'
2.4 标签(tag)的使用(使用大括号和百分比的组合来表示使用tag)
语法格式: {% tags %}
{% if %} 的使用
{% if %}标签计算一个变量值,如果是“true”,即它存在、不为空并且不是false的boolean值,系统则会显示{% if %}和{% endif %}间的所有内容
{% if num >= 100 and 8 %}
{% if num > 200 %}
<p>num大于200</p>
{% else %}
<p>num大于100小于200</p>
{% endif %}
{% elif num < 100%}
<p>num小于100</p>
{% else %}
<p>num等于100</p>
{% endif %}
{% if %} 标签接受and,or或者not来测试多个变量值或者否定一个给定的变量
{% if %} 标签不允许同一标签里同时出现and和or,否则逻辑容易产生歧义,例如下面的标签是不合法的:
{% if obj1 and obj2 or obj3 %}
{% for %}的使用
{% for %}标签允许你按顺序遍历一个序列中的各个元素,每次循环模板系统都会渲染{% for %}和{% endfor %}之间的所有内容
<ul>
{% for obj in list %}
<li>{{ obj.name }}</li>
{% endfor %}
</ul>
#在标签里添加reversed来反序循环列表:
{% for obj in list reversed %}
...
{% endfor %}
#{% for %}标签可以嵌套:
{% for country in countries %}
<h1>{{ country.name }}</h1>
<ul>
{% for city in country.city_list %}
<li>{{ city }}</li>
{% endfor %}
</ul>
{% endfor %}
#系统不支持中断循环,系统也不支持continue语句,{% for %}标签内置了一个forloop模板变量,
#这个变量含有一些属性可以提供给你一些关于循环的信息
1,forloop.counter表示循环的次数,它从1开始计数,第一次循环设为1:
{% for item in todo_list %}
<p>{{ forloop.counter }}: {{ item }}</p>
{% endfor %}
2,forloop.counter0 类似于forloop.counter,但它是从0开始计数,第一次循环设为0
3,forloop.revcounter
4,forloop.revcounter0
5,forloop.first当第一次循环时值为True,在特别情况下很有用:
{% for object in objects %}
{% if forloop.first %}<li class="first">{% else %}<li>{% endif %}
{{ object }}
</li>
{% endfor %}
# 富有魔力的forloop变量只能在循环中得到,当模板解析器到达{% endfor %}时forloop就消失了
# 如果你的模板context已经包含一个叫forloop的变量,Django会用{% for %}标签替代它
# Django会在for标签的块中覆盖你定义的forloop变量的值
# 在其他非循环的地方,你的forloop变量仍然可用
#{% empty %}
{{li }}
{% for i in li %}
<li>{{ forloop.counter0 }}----{{ i }}</li>
{% empty %}
<li>this is empty!</li>
{% endfor %}
# [11, 22, 33, 44, 55]
# 0----11
# 1----22
# 2----33
# 3----44
# 4----55
csrf_token标签
用于生成csrf_token的标签,用于防治跨站攻击验证。 其实,这里是会生成一个input标签,和其他表单标签一起提交给后台的。
{% url %}
引用路由配置的地址
<form action="{% url "bieming"%}" >
<input type="text">
<input type="submit"value="提交">
{%csrf_token%}
</form>
{% with %}
用更简单的变量名替代复杂的变量名
{% with total=fhjsaldfhjsdfhlasdfhljsdal %} {{ total }} {% endwith %}
{% verbatim %}
禁止render
{% verbatim %}
{{ hello }}
{% endverbatim %}
{% load %}
略
加载标签库:自定义filter和simple_tag
a、在app中创建templatetags模块(必须的)
b、创建任意 .py 文件,如:my_tags.py
from django import template
from django.utils.safestring import mark_safe
register = template.Library() #register的名字是固定的,不可改变
@register.filter
def filter_multi(v1,v2):
return v1 * v2
@register.simple_tag
def simple_tag_multi(v1,v2):
return v1 * v2
@register.simple_tag
def my_input(id,arg):
result = "<input type=\'text\' id=\'%s\' class=\'%s\' />" %(id,arg,)
return mark_safe(result)
c、在使用自定义simple_tag和filter的html文件中导入之前创建的 my_tags.py :{% load my_tags %}
d、使用simple_tag和filter(如何调用)
-------------------------------.html
{% load xxx %} #首行
# num=12
{{ num|filter_multi:2 }} #24
{{ num|filter_multi:"[22,333,4444]" }}
{% simple_tag_multi 2 5 %} 参数不限,但不能放在if for语句中
{% simple_tag_multi num 5 %}
e、在settings中的INSTALLED_APPS配置当前app,不然django无法找到自定义的simple_tag.
注意:
filter可以用在if等语句后,simple_tag不可以
{% if num|filter_multi:30 > 100 %}
{{ num|filter_multi:30 }}
{% endif %}
extend模板继承
到目前为止,我们的模板范例都只是些零星的 HTML 片段,但在实际应用中,你将用 Django 模板系统来创建整个 HTML 页面。 这就带来一个常见的 Web 开发问题: 在整个网站中,如何减少共用页面区域(比如站点导航)所引起的重复和冗余代码?Django 解决此类问题的首选方法是使用一种优雅的策略—— 模板继承 。
本质上来说,模板继承就是先构造一个基础框架模板,而后在其子模板中对它所包含站点公用部分和定义块进行重载。
让我们通过修改 current_datetime.html 文件,为 current_datetime 创建一个更加完整的模板来体会一下这种做法:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN">
<html lang="en">
<head>
<title>The current time</title>
</head>
<body>
<h1>My helpful timestamp site</h1>
<p>It is now {{ current_date }}.</p>
<hr>
<p>Thanks for visiting my site.</p>
</body>
</html>
这看起来很棒,但如果我们要为 hours_ahead 视图创建另一个模板会发生什么事情呢?
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN">
<html lang="en">
<head>
<title>Future time</title>
</head>
<body>
<h1>My helpful timestamp site</h1>
<p>In {{ hour_offset }} hour(s), it will be {{ next_time }}.</p>
<hr>
<p>Thanks for visiting my site.</p>
</body>
</html>
Django 的模板继承系统解决了这些问题。 你可以将其视为服务器端 include 的逆向思维版本。 你可以对那些不同 的代码段进行定义,而不是 共同 代码段。
第一步是定义 基础模板,该框架之后将由子模板所继承。 以下是我们目前所讲述范例的基础模板:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN">
<html lang="en">
<head>
<title>{% block title %}{% endblock %}</title>
</head>
<body>
<h1>My helpful timestamp site</h1>
{% block content %}{% endblock %}
{% block footer %}
<hr>
<p>Thanks for visiting my site.</p>
{% endblock %}
</body>
</html>
这个叫做 base.html 的模板定义了一个简单的 HTML 框架文档,我们将在本站点的所有页面中使用。 子模板的作用就是重载、添加或保留那些块的内容。 (如果你一直按顺序学习到这里,保存这个文件到你的template目录下,命名为 base.html .)
我们使用模板标签: {% block %} 。 所有的 {% block %} 标签告诉模板引擎,子模板可以重载这些部分。 每个{% block %}标签所要做的是告诉模板引擎,该模板下的这一块内容将有可能被子模板覆盖。
现在我们已经有了一个基本模板,我们可以修改 current_datetime.html 模板来 使用它:
{% extends "base.html" %}
{% block title %}The current time{% endblock %}
{% block content %}
<p>It is now {{ current_date }}.</p>
{% endblock %}
再为 hours_ahead 视图创建一个模板,看起来是这样的:
{% extends "base.html" %}
{% block title %}Future time{% endblock %}
{% block content %}
<p>In {{ hour_offset }} hour(s), it will be {{ next_time }}.</p>
{% endblock %}
看起来很漂亮是不是? 每个模板只包含对自己而言 独一无二 的代码。 无需多余的部分。 如果想进行站点级的设计修改,仅需修改 base.html ,所有其它模板会立即反映出所作修改。
以下是其工作方式:
在加载 current_datetime.html 模板时,模板引擎发现了 {% extends %} 标签, 注意到该模板是一个子模板。 模板引擎立即装载其父模板,即本例中的 base.html 。此时,模板引擎注意到 base.html 中的三个 {% block %} 标签,并用子模板的内容替换这些 block 。因此,引擎将会使用我们在 { block title %} 中定义的标题,对 {% block content %} 也是如此。 所以,网页标题一块将由{% block title %}替换,同样地,网页的内容一块将由 {% block content %}替换。
注意由于子模板并没有定义 footer 块,模板系统将使用在父模板中定义的值。 父模板 {% block %} 标签中的内容总是被当作一条退路。继承并不会影响到模板的上下文。 换句话说,任何处在继承树上的模板都可以访问到你传到模板中的每一个模板变量。你可以根据需要使用任意多的继承次数。 使用继承的一种常见方式是下面的三层法:
<1> 创建 base.html 模板,在其中定义站点的主要外观感受。 这些都是不常修改甚至从不修改的部分。
<2> 为网站的每个区域创建 base_SECTION.html 模板(例如, base_photos.html 和 base_forum.html )。这些模板对base.html 进行拓展,
并包含区域特定的风格与设计。
<3> 为每种类型的页面创建独立的模板,例如论坛页面或者图片库。 这些模板拓展相应的区域模板。
这个方法可最大限度地重用代码,并使得向公共区域(如区域级的导航)添加内容成为一件轻松的工作。
以下是使用模板继承的一些诀窍:
<1>如果在模板中使用 {% extends %} ,必须保证其为模板中的第一个模板标记。 否则,模板继承将不起作用。
<2>一般来说,基础模板中的 {% block %} 标签越多越好。 记住,子模板不必定义父模板中所有的代码块,因此
你可以用合理的缺省值对一些代码块进行填充,然后只对子模板所需的代码块进行(重)定义。 俗话说,钩子越
多越好。
<3>如果发觉自己在多个模板之间拷贝代码,你应该考虑将该代码段放置到父模板的某个 {% block %} 中。
如果你需要访问父模板中的块的内容,使用 {{ block.super }}这个标签吧,这一个魔法变量将会表现出父模
板中的内容。 如果只想在上级代码块基础上添加内容,而不是全部重载,该变量就显得非常有用了。
<4>不允许在同一个模板中定义多个同名的 {% block %} 。 存在这样的限制是因为block 标签的工作方式是双向的。
也就是说,block 标签不仅挖了一个要填的坑,也定义了在父模板中这个坑所填充的内容。如果模板中出现了两个
相同名称的 {% block %} 标签,父模板将无从得知要使用哪个块的内容。
数据库与ORM
1 数据库的配置
1 django默认支持sqlite,mysql, oracle,postgresql数据库。
<1> sqlite
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动 , 引擎名称:django.db.backends.sqlite3
<2> mysql
引擎名称:django.db.backends.mysql
2 mysql驱动程序
- MySQLdb(mysql python)
- mysqlclient
- MySQL
- PyMySQL(纯python的mysql驱动程序)
3 在django的项目中会默认使用sqlite数据库,在settings里有如下设置:

如果我们想要更改数据库,需要修改如下:
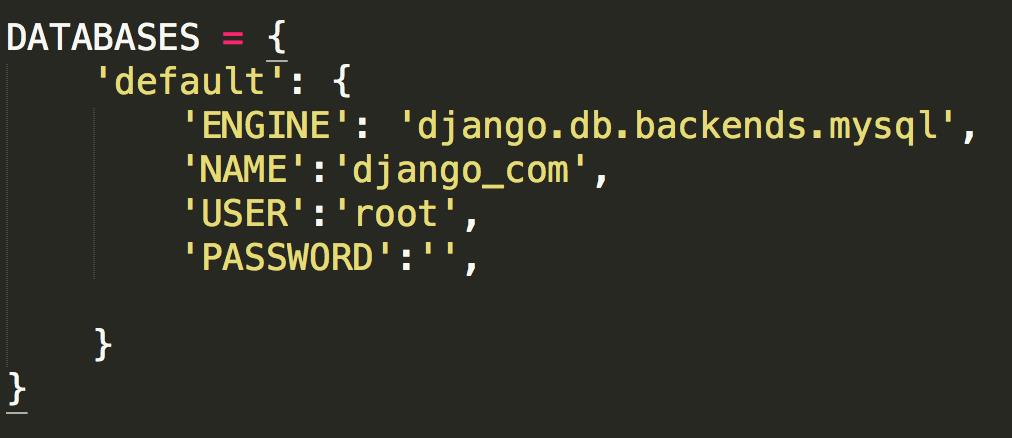
DATABASES = {
\'default\': {
\'ENGINE\': \'django.db.backends.mysql\',
\'NAME\': \'books\', #你的数据库名称
\'USER\': \'root\', #你的数据库用户名
\'PASSWORD\': \'\', #你的数据库密码
\'HOST\': \'\', #你的数据库主机,留空默认为localhost
\'PORT\': \'3306\', #你的数据库端口
}
}
注意:
NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建 USER和PASSWORD分别是数据库的用户名和密码。 设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。 然后,启动项目,会报错:no module named MySQLdb 这是因为django默认你导入的驱动是MySQLdb,可是MySQLdb对于py3有很大问题,所以我们需要的驱动是PyMySQL 所以,我们只需要找到项目名文件下的__init__,在里面写入: import pymysql pymysql.install_as_MySQLdb() 问题解决!
2 ORM表模型
表(模型)的创建:
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名。
作者详细模型:把作者的详情放到详情表,包含性别,email地址和出生日期,作者详情模型和作者模型之间是一对一的关系(one-to-one)(类似于每个人和他的身份证之间的关系),在大多数情况下我们没有必要将他们拆分成两张表,这里只是引出一对一的概念。
出版商模型:出版商有名称,地址,所在城市,省,国家和网站。
书籍模型:书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many),一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many),也被称作外键。
from django.db import models<br>
class Publisher(models.Model):
name = models.CharField(max_length=30, verbose_name="名称")
address = models.CharField("地址", max_length=50)
city = models.CharField(\'城市\',max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField()
class Meta:
verbose_name = \'出版商\'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
class Author(models.Model):
name = models.CharField(max_length=30)
def __str__(self):
return self.name
class AuthorDetail(models.Model):
sex = models.BooleanField(max_length=1, choices=((0, \'男\'),(1, \'女\'),))
email = models.EmailField()
address = models.CharField(max_length=50)
birthday = models.DateField()
author = models.OneToOneField(Author)
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2,default=10)
def __str__(self):
return self.title
分析代码:
<1> 每个数据模型都是django.db.models.Model的子类,它的父类Model包含了所有必要的和数据库交互的方法。并提供了一个简介漂亮的定义数据库字段的语法。
<2> 每个模型相当于单个数据库表(多对多关系例外,会多生成一张关系表),每个属性也是这个表中的字段。属性名就是字段名,它的类型(例如CharField)相当于数据库的字段类型(例如varchar)。大家可以留意下其它的类型都和数据库里的什么字段对应。
<3> 模型之间的三种关系:一对一,一对多,多对多。
一对一:实质就是在主外键(author_id就是foreign key)的关系基础上,给外键加了一个UNIQUE=True的属性;
一对多:就是主外键关系;(foreign key)
多对多:(ManyToManyField) 自动创建第三张表(当然我们也可以自己创建第三张表:两个foreign key)
ORM之增(create,save)
from app01.models import *
#create方式一: Author.objects.create(name=\'Alvin\')
#create方式二: Author.objects.create(**{"name":"alex"})
#save方式一: author=Author(name="alvin")
author.save()
#save方式二: author=Author()
author.name="alvin"
author.save()
重点来了------->那么如何创建存在一对多或多对多关系的一本书的信息呢?(如何处理外键关系的字段如一对多的publisher和多对多的authors)
#一对多(ForeignKey):
#方式一: 由于绑定一对多的字段,比如publish,存到数据库中的字段名叫publish_id,所以我们可以直接给这个
# 字段设定对应值:
Book.objects.create(title=\'php\',
publisher_id=2, #这里的2是指为该book对象绑定了Publisher表中id=2的行对象
publication_date=\'2017-7-7\',
price=99)
#方式二:
# <1> 先获取要绑定的Publisher对象:
pub_obj=Publisher(name=\'河大出版社\',address=\'保定\',city=\'保定\',
state_province=\'河北\',country=\'China\',website=\'http://www.hbu.com\')
OR pub_obj=Publisher.objects.get(id=1)
# <2>将 publisher_id=2 改为 publisher=pub_obj
#多对多(ManyToManyField()):
author1=Author.objects.get(id=1)
author2=Author.objects.filter(name=\'alvin\')[0]
book=Book.objects.get(id=1)
book.authors.add(author1,author2)
#等同于:
book.authors.add(*[author1,author2])
book.authors.remove(*[author1,author2])
#-------------------
book=models.Book.objects.filter(id__gt=1)
authors=models.Author.objects.filter(id=1)[0]
authors.book_set.add(*book)
authors.book_set.remove(*book)
#-------------------
book.authors.add(1)
book.authors.remove(1)
authors.book_set.add(1)
authors.book_set.remove(1)
#注意: 如果第三张表是通过models.ManyToManyField()自动创建的,那么绑定关系只有上面一种方式
# 如果第三张表是自己创建的:
class Book2Author(models.Model):
author=models.ForeignKey("Author")
Book= models.ForeignKey("Book")
# 那么就还有一种方式:
author_obj=models.Author.objects.filter(id=2)[0]
book_obj =models.Book.objects.filter(id=3)[0]
s=models.Book2Author.objects.create(author_id=1,Book_id=2)
s.save()
s=models.Book2Author(author=author_obj,Book_id=1)
s.save()
ORM之删(delete)
>>> Book.objects.filter(id=1).delete()
(3, {\'app01.Book_authors\': 2, \'app01.Book\': 1})
我们表面上删除了一条信息,实际却删除了三条,因为我们删除的这本书在Book_authors表中有两条相关信息,这种删除方式就是django默认的级联删除。
ORM之改(update和save)
实例:
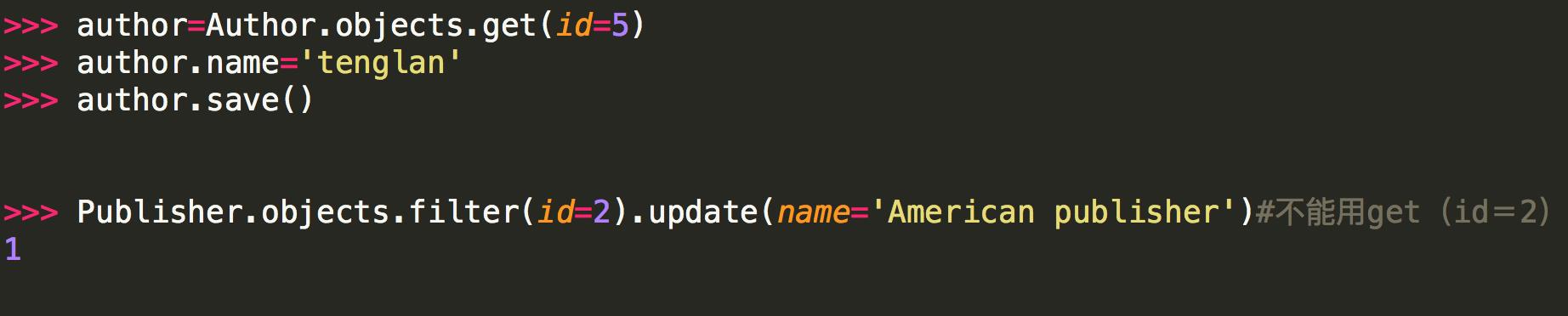
注意:
<1> 第二种方式修改不能用get的原因是:update是QuerySet对象的方法,get返回的是一个model对象,它没有update方法,而filter返回的是一个QuerySet对象(filter里面的条件可能有多个条件符合,比如name=\'alvin\',可能有两个name=\'alvin\'的行数据)。
<2>在“插入和更新数据”小节中,我们有提到模型的save()方法,这个方法会更新一行里的所有列。 而某些情况下,我们只需要更新行里的某几列。
#---------------- update方法直接设定对应属性----------------
models.Book.objects.filter(id=3).update(title="PHP")
##sql:
##UPDATE "app01_book" SET "title" = \'PHP\' WHERE "app01_book"."id" = 3; args=(\'PHP\', 3)
#--------------- save方法会将所有属性重新设定一遍,效率低-----------
obj=models.Book.objects.filter(id=3)[0]
obj.title="Python"
obj.save()
# SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price",
# "app01_book"."color", "app01_book"."page_num",
# "app01_book"."publisher_id" FROM "app01_book" WHERE "app01_book"."id" = 3 LIMIT 1;
#
# UPDATE "app01_book" SET "title" = \'Python\', "price" = 3333, "color" = \'red\', "page_num" = 556,
# "publisher_id" = 1 WHERE "app01_book"."id" = 3;
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。
注意,这里因为update返回的是一个整形,所以没法用query属性;对于每次创建一个对象,想显示对应的raw sql,需要在settings加上日志记录部分:
LOGGING = {
\'version\': 1,
\'disable_existing_loggers\': False,
\'handlers\': {
\'console\':{
\'level\':\'DEBUG\',
\'class\':\'logging.StreamHandler\',
},
},
\'loggers\': {
\'django.db.backends\': {
\'handlers\': [\'console\'],
\'propagate\': True,
\'level\':\'DEBUG\',
},
}
}
ORM之查(filter,value)
查询API:
# 查询相关API:
# <1>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
# <2>all(): 查询所有结果
# <3>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
#-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()--------
# <4>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列
# <5>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
# <6>order_by(*field): 对查询结果排序
# <7>reverse(): 对查询结果反向排序
# <8>distinct(): 从返回结果中剔除重复纪录
# <9>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
# <10>count(): 返回数据库中匹配查询(QuerySet)的对象数量。
# <11>first(): 返回第一条记录
# <12>last(): 返回最后一条记录
# <13>exists(): 如果QuerySet包含数据,就返回True,否则返回False
---------------了不起的双下划线(__)之单表条件查询---------------- # models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 # # models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 # models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in # # models.Tb1.objects.filter(name__contains="ven") # models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 # # models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and # # startswith,istartswith, endswith, iendswith,
QuerySet与惰性机制
所谓惰性机制:Publisher.objects.all()或者.filter()等都只是返回了一个QuerySet(查询结果集对象),它并不会马上执行sql,而是当调用QuerySet的时候才执行。
QuerySet特点:
<1> 可迭代的
<2> 可切片
#objs=models.Book.objects.all()#[obj1,obj2,ob3...]
#QuerySet: 可迭代
# for obj in objs:#每一obj就是一个行对象
# print("obj:",obj)
# QuerySet: 可切片
# print(objs[1])
# print(objs[1:4])
# print(objs[::-1])
QuerySet的高效使用:
<1>Django的queryset是惰性的
Django的queryset对应于数据库的若干记录(row),通过可选的查询来过滤。例如,下面的代码会得
到数据库中名字为‘Dave’的所有的人:person_set = Person.objects.filter(first_name="Dave")
上面的代码并没有运行任何的数据库查询。你可以使用person_set,给它加上一些过滤条件,或者将它传给某个函数,
这些操作都不会发送给数据库。这是对的,因为数据库查询是显著影响web应用性能的因素之一。
<2>要真正从数据库获得数据,你可以遍历queryset或者使用if queryset,总之你用到数据时就会执行sql.
为了验证这些,需要在settings里加入 LOGGING(验证方式)
obj=models.Book.objects.filter(id=3)
# for i in obj:
# print(i)
# if obj:
# print("ok")
<3>queryset是具有cache的
当你遍历queryset时,所有匹配的记录会从数据库获取,然后转换成Django的model。这被称为执行
(evaluation).这些model会保存在queryset内置的cache中,这样如果你再次遍历这个queryset,
你不需要重复运行通用的查询。
obj=models.Book.objects.filter(id=3)
# for i in obj:
# print(i)
## models.Book.objects.filter(id=3).update(title="GO")
## obj_new=models.Book.objects.filter(id=3)
# for i in obj:
# print(i) #LOGGING只会打印一次
<4>
简单的使用if语句进行判断也会完全执行整个queryset并且把数据放入cache,虽然你并不需要这些
数据!为了避免这个,可以用exists()方法来检查是否有数据:
obj = Book.objects.filter(id=4)
# exists()的检查可以避免数据放入queryset的cache。
if obj.exists():
print("hello world!")
<5>当queryset非常巨大时,cache会成为问题
处理成千上万的记录时,将它们一次装入内存是很浪费的。更糟糕的是,巨大的queryset可能会锁住系统
进程,让你的程序濒临崩溃。要避免在遍历数据的同时产生queryset cache,可以使用iterator()方法
来获取数据,处理完数据就将其丢弃。
objs = Book.objects.all().iterator()
# iterator()可以一次只从数据库获取少量数据,这样可以节省内存
for obj in objs:
print(obj.name)
#BUT,再次遍历没有打印,因为迭代器已经在上一次遍历(next)到最后一次了,没得遍历了
for obj in objs:
print(obj.name)
#当然,使用iterator()方法来防止生成cache,意味着遍历同一个queryset时会重复执行查询。所以使
#用iterator()的时候要当心,确保你的代码在操作一个大的queryset时没有重复执行查询
总结:
queryset的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候才会查询数据库。
使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并不会生成queryset cache,可能
会造成额外的数据库查询。
对象查询,单表条件查询,多表条件关联查询
#--------------------对象形式的查找--------------------------
# 正向查找
ret1=models.Book.objects.first()
print(ret1.title)
print(ret1.price)
print(ret1.publisher)
print(ret1.publisher.name) #因为一对多的关系所以ret1.publisher是一个对象,而不是一个queryset集合
# 反向查找
ret2=models.Publish.objects.last()
print(ret2.name)
print(ret2.city)
#如何拿到与它绑定的Book对象呢?
print(ret2.book_set.all()) #ret2.book_set是一个queryset集合
#---------------了不起的双下划线(__)之单表条件查询----------------
# models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值
#
# models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
# models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in
#
# models.Tb1.objects.filter(name__contains="ven")
# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
#
# models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and
#
# startswith,istartswith, endswith, iendswith,
#----------------了不起的双下划线(__)之多表条件关联查询---------------
# 正向查找(条件)
# ret3=models.Book.objects.filter(title=\'Python\').values(\'id\')
# print(ret3)#[{\'id\': 1}]
#正向查找(条件)之一对多
ret4=models.Book.objects.filter(title=\'Python\').values(\'publisher__city\')
print(ret4) #[{\'publisher__city\': \'北京\'}]
#正向查找(条件)之多对多
ret5=models.Book.objects.filter(title=\'Python\').values(\'author__name\')
print(ret5)
ret6=models.Book.objects.filter(author__name="alex").values(\'title\')
print(ret6)
#注意
#正向查找的publisher__city或者author__name中的publisher,author是book表中绑定的字段
#一对多和多对多在这里用法没区别
# 反向查找(条件)
#反向查找之一对多:
ret8=models.Publisher.objects.filter(book__title=\'Python\').values(\'name\')
print(ret8)#[{\'name\': \'人大出版社\'}] 注意,book__title中的book就是Publisher的关联表名
ret9=models.Publisher.objects.filter(book__title=\'Python\').values(\'book__authors\')
print(ret9)#[{\'book__authors\': 1}, {\'book__authors\': 2}]
#反向查找之多对多:
ret10=models.Author.objects.filter(book__title=\'Python\').values(\'name\')
print(ret10)#[{\'name\': \'alex\'}, {\'name\': \'alvin\'}]
#注意
#正向查找的book__title中的book是表名Book
#一对多和多对多在这里用法没区别
注意:条件查询即与对象查询对应,是指在filter,values等方法中的通过__来明确查询条件。
聚合查询和分组查询
<1> aggregate(*args,**kwargs):
通过对QuerySet进行计算,返回一个聚合值的字典。aggregate()中每一个参数都指定一个包含在字典中的返回值。即在查询集上生成聚合。
from django.db.models import Avg,Min,Sum,Max
从整个查询集生成统计值。比如,你想要计算所有在售书的平均价钱。Django的查询语法提供了一种方式描述所有
图书的集合。
>>> Book.objects.all().aggregate(Avg(\'price\'))
{\'price__avg\': 34.35}
aggregate()子句的参数描述了我们想要计算的聚合值,在这个例子中,是Book模型中price字段的平均值
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的
标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定
一个名称,可以向聚合子句提供它:
>>> Book.objects.aggregate(average_price=Avg(\'price\'))
{\'average_price\': 34.35}
如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
>>> Book.objects.aggregate(Avg(\'price\'), Max(\'price\'), Min(\'price\'))
{\'price__avg\': 34.35, \'price__max\': Decimal(\'81.20\'), \'price__min\': Decimal(\'12.99\')}
<2> annotate(*args,**kwargs):
可以通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合。
查询alex出的书总价格

查询各个作者出的书的总价格,这里就涉及到分组了,分组条件是authors__name

查询各个出版社最便宜的书价是多少

F查询和Q查询
仅仅靠单一的关键字参数查询已经很难满足查询要求。此时Django为我们提供了F和Q查询:
# F 使用查询条件的值,专门取对象中某列值的操作
# from django.db.models import F
# models.Tb1.objects.update(num=F(\'num\')+1)
# Q 构建搜索条件
from django.db.models import Q
#1 Q对象(django.db.models.Q)可以对关键字参数进行封装,从而更好地应用多个查询
q1=models.Book.objects.filter(Q(title__startswith=\'P\')).all()
print(q1)#[<Book: Python>, <Book: Perl>]
# 2、可以组合使用&,|操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象。
Q(title__startswith=\'P\') | Q(title__startswith=\'J\')
# 3、Q对象可以用~操作符放在前面表示否定,也可允许否定与不否定形式的组合
Q(title__startswith=\'P\') | ~Q(pub_date__year=2005)
# 4、应用范围:
# Each lookup function that takes keyword-arguments (e.g. filter(),
# exclude(), get()) can also be passed one or more Q objects as
# positional (not-named) arguments. If you provide multiple Q object
# arguments to a lookup function, the arguments will be “AND”ed
# together. For example:
Book.objects.get(
Q(title__startswith=\'P\'),
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6))
)
#sql:
# SELECT * from polls WHERE question LIKE \'P%\'
# AND (pub_date = \'2005-05-02\' OR pub_date = \'2005-05-06\')
# import datetime
# e=datetime.date(2005,5,6) #2005-05-06
# 5、Q对象可以与关键字参数查询一起使用,不过一定要把Q对象放在关键字参数查询的前面。
# 正确:
Book.objects.get(
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)),
title__startswith=\'P\')
# 错误:
Book.objects.get(
question__startswith=\'P\',
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)))
以上是关于Django的主要内容,如果未能解决你的问题,请参考以下文章
django.core.exceptions.ImproperlyConfigured: Requested setting DEFAULT_INDEX_TABLESPACE的解决办法(转)(代码片段