线性表
Posted 乘风有时
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线性表相关的知识,希望对你有一定的参考价值。
线性表定义
线性表:由零个或多个数据元素组成的有限序列。
注意:
1.线性表是一个序列。
2.0个元素构成的线性表是空表。
3.线性表中的第一个元素无前驱,最后一个元素无后继,其他元素有且只有一个前驱和后继。
4.线性表是有长度的,其长度就是元素个数,且线性表的元素个数是有限的,也就是说,线性表的长度是有限的。
线性表的操作:
InitList(*L): 初始化操作,建立一个空的线性表L。
ListEmpty(L): 判断线性表是否为空表,若线性表为空,返回true,否则返回false。
ClearList(*L): 将线性表清空。 GetElem(L,i,*e): 将线性表L中的第i个位置元素值返回给e。
LocateElem(L,e): 在线性表L中查找与给定值e相等的元素,如果查找成功,返回该元素在表中序号表示成功;否则,返回0表示失败。
ListInsert(*L,i,e): 在线性表L中第i个位置插入新元素e。
ListDelete(*L,i,*e): 删除线性表L中第i个位置元素,并用e返回其值。
ListLength(L): 返回线性表L的元素个数。
不同的线性表操作的实现不同。简单可以分为顺序结构的线性表(叫做顺序表)和链式结构的线性表(叫做链表)。
数组
顺序结构的常用结构是数组。
下面有一些数组相关的题目:


Game of Life: Find the Duplicate Number: Move Zeroes: Wiggle Sort: Find the Celebrity: Missing Number:http://www.cnblogs.com/yeqluofwupheng/p/6821489.html 3Sum Smaller: Shortest Word Distance III: Shortest Word Distance: Summary Ranges: Contains Duplicate:http://www.cnblogs.com/yeqluofwupheng/p/6803172.html Minimum Size Subarray Sum:http://www.cnblogs.com/yeqluofwupheng/p/6792536.html Rotate Array: Majority Element: Two Sum II - Input array is sorted: Missing Ranges: Find Peak Element: Find Minimum in Rotated Sorted Array II: Find Minimum in Rotated Sorted Array: Maximum Product Subarray: Longest Consecutive Sequence: Word Ladder II: Best Time to Buy and Sell Stock:http://www.cnblogs.com/yeqluofwupheng/p/6777266.html Triangle: Pascal\'s Triangle: Construct Binary Tree from Inorder and Postorder Traversal: Construct Binary Tree from Preorder and Inorder Traversal: Merge Sorted Array: Maximal Rectangle:http://www.cnblogs.com/yeqluofwupheng/p/6685553.html Largest Rectangle in Histogram: Remove Duplicates from Sorted Array:http://www.cnblogs.com/yeqluofwupheng/p/6685537.html Word Search:http://www.cnblogs.com/yeqluofwupheng/p/6685493.html Subsets: Sort Colors:http://www.cnblogs.com/yeqluofwupheng/p/6685357.html Search a 2D Matrix:http://www.cnblogs.com/yeqluofwupheng/p/6685094.html Set Matrix Zeroes:http://www.cnblogs.com/yeqluofwupheng/p/6685057.html Plus One: Unique Paths:http://www.cnblogs.com/yeqluofwupheng/p/6683456.html Insert Interval: Merge Intervals:http://www.cnblogs.com/yeqluofwupheng/p/6670543.html Spiral Matrix:http://www.cnblogs.com/yeqluofwupheng/p/6678988.html Maximum Subarray: Rotate Image:http://www.cnblogs.com/yeqluofwupheng/p/6675965.html Jump Game:http://www.cnblogs.com/yeqluofwupheng/p/6661395.html First Missing Positive: Search Insert Position: Search in Rotated Sorted Array:http://www.cnblogs.com/yeqluofwupheng/p/6678943.html Permutation:http://www.cnblogs.com/yeqluofwupheng/p/6670581.html Remove Element:http://www.cnblogs.com/yeqluofwupheng/p/6783239.html sum相关:http://www.cnblogs.com/yeqluofwupheng/p/6661410.html Container With Most Water:http://www.cnblogs.com/yeqluofwupheng/p/6670523.html Remove Duplicates from Sorted Array:
- 无需为了表示表中元素之间的逻辑关系而增加额外的存储空间(相对于链式存储而言)。
- 可以快速的存取表中任意位置的元素。
- 插入和删除操作需要移动大量的元素。
- 当线性表长度变化较大时,难以确定存储空间的容量。
- 容易造成存储空间的“碎片”(因为线性表的顺序存储结构申请的内存空间都以连续的,如果因为某些操作(比如删除操作)导致某个部分出现了一小块的不连续内存空间,因为这一小块内存空间太小不能够再次被利用/分配,那么就造成了内存浪费,也就是“碎片”)
链表
链式存储结构的线性表由一个(可以使零)或者多个结点(Node)组成。每个节点内部又分为数据域和指针域(链)。数据域存储了数据元素的信息。指针域存储了当前结点指向的直接后继的指针地址。
链表的特点:
- 长度不固定,可以任意增删。
- 存储空间不连续,数据元素之间使用指针相连,每个数据元素只能访问周围的一个元素(根据单链表还是双链表有所不同)。
- 存储密度小,因为每个数据元素,都需要额外存储一个指向下一元素的指针(双链表则需要两个指针)。
- 要访问特定元素,只能从链表头开始,遍历到该元素,时间复杂度为 O(n)。
- 在特定的数据元素之后插入或删除元素,不涉及到其他元素的移动,因此时间复杂度为 O(1)。双链表还允许在特定的数据元素之前插入或删除元素。
单链表
单链表是只包含指向下一个节点的指针,只能单向遍历。
节点结构:
struct ListNode {//单链表
int val;
ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};
建立链表的两种方法:
头插法:在头结点(为了操作方便,在单链表的第一个结点之前附加一个结点,称为头结点。头结点的数据域可以存储数据标题、表长等信息,也可以不存储任何信息,其指针域存储第一个结点的首地址)H之后插入数据,其特点是读入的数据顺序与线性表的逻辑顺序正好相反。如果不附加头结点,则表示每次将新增节点插入到第一个节点的前面。
ListNode *createListByHead(vector<int>& arr){ ListNode *head = nullptr; for (auto &i : arr){ ListNode *r = new ListNode(i); if (head){//head不为空,则插入head的前面 r->next = head; } head = r;//head为空,直接赋给head } return head; }
尾插法:将每次插入的新结点放在链表的尾部。其特点是读入的数据顺序与线性表的逻辑顺序相同。
ListNode *createListByTail(vector<int>& arr){ ListNode *head = nullptr, *p = nullptr; for (auto &i : arr){ ListNode *r = new ListNode(i); if (head){//插入到尾部 p->next = r; p = r; } else{//第一个节点时,直接赋给head head = r; p = head; } } return head; }
链表相关的题目:
Design Phone Directory: Plus One Linked List: Odd Even Linked List:http://www.cnblogs.com/yeqluofwupheng/p/6965118.html Delete Node in a Linked List: Palindrome Linked List: Reverse Linked List:http://www.cnblogs.com/yeqluofwupheng/p/6790629.html Remove Linked List Elements:http://www.cnblogs.com/yeqluofwupheng/p/6783239.html Intersection of Two Linked Lists: Sort List:http://www.cnblogs.com/yeqluofwupheng/p/6755973.html Insertion Sort List:http://www.cnblogs.com/yeqluofwupheng/p/6755568.html Reorder List:http://www.cnblogs.com/yeqluofwupheng/p/6741434.html Linked List Cycle:http://www.cnblogs.com/yeqluofwupheng/p/6746209.html Copy List with Random Pointer:http://www.cnblogs.com/yeqluofwupheng/p/7420510.html Convert Sorted List to Binary Search Tree: Reverse Linked List II:http://www.cnblogs.com/yeqluofwupheng/p/6685704.html Partition List:http://www.cnblogs.com/yeqluofwupheng/p/6685575.html Remove Duplicates from Sorted List:http://www.cnblogs.com/yeqluofwupheng/p/6685537.html Rotate List:http://www.cnblogs.com/yeqluofwupheng/p/6684840.html Reverse Nodes in k-Group: Swap Nodes in Pairs:http://www.cnblogs.com/yeqluofwupheng/p/6679070.html Merge Two Sorted Lists:http://www.cnblogs.com/yeqluofwupheng/p/6786570.html Remove Nth Node From End of List:http://www.cnblogs.com/yeqluofwupheng/p/6675892.html Add Two Numbers: Add Two Numbers II:
链表相关的排序算法:
直接插入排序:
由于直接插入排序需要大量插入操作,因此,适用于链表的结构,该排序算法的特点在排序算法的总结中再详细说明。
过程如下:每次从剩下的给定的数据中找到最小的数据将它插入到链表的尾部(尾插法),此时排好序之后,链表时从小到大的顺序。反之,如果每次插入到头部,排好序之后就是从大到小了。
下面程序的实现思路是:按照给定的数据顺序,一次取下一个数据,将他插入到当前已经有序的链表的合适位置。
ListNode* insertionSortList(ListNode* head){ if (!head)return head; ListNode* root = head; head = head->next;//先移动到下一个节点 root->next = nullptr;//再将根的next置为空 while (head){ ListNode* p = root; if (head->val < p->val){//当前节点需要插入头部 root = head; head = head->next; root->next = p; } else{ //找到当前节点head的值小于p的下一个节点的值的p节点 while (p->next && head->val >= p->next->val){//等于可以保证稳定性 p = p->next; } ListNode* q = head; head = head->next;//先移动到下一个节点 q->next = p->next;//再将当前节点q的next置为p->next p->next = q; } } return root; }
对链表的归并排序:
归并排序的特点在排序的总结中再详细说明,下面只说一下它的过程:
先将它划分成k各部分每个部分排好序后,再两两合并,直到所有的部分都合并到一起,就排好序。
ListNode* mergeList(ListNode* l1, ListNode* l2){ if (!l1)return l2; if (!l2)return l1; ListNode* head = nullptr; ListNode* p = nullptr; if (l1->val <= l2->val){//比较两个链表头的值的大小 head = l1;//第一个小 p = head; l1 = l1->next; } else{//第二个小 head = l2; p = head; l2 = l2->next; } while (l1 && l2){//合并两个链表 if (l1->val <= l2->val){ p->next = l1; l1 = l1->next; } else{ p->next = l2; l2 = l2->next; } p = p->next; } if (l1){//第一个链表有剩余 p->next = l1; } if (l2){//第二个链表有剩余 p->next = l2; } return head; } ListNode* sortList(ListNode* head){ if (!head || !head->next)return head; int step = 3,length = 1;//step为步长,length为链表长度 ListNode* p = head; while (p->next){ ListNode* pa = p;//记录需要插入排序的子链表的头结点的父节点 ListNode* gson = nullptr;//记录需要插入排序的子链表的尾结点的子节点 for (int i = 0; p->next && i < step; i++){//长度为步长的子链表 p = p->next; ++length; } if (p->next){//未到链表尾部 gson = p->next;//切断子链表尾部与原链表的联系 p->next = nullptr; } pa->next = insertionSortList(pa->next);//插入排序 p = pa; while (p->next)p = p->next;//找到子链表的尾部 if (gson){//将切断的子链表与原链表的联系重新连接起来 p->next = gson; } } ListNode* tail = nullptr; for (; step < length; step = step << 1) { p = head->next;//从第二个节点开始合并链表,不用判断头结点的特殊情况 //用于合并的两个子链表 ListNode* left = nullptr,* right = nullptr; tail = head; int cur = 1; while (cur + step < length){//当前位置之后没有step个节点 left = p; for (int i = 1; i < step; i++){//找到第一个步长为step的子链表 p = p->next; } cur += step;//更新当前位置 right = p->next; p->next = nullptr;//第一个子链表的尾部置为空 p = right;//更新当前位置指针 if (cur + step < length){//是否有足够step个节点做第二个子链表 for (int i = 1; i < step; i++){////找到第二个步长为step的子链表 p = p->next; } ListNode* q = p->next; p->next = nullptr;//第二个子链表的尾部置为空 p = q;//更新当前位置指针 left = mergeList(left, right); } else{//不够 left = mergeList(left, right);//直接合并 p = nullptr; } tail->next = left;//连接合并后的子链表 while (tail->next)tail = tail->next;//找到新的尾巴 tail->next = p; cur += step;//更新当前位置 } } if (p && tail && tail != head){//尾部不够一个步长的子链表未合并 tail->next = nullptr; p = mergeList(head->next, p);//保证head->next到tail的链表不为空 } p = head->next; head->next = nullptr; head = mergeList(head, p); return head; }
总结:
1.数组是将元素在内存中连续存放,由于每个元素占用内存相同,可以通过下标迅速访问数组中任何元素。链表中的元素在内存中不是顺序存储的,而是通过存在元素中的指针联系到一起。
2.增加和删除一个元素对于链表数据结构就非常简单了,只要修改元素中的指针就可以了。如果要在数组中增加一个元素,需要移动大量元素,在内存中空出一个元素的空间,然后将要增加的元素放在其中。
3.从内存存储角度来看,(静态)数组从栈中分配空间, 对于程序员方便快速,但自由度小; 链表从堆中分配空间, 自由度大但申请管理比较麻烦。
双向链表
双向链表的指针域有两个指针,每个数据结点分别指向直接后继和直接前驱。单向链表只能从表头开始向后遍历,而双向链表不但可以从前向后遍历,也可以从后向前遍历。除了双向遍历的优点,双向链表的删除的时间复杂度会降为O(1),因为直接通过目的指针就可以找到前驱节点,单向链表得从表头开始遍历寻找前驱节点。缺点是每个节点多了一个指针的空间开销。如下图就是一个双向链表。
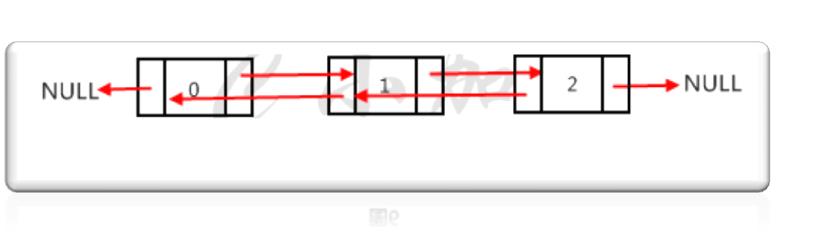
双向链表结构:
struct DoubleListNode{ int val; DoubleListNode *prev, *next; DoubleListNode(int x) :val(x), prev(nullptr), next(nullptr){}; };
创建链表的函数如下:
DoubleListNode *createDoubleList(vector<int> &arr){ DoubleListNode *head = nullptr, *p = nullptr; for (auto &i : arr){ DoubleListNode *r = new DoubleListNode(i); if (p){ p->next = r; r->prev = p; } else{ head = r; } p = r; } return head; }
其他的操作可以参考下面的博文:http://blog.csdn.net/feixiaoxing/article/details/6849457
循环链表
循环链表就是让链表的最后一个节点指向第一个节点,这样就形成了一个圆环,可以循环遍历。单向循环链表可以单向循环遍历,双向循环链表的头节点的指针也要指向最后一个节点,这样的可以双向循环遍历。
循环链表结构:
struct CircListNode{ int val; CircListNode *next; CircListNode(int x) :val(x), next(nullptr){}; };
创建循环链表:
CircListNode *createCircList(vector<int> &arr){ CircListNode *head = nullptr, *p = nullptr; for (auto &i : arr){ CircListNode *r = new CircListNode(i); if (p){ p->next = r; } else{ head = r; } p = r; } p->next = head; return head; }
更详细的操作可参考下面博文:http://blog.csdn.net/insistgogo/article/details/6667050
随机链表
在每个节点上增加一个随机指针,该指针可以为空,也可以指向链表中任意节点。
struct RandomListNode {//增加随机链指针的链表 int label; RandomListNode *next, *random; RandomListNode(int x) : label(x), next(NULL), random(NULL) {} };
LeetCode中有一题深拷贝一个随机链表,详细参考这篇博客:http://www.cnblogs.com/yeqluofwupheng/p/7420510.html
链表还有许多小技巧,例如:不同的步长来判断环,找到环的入口,删除环,找到两个链表相交的部分等算法,都可以在上面链表相关题目的列表中找到。
也可以参考下面的博文:http://blog.csdn.net/vividonly/article/details/6673758
以上是关于线性表的主要内容,如果未能解决你的问题,请参考以下文章