HDFS中高可用性HA的讲解
Posted 因为专注。所以专业
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS中高可用性HA的讲解相关的知识,希望对你有一定的参考价值。
HDFS中高可用性HA的讲解
HDFS Using QJM
HA使用的是分布式的日志管理方式
一:概述
1.背景
如果namenode出现问题,整个HDFS集群将不能使用。
是不是可以有两个namenode呢
一个为对外服务->active
一个处于待机->standby
他们的之间共享的元数据交 nameservice
2.HDFS HA的几大中重点
1)保证两个namenode里面的内存中存储的文件的元数据同步
->namenode启动时,会读镜像文件
2)变化的记录信息同步
3)日志文件的安全性
->分布式的存储日志文件
->2n+1个,使用副本数保证安全性
->使用zookeeper监控
->监控两个namenode,当一个出现了问题,可以达到自动故障转移。
->如果出现了问题,不会影响整个集群
->zookeeper对时间同步要求比较高。
4)客户端如何知道访问哪一个namenode
->使用proxy代理
->隔离机制
->使用的是sshfence
->两个namenode之间无密码登录
5)namenode是哪一个是active
->zookeeper通过选举选出zookeeper。
->然后zookeeper开始监控,如果出现文件,自动故障转移。
二:准备
3.规划集群
namenode namenode
journalnode journalnode journalnode -->日志的分布,这是日志节点,考虑的是日志的安全性。
datanode datanode datanode
4.关闭所有的进程
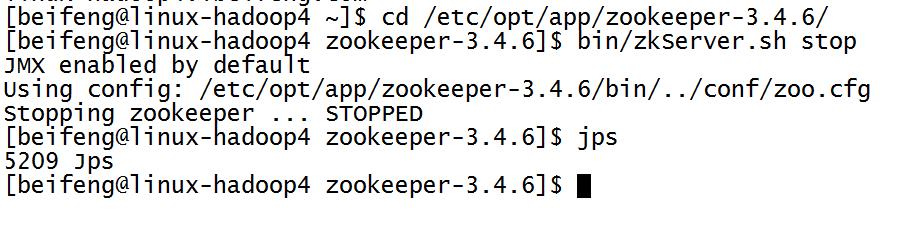
5.保存分布式的源数据,复制一份用来HDFS HA的检测。
先是第一台,先将分布式的etc/hadoop,保存为dist-hadoop,保存源数据。
同时,新建tmp。
至于第二台以及第三台,在分发之间再进行配置。

三:配置文件
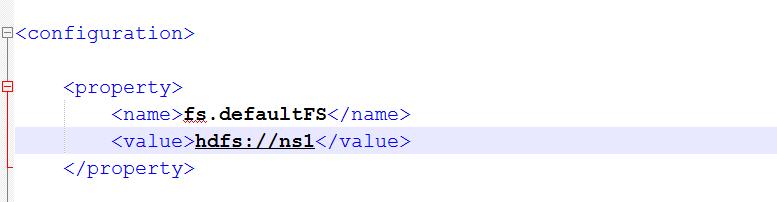
6.将core-site.xml中的文件系统删除,并添加新的文件系统
以前的是使用是配置一台,现在配置多态namenode,使用的方式是nameservices的名称的方式。
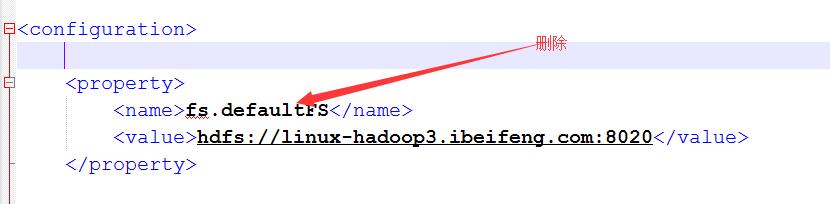
添加配置
7.配置hdfs-site.xml
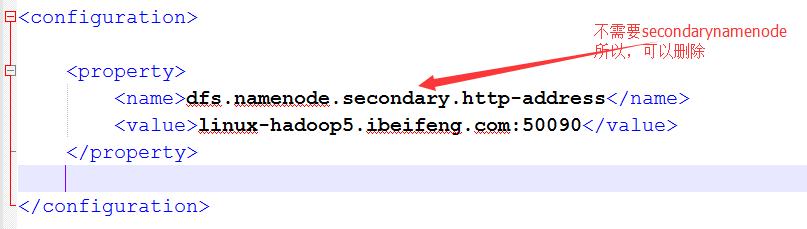
8.继续配置hdfs-site.xml
dfs.nameservices的配置

dfs.ha.namenodes.[nameservice ID]的配置
包括rpc,http的namenodde地址。

dfs.namenode.shared.edits.dir的配置
这是journalnode的地址

dfs.journalnode.edits.dir 的配置
这是journalnode的日志存储的目录
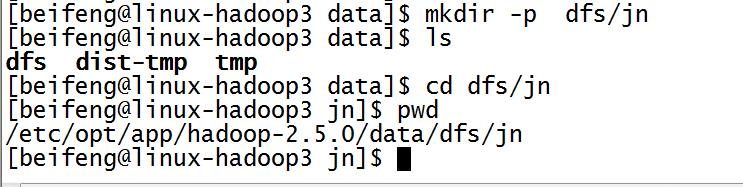
先新建目录:

dfs.client.failover.proxy.provider的配置

dfs.ha.fencing.methods的配置
使用的方式为ssh拦截

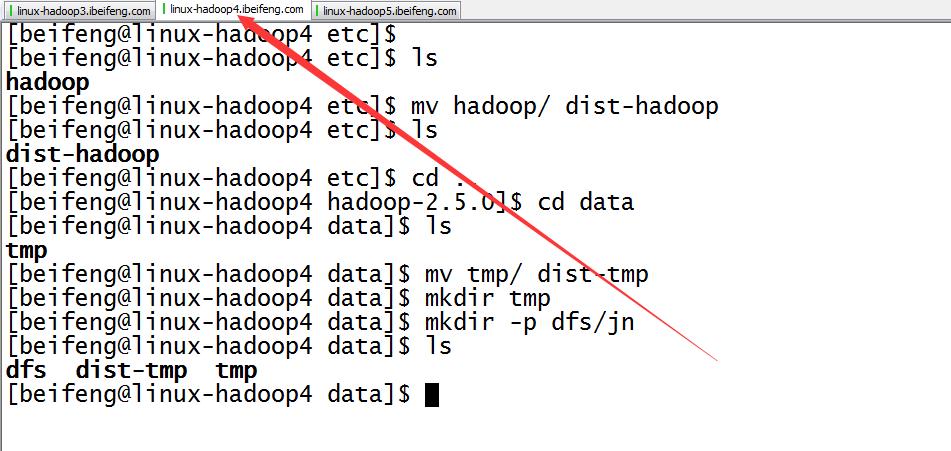
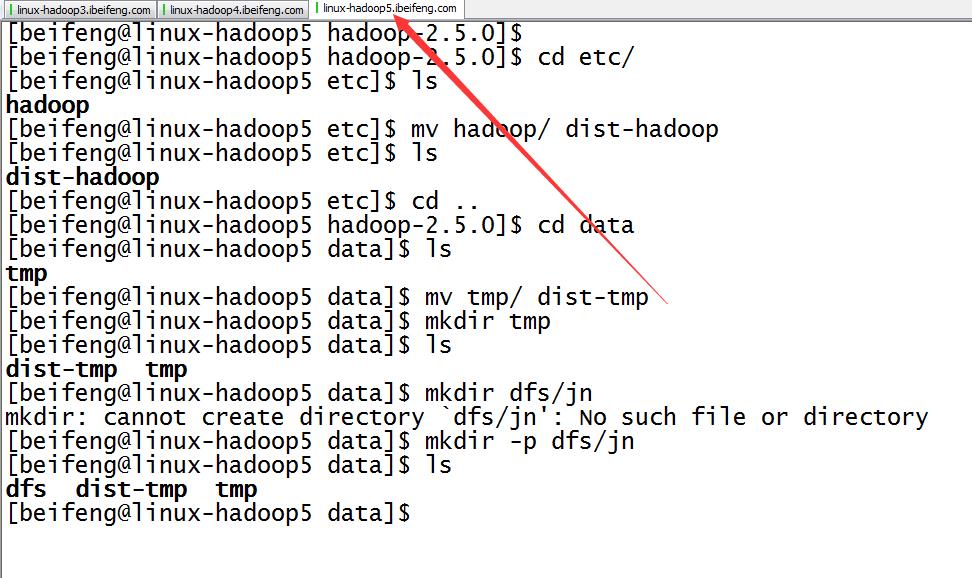
9.配置完成,在分发之前先进行的是目录的规划
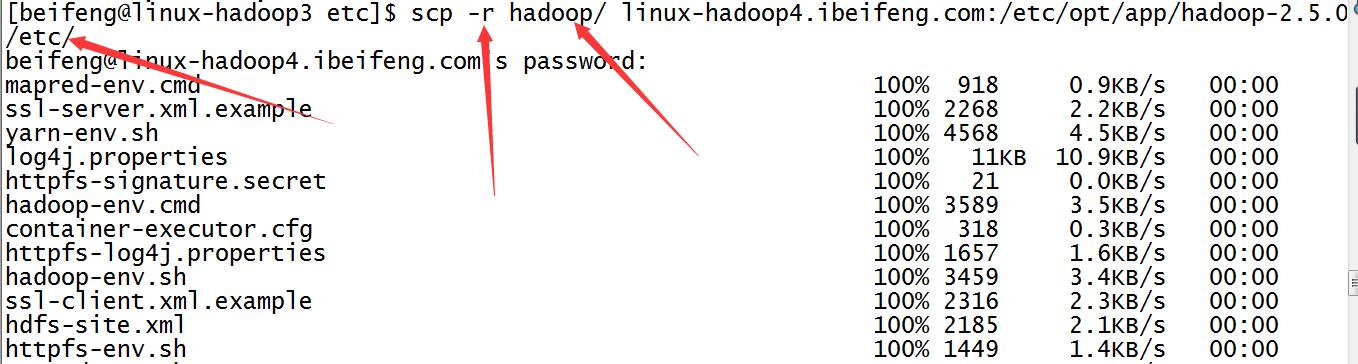
10.分发
四:启动
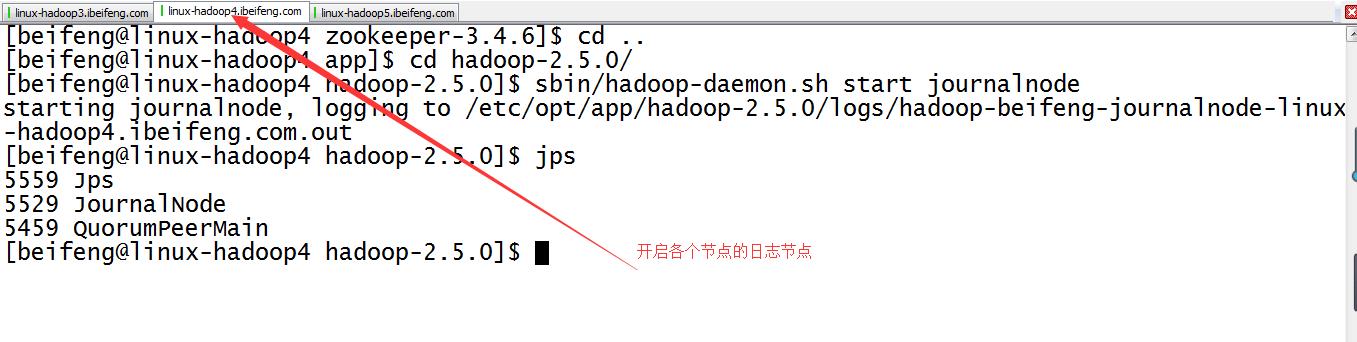
11.启动三台的日志节点

12.格式化第一台虚拟机
因为是共享数据,所以格式化一台虚拟机即可。

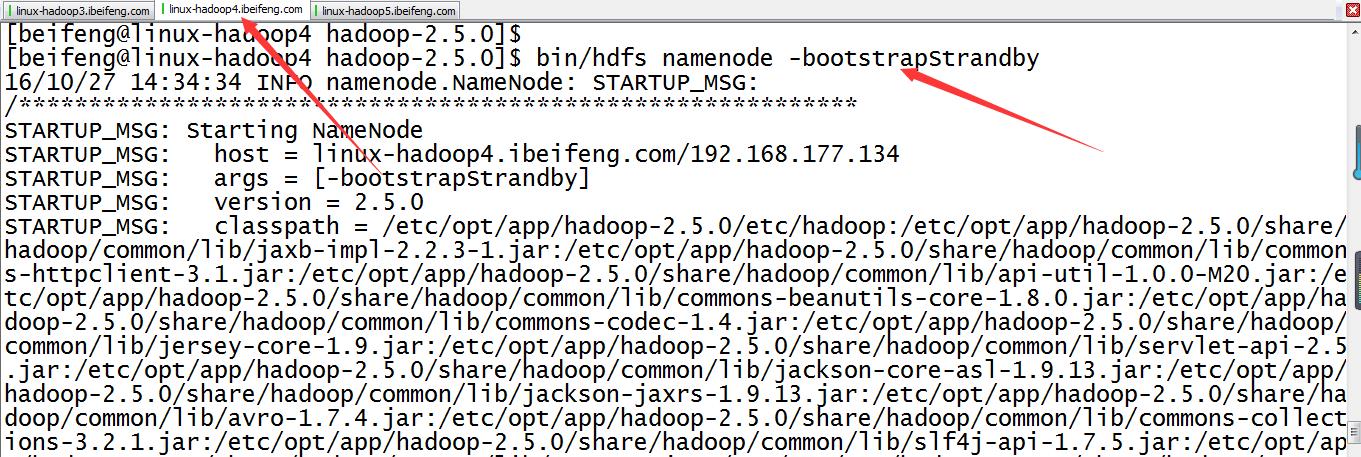
13.紧接着,同步元数据(在第二台上写命令)
最好是bin/hdfs namenode -help查看
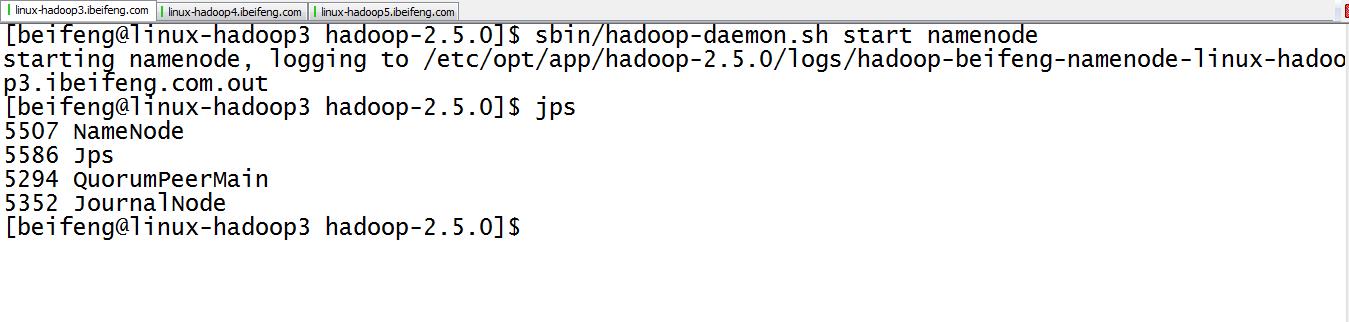
14.启动namenode(两台虚拟机)
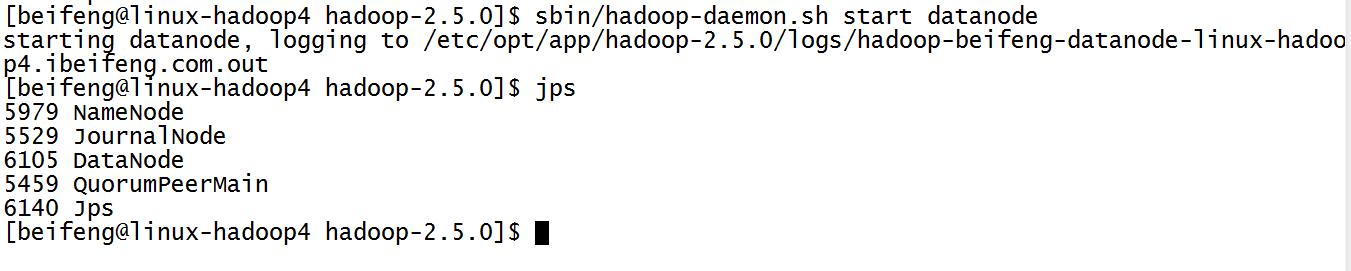
15.启动三台了datanode
16.观看两台的启动状态
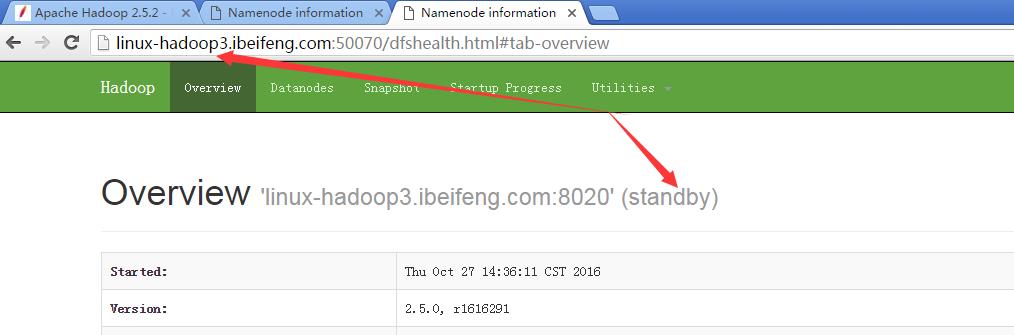
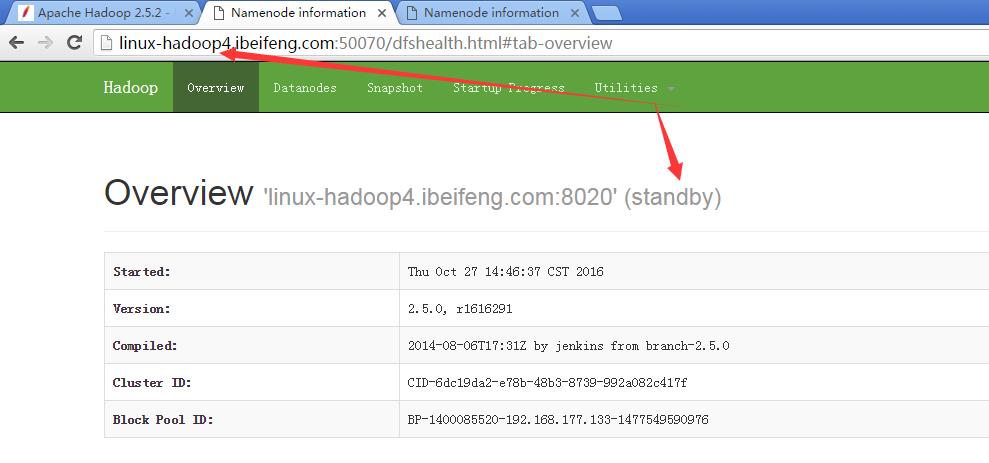
17.强制切换状态
1)、查找帮助命令,属于bin/hdfs haadmin
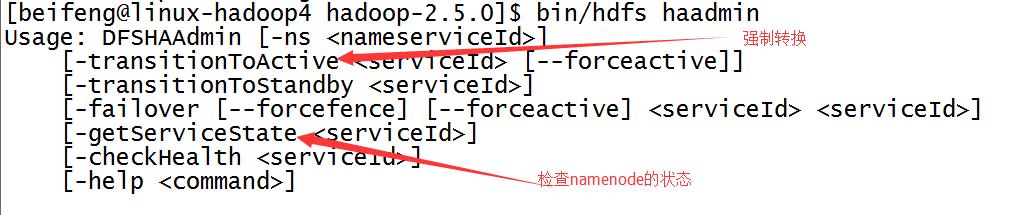
2)、具体命令

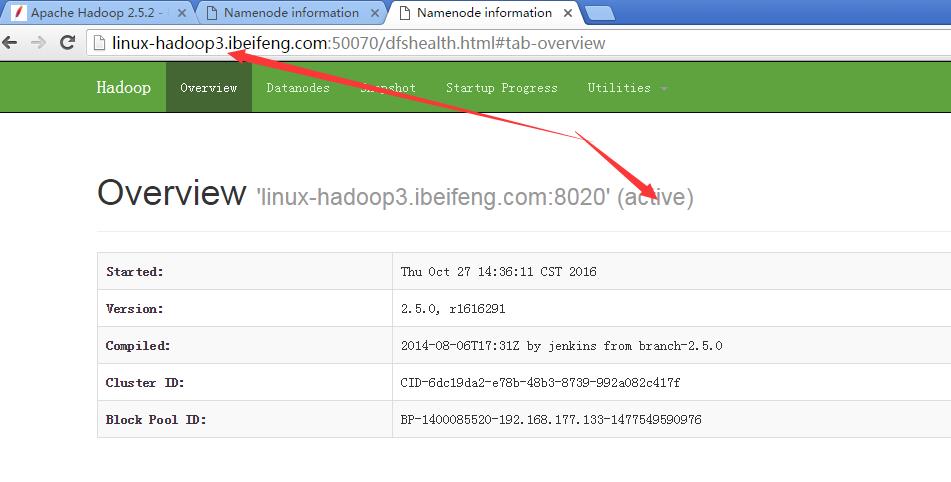
18.结果
1)、

2)、
五:再次测试
19.在HDFS上新建目录并上传文件

20.杀死第一台的namenode,进行测试

21.将avtove的状态切换到第二台

22.看第一台是否可以观看hdfs中的文件
如果可以,说明,HA发挥作用了。
因为这时proxy提供的接口变成nn2.
六:自动故障转移
前提:关闭所有的进程。
依赖:zookeeper的监控,组件为:ZKFC。
启动以后都是standby,选举一个active。
规划:
namenode namenode
ZKFC ZKFC
journalnode journalnode journalnode
datanode datanode datanode
23.配置core-site.xml
添加zookeeper的服务,包括主机名和端口号。

24.配置hdfs-site.xml
添加自动故障转移的使能。

25.分发

26.确定关闭所有的进程
这一步是开始的基础。
26.开启三台的zookeeper服务
先开启监控。

27.初始化HA在zookeeper中的状态bin/hdfs zkfc -formatZK
在zookepper上创建znode节点。
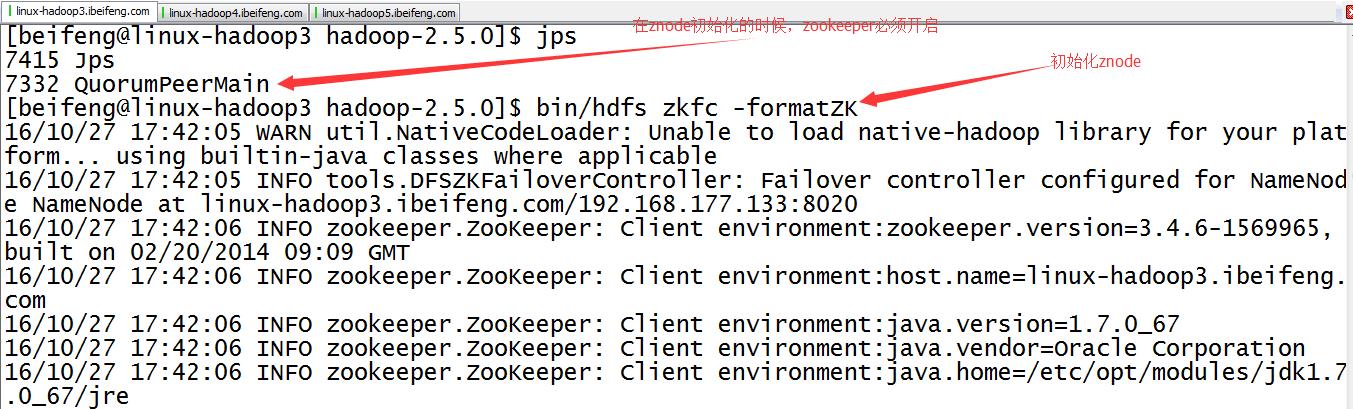
27.观察成功与否
进入zookeeper目录
命令:bin/zkCli.sh

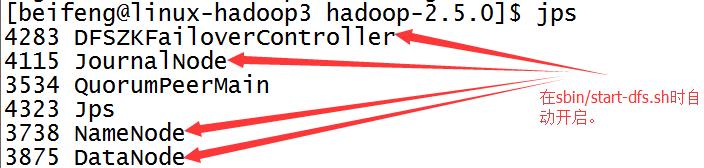
28.启动sbin/start-dfs.sh
前两台虚拟机会出现DFZKFailoverController。
如果没有开启DFZKFailoverController,可以手动开启,命令是sbin/hadoop-daemon.sh start zkfc。
七:简单检测
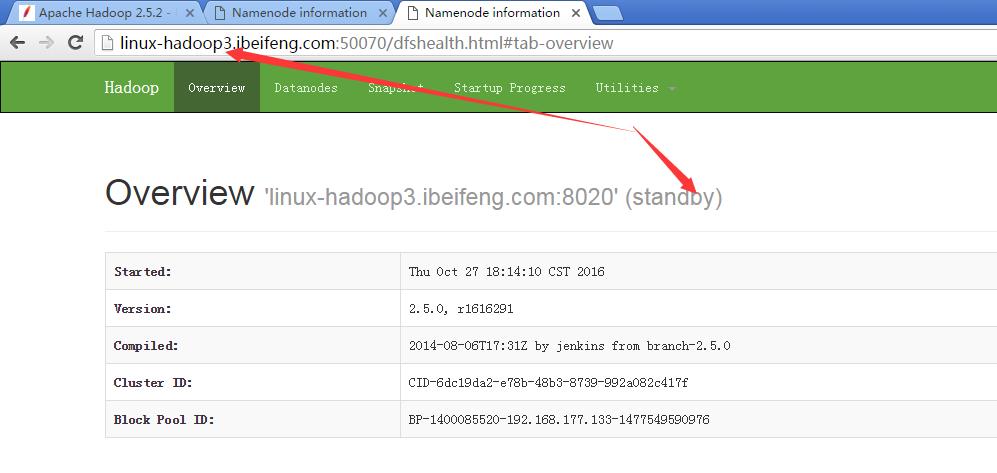
29.展示前两台的虚拟机状态

30.杀死第二台的虚拟机
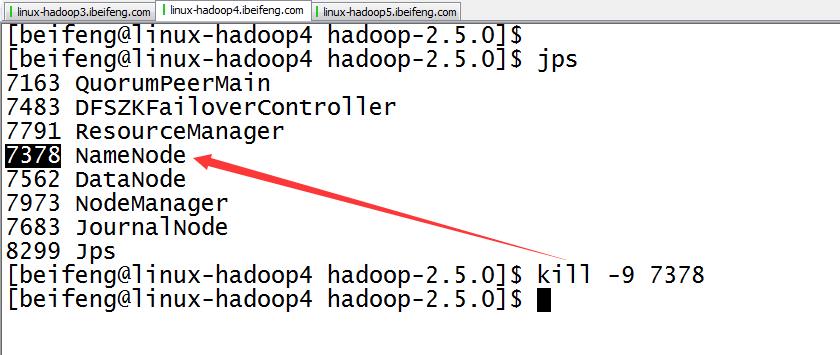
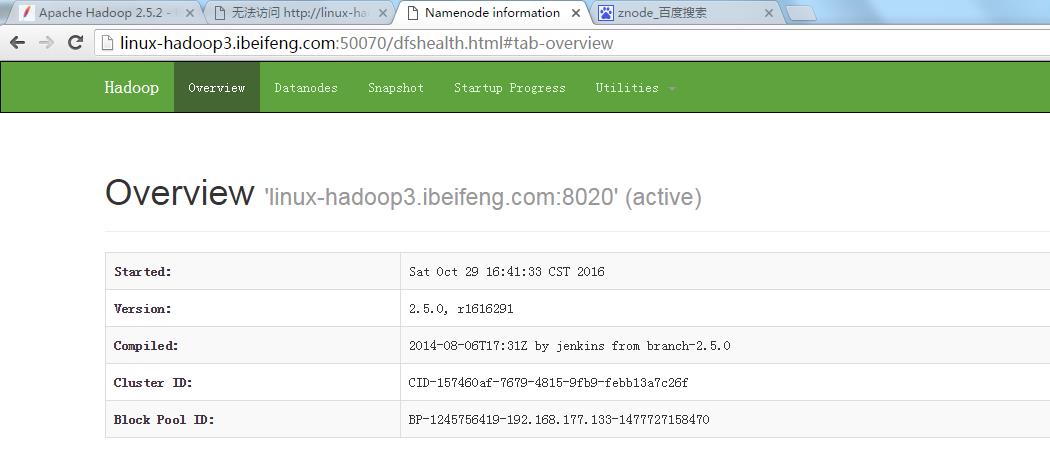
31.结果
这时,第一台虚拟机变成active。
以上是关于HDFS中高可用性HA的讲解的主要内容,如果未能解决你的问题,请参考以下文章