深入认识XmlReader
Posted 大城小梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入认识XmlReader相关的知识,希望对你有一定的参考价值。
深入认识XmlReader
摘要
XmlReader类是组成.NET的关键技术之一,极大地方便了开发人员对Xml的操作。通过本文您将对XmlReader有一个很好的认识,并将其应用到实际开发中。
目录
1.概要
XmlReader 类是一个提供对 XML 数据的非缓存、只进只读访问的抽象基类。该类符合 W3C 可扩展标记语言 (XML) 1.0 和 XML 中的命名空间的建议。
XmlReader 类支持从流或文件读取 XML 数据。该类定义的方法和属性使您可以浏览数据并读取节点的内容。
XmlReader类是一个抽象类,XmlTextReader,XmlValidatingReader,和XmlNodeReader类都继承自XmlReader类。XmlReader类有很多方法和属性用来读取XML文件的内容、查找XML元素的深度、判断当前元素的内容是否为空,以及导航XML的属性等。
2.创建Xml读取器
我们可以通过Create方法来创建一个XmlReader实例,也可以通过XmlReaderSettings类来配置XmlReader对象。使用XmlReaderSettings类的属性启用或禁用XmlReader对象的特定功能,然后将XmlReaderSettings对象传递给Create方法。
MSDN建议:
尽管在 .NET Framework 2.0 版中,Microsoft .NET Framework 包括 XmlReader 类的具体实现,例如 XmlTextReader、XmlNodeReader 和 XmlValidatingReader类,但是,我们建议您使用 Create 方法创建 XmlReader 实例。
通过使用 Create 方法和 XmlReaderSettings 类,您将得到下列好处:
- 可以指定要在所创建的 XmlReader 对象上支持的功能。
- XmlReaderSettings 类可以重复使用,以创建多个读取器对象。可以使用相同的设置创建多个具有相同功能的读取器。另外,可以修改 XmlReaderSettings 对象并创建具有不同功能集的新读取器。
- 可以将功能添加到现有读取器中。Create 方法可以接受其他 XmlReader 对象。基础 XmlReader 对象可以是用户定义的读取器或 XmlTextReader 对象,也可以是要添加附加功能的另一个 XmlReader 实例。
- 充分利用 .NET Framework 2.0 版本的 XmlReader 类中增加的所有新功能。某些功能只能在通过 Create 方法创建的 XmlReader 对象上使用,例如更好的一致性检查以及与 XML 1.0 建议的一致性。
提示:XmlReaderSettings 类的属性设置可以参考:http://msdn.microsoft.com/zh-cn/library/9khb6435(v=vs.80).aspx
实例化XmlReader:
1 XmlReaderSettings settings = new XmlReaderSettings(); 2 settings.ConformanceLevel = ConformanceLevel.Fragment; 3 settings.IgnoreWhitespace = true; 4 settings.IgnoreComments = true; 5 XmlReader reader = XmlReader.Create("books.xml", settings);
3.访问外部资源
XmlResolver类用于定位并访问XmlReader对象所需的任何资源。XmlResolver可以用于执行以下操作:
- 定位并打开 XML 实例文档。
- 定位并打开 XML 实例文档所引用的任何外部资源。其中可以包括实体、文档类型定义、架构等。
- 如果资源存储在要求身份验证的系统上,System.Xml.XmlResolver.Credentials 属性可以用于指定必要的凭据。
注意:如果未指定 XmlResolver,创建的读取器将使用没有用户凭据的默认 XmlUrlResolver。XmlUrlResover解析由统一资源标识符 (URI) 命名的外部 XML 资源,是 System.Xml 命名空间中的所有类的默认解析器。
以下代码创建一个 XmlReader 实例,使用具有默认凭据的 XmlUrlResolver。

1 // Create a resolver with default credentials.2 XmlUrlResolver resolver = new XmlUrlResolver(); 3 resolver.Credentials = System.Net.CredentialCache.DefaultCredentials; 4 5 // Set the reader settings object to use the resolver.6 settings.XmlResolver = resolver; 7 8 // Create the XmlReader object.9 XmlReader reader = XmlReader.Create("http://ServerName/data/books.xml", settings);
4.读取数据
读取数据是处理XML文件最终目的,因此也是本文最重要的部分。下面将详细讨论如何通过XmlReader来读取Xml数据。
4.1 当前节点位置
XmlReader 类提供了对 XML 流或文件的只进访问。当前节点是读取器当前所处的 XML 节点。所有调用的方法和执行的操作与当前节点相关,所有检索到的属性反映当前节点的值。
读取器通过调用一种读取方法(read方法)前进。重复调用该读取方法可以将读取器移至下一个节点。此类调用通常在 While 循环内执行。
下面的示例显示了如何在流中定位来确定当前的节点类型。

 View Code
View Code
1 reader.MoveToContent(); 2 // Parse the file and display each of the nodes. 3 while (reader.Read()) { 4 switch (reader.NodeType) { 5 case XmlNodeType.Element: 6 Console.Write("<{0}>", reader.Name); 7 break; 8 case XmlNodeType.Text: 9 Console.Write(reader.Value); 10 break; 11 case XmlNodeType.CDATA: 12 Console.Write("<![CDATA[{0}]]>", reader.Value); 13 break; 14 case XmlNodeType.ProcessingInstruction: 15 Console.Write("<?{0} {1}?>", reader.Name, reader.Value); 16 break; 17 case XmlNodeType.Comment: 18 Console.Write("<!--{0}-->", reader.Value); 19 break; 20 case XmlNodeType.XmlDeclaration: 21 Console.Write("<?xml version=\'1.0\'?>"); 22 break; 23 case XmlNodeType.Document: 24 break; 25 case XmlNodeType.DocumentType: 26 Console.Write("<!DOCTYPE {0} [{1}]", reader.Name, reader.Value); 27 break; 28 case XmlNodeType.EntityReference: 29 Console.Write(reader.Name); 30 break; 31 case XmlNodeType.EndElement: 32 Console.Write("</{0}>", reader.Name); 33 break; 34 } 35 }
提示:XmlNodeType为节点类型,详细信息可参考http://msdn.microsoft.com/zh-cn/library/3k5w5zc3(v=vs.80).aspx
4.2 读取元素
下表介绍 XmlReader 类为处理元素提供的方法和属性。
|
成员名称 |
说明 |
|---|---|
|
IsStartElement |
检查当前节点是否是开始标记或空的元素标记。 |
|
ReadStartElement |
检查当前节点是否为元素并将读取器推进到下一个节点。 |
|
ReadEndElement |
检查当前节点是否为结束标记并将读取器推进到下一个节点。 |
|
ReadElementString |
读取纯文本元素。 |
|
ReadToDescendant |
将 XmlReader 前进到具有指定名称的下一个子代元素。 |
|
ReadToNextSibling |
将 XmlReader 前进到具有指定名称的下一个同辈元素。 |
|
IsEmptyElement |
检查当前元素是否包含空的元素标记。此属性使您能够确定下面各项之间的差异:
也就是说,IsEmptyElement 只是报告源文档中的元素是否包含结束元素标记。 |
以下代码使用 ReadStartElement 和 ReadString 方法读取元素。
1 using (XmlReader reader = XmlReader.Create("book3.xml")) { 2 3 // Parse the XML document. ReadString is used to 4 // read the text content of the elements. 5 reader.Read(); 6 reader.ReadStartElement("book"); 7 reader.ReadStartElement("title"); 8 Console.Write("The content of the title element: "); 9 Console.WriteLine(reader.ReadString()); 10 reader.ReadEndElement(); 11 reader.ReadStartElement("price"); 12 Console.Write("The content of the price element: "); 13 Console.WriteLine(reader.ReadString()); 14 reader.ReadEndElement(); 15 reader.ReadEndElement(); 16 17 }
4.3 读取属性
XmlReader 类提供了各种方法和属性来读取属性。属性在元素上最常见。但是,XML 声明和文档类型节点上也允许使用属性。
在位于某个元素节点上时,使用 MoveToAttribute 方法可以浏览该元素的属性列表。调用了 MoveToAttribute 之后,节点属性(例如 Name、NamespaceURI、Prefix 等)将反映该属性的属性,而不是其所属的包含元素的属性。
下表介绍专门为处理属性而设计的方法和属性。
| 成员名 | 说明 |
|---|---|
|
AttributeCount |
获取元素的属性列表。 |
|
GetAttribute |
获取属性的值。 |
|
HasAttributes |
获取一个值,该值指示当前节点是否有任何属性。 |
|
IsDefault |
获取一个值,该值指示当前节点是否是从 DTD 或架构中定义的默认值生成的属性。 |
|
Item |
获取指定属性的值。 |
|
MoveToAttribute |
移动到指定的属性。 |
|
MoveToElement |
移动到拥有当前属性节点的元素。 |
|
MoveToFirstAttribute |
移动到第一个属性。 |
|
MoveToNextAttribute |
移动到下一个属性。 |
|
ReadAttributeValue |
将属性值分析为一个或多个 Text、EntityReference 或 EndEntity 节点。 |
实例1:使用 AttributeCount 属性读取某个元素的所有属性。
1 // Display all attributes.2 if (reader.HasAttributes) { 3 Console.WriteLine("Attributes of <" + reader.Name + ">"); 4 for (int i = 0; i < reader.AttributeCount; i++) { 5 Console.WriteLine(" {0}", reader[i]); 6 } 7 // Move the reader back to the element node.8 reader.MoveToElement(); 9 }
实例2:在 While 循环中使用 MoveToNextAttribute 属性读取某个元素的所有属性。
1 if (reader.HasAttributes) { 2 Console.WriteLine("Attributes of <" + reader.Name + ">"); 3 while (reader.MoveToNextAttribute()) { 4 Console.WriteLine(" {0}={1}", reader.Name, reader.Value); 5 } 6 // Move the reader back to the element node.7 reader.MoveToElement(); 8 }
实例3:按名称获取属性的值。
1 reader.ReadToFollowing("book"); 2 string isbn = reader.GetAttribute("ISBN"); 3 Console.WriteLine("The ISBN value: " + isbn);
提示:ReadToFollowing方法表示一直读取,直到找到具有指定限定名的元素。使用此方法可以提高在 XML 文档中查找命名元素的速度。 如果找到匹配的元素,它让读取器前进到与指定名称匹配的下一个后续元素,并返回 true。
4.4 读取内容
1. 使用Value属性
Value 属性可以用于获取当前节点的文本内容。返回的值取决于当前节点的节点类型。下表介绍每种可能的节点类型所返回的内容。
| 节点类型 | 值 |
|---|---|
|
Attribute |
属性的值。 |
|
CDATA |
CDATA 节的内容。 |
|
Comment |
注释的内容。 |
|
DocumentType |
内部子集。 |
|
ProcessingInstruction |
全部内容(不包括指令目标)。 |
|
SignificantWhitespace |
混合内容模型中任何标记之间的空白。 |
|
Text |
文本节点的内容。 |
|
Whitespace |
标记之间的空白。 |
|
XmlDeclaration |
声明的内容。 |
|
所有其他节点类型 |
空字符串。 |
2.利用ReadString方法
ReadString 方法以字符串的形式返回元素或文本节点的内容。
如果 XmlReader 位于某个元素上,ReadString 将所有文本、有效空白、空白和 CDATA 节节点串联在一起,并以元素内容的形式返回串联的数据。当遇到任何标记时,读取器停止。这可以在混合内容模型中发生,也可以在读取元素结束标记时发生。
如果 XmlReader 位于某个文本节点上,ReadString 将对文本、有效空白、空白和 CDATA 节节点执行相同的串联。读取器在第一个不属于以前命名的类型的节点处停止。如果读取器定位在属性文本节点上,则 ReadString 与读取器定位在元素开始标记上时的功能相同。它返回所有串联在一起的元素文本节点。
3.利用ReadInnerXml方法
ReadInnerXml 方法返回当前节点的所有内容(包括标记)。不返回当前节点(开始标记)和对应的结束节点(结束标记)。例如,如果包含 XML 字符串 <node>this<child id="123"/></node>,ReadInnerXml 将返回 this<child id="123"/>。
| 节点类型 | 初始位置 | XML 片断 | 返回值 | 位于下列内容之后 |
|---|---|---|---|---|
|
Element |
在 item1 开始标记上。 |
<item1>text1</item1><item2>text2</item2> |
text1 |
在 item2 开始标记上。 |
|
Attribute |
在 attr1 属性节点上。 |
<item attr1="val1" attr2="val2">text</item> |
val1 |
保留在 attr1 属性节点上。 |
如果读取器定位在叶节点上,则调用 ReadInnerXml 等效于调用 Read。
4.利用ReadOuterXml方法
ReadOuterXml 方法返回当前节点及其所有子级的所有 XML 内容,包括标记。其行为与 ReadInnerXml 类似,只是同时还返回开始标记和结束标记。
使用上表中的值,如果读取器位于 item1 开始标记上,ReadOuterXml 将返回 <item1>text1</item1>。如果读取器位于 attr1 属性节点上,ReadOuterXml 将返回 attr1="val1"。
5. 一个简单实例
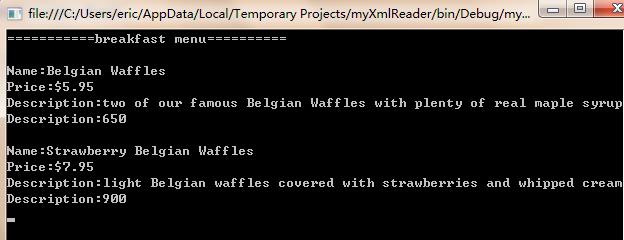
将菜单food.xml的数据解析,并按一定的格式显示出来。
food.xml数据格式如下:
1 <?xml version="1.0" encoding="utf-8" ?> 2 <breakfast_menu> 3 <food> 4 <name>Belgian Waffles</name> 5 <price>$5.95</price> 6 <description>two of our famous Belgian Waffles with plenty of real maple syrup</description> 7 <calories>650</calories> 8 </food> 9 <food> 10 <name>Strawberry Belgian Waffles</name> 11 <price>$7.95</price> 12 <description>light Belgian waffles covered with strawberries and whipped cream</description> 13 <calories>900</calories> 14 </food> 15 </breakfast_menu>
C#代码:
View Code
1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 using System.Xml; 6 7 namespace myXmlReader 8 { 9 class Program 10 { 11 static void Main(string[] args) 12 { 13 XmlReader reader = XmlReader.Create(@"E:\\kemi\\CodeNow\\Project\\XmlReader\\food.xml");//创建XmlReader实例14 15 while (reader.Read()) 16 { 17 if (reader.NodeType.Equals(XmlNodeType.Element))//判断节点类型18 { 19 switch (reader.Name) 20 { 21 22 case "breakfast_menu": 23 Console.WriteLine("===========breakfast menu=========="); 24 break; 25 case "name": 26 Console.WriteLine("Name:{0}", reader.ReadString());//使用ReadString读取数据27 break; 28 case "price": 29 Console.WriteLine("Price:{0}", reader.ReadString()); 30 break; 31 case "description": 32 Console.WriteLine("Description:{0}", reader.ReadInnerXml());//使用ReadInnerXml读取数据33 break; 34 case "calories": 35 Console.WriteLine("Description:{0}", reader.ReadInnerXml()); 36 break; 37 default: 38 Console.WriteLine(""); 39 break; 40 } 41 } 42 } 43 44 Console.Read(); 45 } 46 } 47 }
输出结果:
以上是关于深入认识XmlReader的主要内容,如果未能解决你的问题,请参考以下文章