Kaggle入门之泰塔尼克之灾
Posted 胖咸鱼y
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kaggle入门之泰塔尼克之灾相关的知识,希望对你有一定的参考价值。
数据的探索和可视化 ====》 基础模型的构建 ====》 优化和调整
1、数据的探索和可视化
(1)包的导入
#导入包 #Pandas import pandas as pd from pandas import Series,DataFrame #Numpy,Matplotlib import numpy as np import matplotlib.pyplot as plt import seaborn as sns
(2)加载数据及其数据的总体描述
train_df = pd.read_csv("train.csv") test_df = pd.read_csv("test.csv") train_df.info() print("========我是分割线============") test_df.info()

#看一下数据的样子
train_df.head()
print("*******************")
test_df.head()
在这一步发现数据有缺失的情况。分别是训练集的“Age”,“Cabin”和“Embarked,测试集的“Age”,“Fare”和“Cabin”。其中“Embarked”和“Fare”缺失不明显。
留意数据类型有float,int和string类型。
(3)可视化作图找直观感受
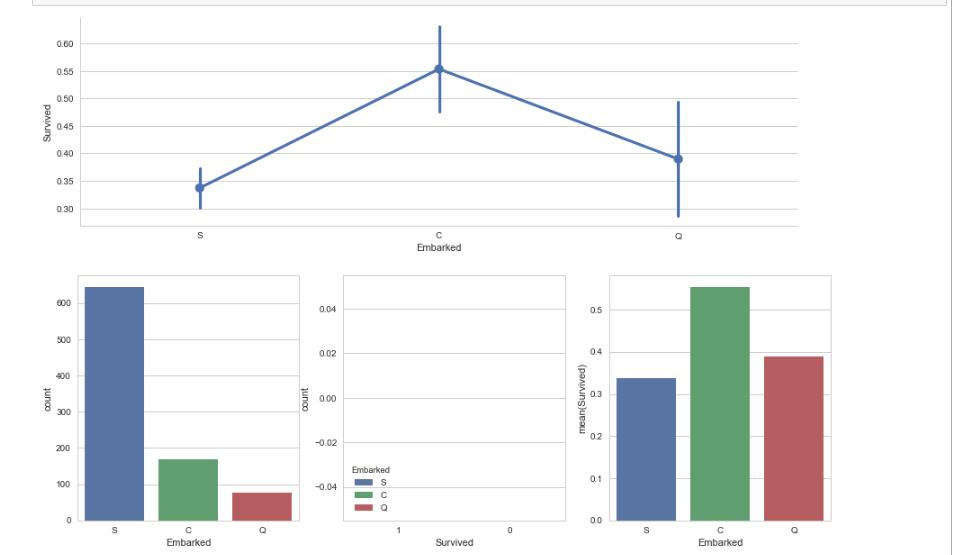
#对训练数据进行补全 ---> Embraked train_df.Embarked.fillna("S") #plot sns.factorplot(\'Embarked\',\'Survived\',data = train_df,size=4,aspect=3) #新学习一种画图的方法 fig,(axis1,axis2,axis3) = plt.subplots(1,3,figsize=(15,5)) sns.factorplot(\'Embarked\',data = train_df,kind=\'count\',order=[\'S\',\'C\',\'Q\'],ax=axis1) sns.factorplot(\'Survived\',hue=\'Embarked\',data = train_df,kind=\'count\',order=[\'1\',\'0\'],ax=axis2) embarked_perc = train_df[["Embarked","Survived"]].groupby(["Embarked"],as_index=False).mean() sns.barplot(x=\'Embarked\',y=\'Survived\',data=embarked_perc,order=[\'S\',\'C\',\'Q\'],ax=axis3) plt.show() #简单来看C港口登船的生存率更高
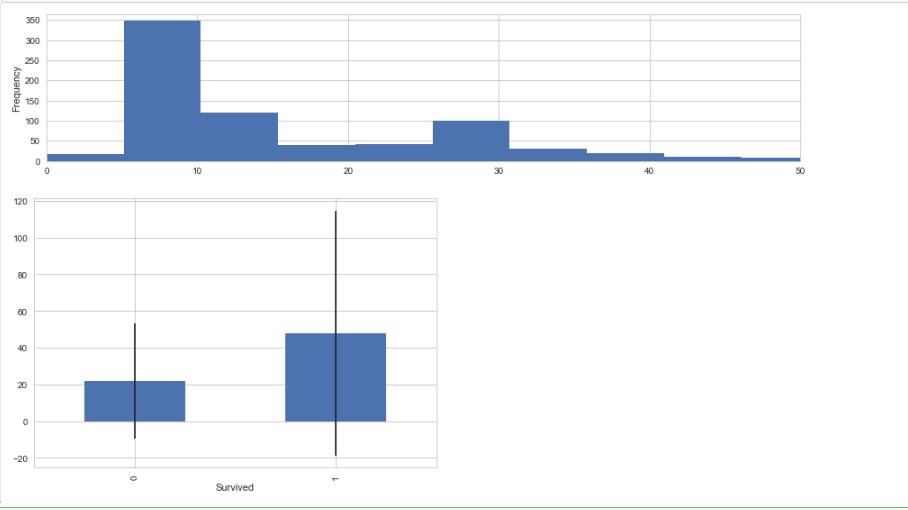
#Fare的补全 test_df["Fare"].fillna(test_df["Fare"].median(), inplace=True) #转换成int格式 train_df.Fare = train_df.Fare.astype(int) test_df.Fare = test_df.Fare.astype(int) fare_not_survived = train_df.Fare[train_df.Survived == 0] fare_survived = train_df.Fare[train_df.Survived == 1] #查看有无Fare对是否生存的影响 average_fare = DataFrame([fare_not_survived.mean(),fare_survived.mean()]) std_fare = DataFrame([fare_not_survived.std(),fare_survived.std()]) train_df[\'Fare\'].plot(kind=\'hist\', figsize=(15,3),bins=100, xlim=(0,50)) average_fare.index.names = std_fare.index.names = ["Survived"] average_fare.plot(yerr=std_fare,kind=\'bar\',legend=False) plt.show()
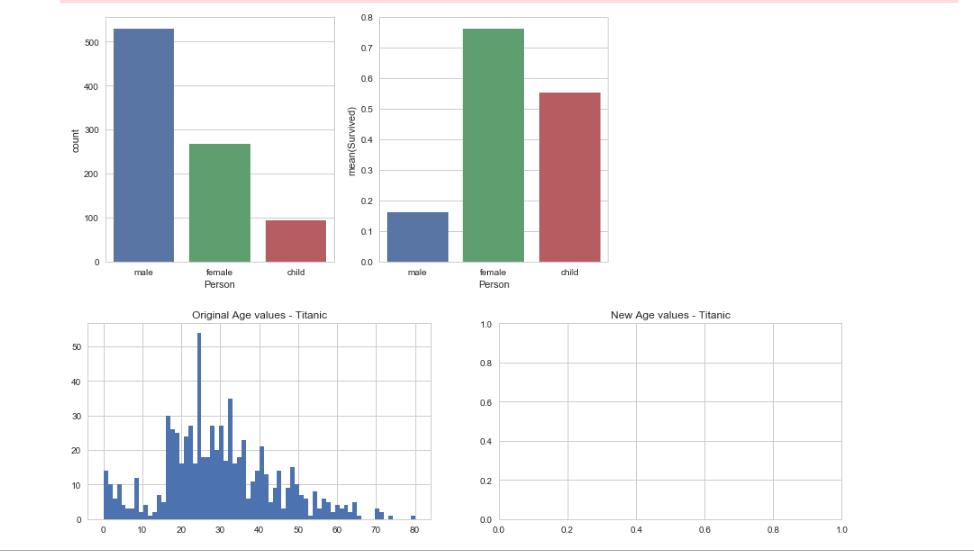
#年龄的补足和可视化 #方法一 fig,(axis1,axis2) = plt.subplots(1,2,figsize=(15,4)) axis1.set_title(\'Original Age values - Titanic\') axis2.set_title(\'New Age values - Titanic\') average_age_titanic = train_df["Age"].mean() std_age_titanic = train_df["Age"].std() count_nan_age_titanic = train_df["Age"].isnull().sum() average_age_test = test_df["Age"].mean() std_age_test = test_df["Age"].std() count_nan_age_test = test_df["Age"].isnull().sum() rand_1 = np.random.randint(average_age_titanic - std_age_titanic, average_age_titanic + std_age_titanic, size = count_nan_age_titanic) rand_2 = np.random.randint(average_age_test - std_age_test, average_age_test + std_age_test, size = count_nan_age_test) train_df[\'Age\'].dropna().astype(int).hist(bins=70, ax=axis1) train_df["Age"][np.isnan(train_df["Age"])] = rand_1 test_df["Age"][np.isnan(test_df["Age"])] = rand_2 train_df[\'Age\'] = train_df[\'Age\'].astype(int) test_df[\'Age\'] = test_df[\'Age\'].astype(int) plt.show()
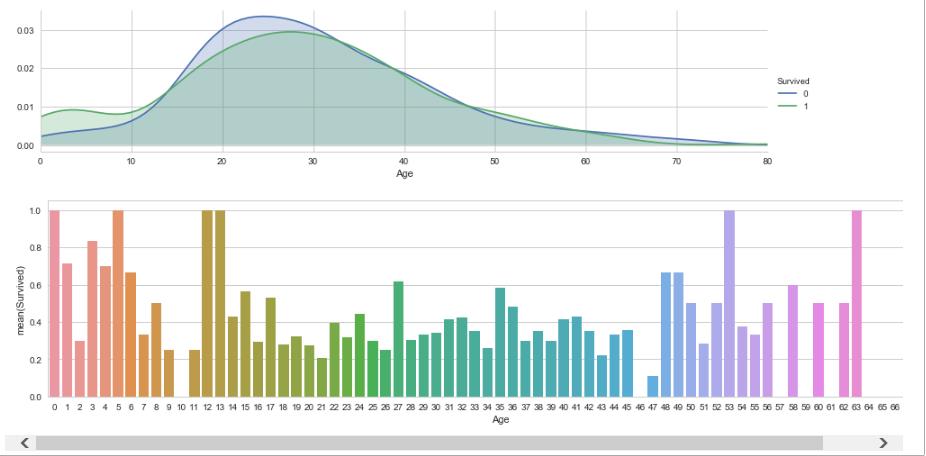
#年龄和生存的关系 facet = sns.FacetGrid(train_df,hue=\'Survived\',aspect =4) facet.map(sns.kdeplot,\'Age\',shade = True) facet.set(xlim=(0,train_df.Age.max())) facet.add_legend() fig, axis1 = plt.subplots(1,1,figsize=(18,4)) average_age = train_df[["Age", "Survived"]].groupby([\'Age\'],as_index=False).mean() sns.barplot(x=\'Age\', y=\'Survived\', data=average_age) plt.show()
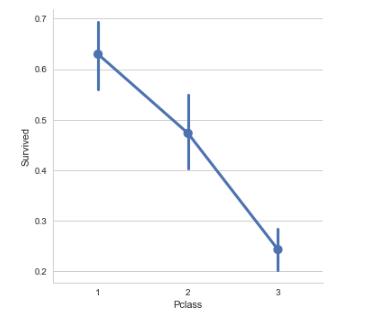
#Pclass对生存的影响 sns.factorplot(\'Pclass\',\'Survived\',order = [1,2,3],data=train_df,size=5) plt.show()
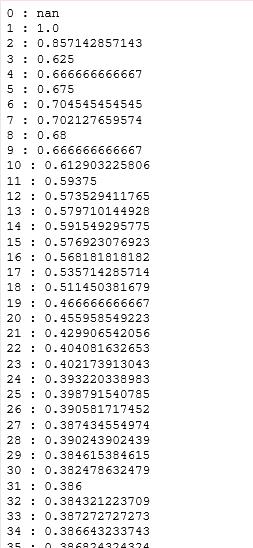
#从年龄看生存率 for i in range(100):
g = train_df.Name[train_df.Age<i]
rate = g[train_df.Survived==1].count()/g.count()
print(i,":",rate)
2、基础模型的搭建
在第一个环节中不难发现除了Name和Ticket看不出显著影响,其他的因素均放在初始模型中。
(1)数据处理:Age的随机森林补全
#采用随机森林补充Age def age_filled(df): age_df = df[["Age","Pclass","SibSp","Fare","Parch"]] know_age = age_df[age_df.Age.notnull()].as_matrix() unknow_age = age_df[age_df.Age.isnull()].as_matrix() X = know_age[:,1:] y = know_age[:,0] rfr = rfr = RandomForestRegressor(random_state=0, n_estimators=2000, n_jobs = -1) rfr.fit(X,y) predict_age = rfr.predict(unknow_age[:,1:]) df.loc[ (df.Age.isnull()), \'Age\' ] = predict_age return df
#Age 的补全 age_filled(train_df) age_filled(test_df)
#按照有没有Cabin分为Yes和No def cabin_filled(df): df.loc[(df.Cabin.isnull()),\'Cabin\'] = "No" df.loc[(df.Cabin.notnull()),\'Cabin\'] = "Yes" return df
#Cabin的补全 cabin_filled(train_df) cabin_filled(test_df)
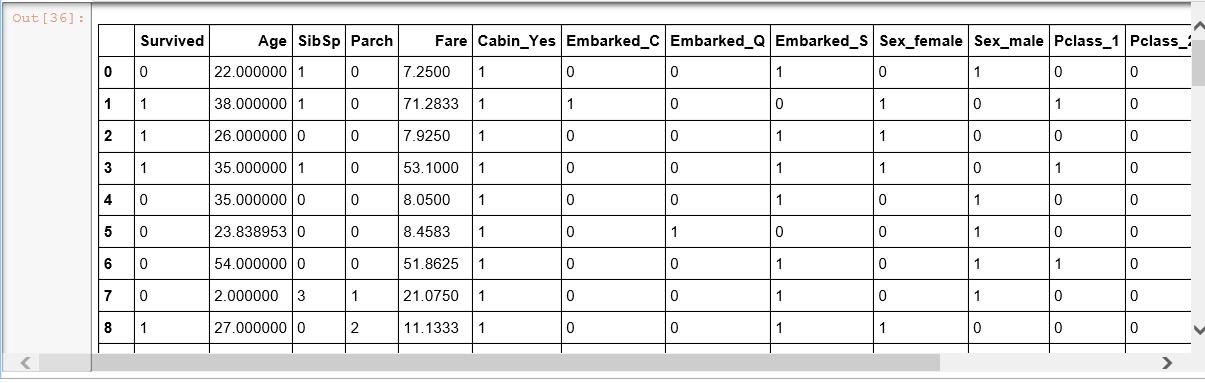
补全结果:
2)为了方便建模,把一些属性因子化。
dummies_Cabin = pd.get_dummies(train_df[\'Cabin\'], prefix= \'Cabin\') dummies_Embarked = pd.get_dummies(train_df[\'Embarked\'], prefix= \'Embarked\') dummies_Sex = pd.get_dummies(train_df[\'Sex\'], prefix= \'Sex\') dummies_Pclass = pd.get_dummies(train_df[\'Pclass\'], prefix= \'Pclass\') df = pd.concat([train_df, dummies_Cabin, dummies_Embarked, dummies_Sex, dummies_Pclass], axis=1) df.drop([\'Pclass\', \'Sex\', \'Cabin\', \'Embarked\'], axis=1, inplace=True)
3)Age和Fare正则化方便跑模型。[ 缩放到 [-1,1] ]
import sklearn.preprocessing as preprocessing age_df = df[["Age"]] #注意爽括号,否则会报reshape的错误 fare_df = df[["Fare"]] scaler = preprocessing.StandardScaler() age_scale_param = scaler.fit(age_df) df[\'Age_scaled\'] = scaler.fit_transform(age_df, age_scale_param) fare_scale_param = scaler.fit(fare_df) df[\'Fare_scaled\'] = scaler.fit_transform(fare_df, fare_scale_param)
到这里,基本的数据处理完成(对test的处理略去,过程相同)
4)开始跑基础模型,采用RandomForestRegressor
#使用随机森林法建模 from sklearn import linear_model # 用正则取出我们要的属性值 train_df = df.filter(regex=\'Survived|Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*\') train_np = train_df.as_matrix() # y即Survival结果 y = train_np[:, 0] # X即特征属性值 X = train_np[:, 1:] # fit到RandomForestRegressor之中 clf = linear_model.LogisticRegression(C=1.0, penalty=\'l1\', tol=1e-6) clf.fit(X, y) clf

test = df_test.filter(regex=\'Age_.*|SibSp|Parch|Fare_.*|Cabin_.*|Embarked_.*|Sex_.*|Pclass_.*\') predictions = clf.predict(test) #看属性 pd.DataFrame({"columns":list(train_df.columns)[1:], "coef":list(clf.coef_.T)})
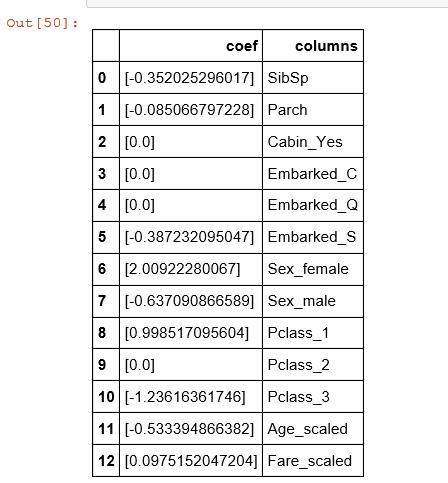
5)提交
submission = pd.DataFrame({ "PassengerId": df_test["PassengerId"], "Survived": predictions }) submission.to_csv(\'titanic.csv\', index=False)
到这里基础的模型完成。第一次提交排名到6K+,接下来就是对模型的进一步优化。
以上是关于Kaggle入门之泰塔尼克之灾的主要内容,如果未能解决你的问题,请参考以下文章