类集框架解析
Posted 渊源谭
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了类集框架解析相关的知识,希望对你有一定的参考价值。
2017-08-20 16:30:32
常用集合的总结:
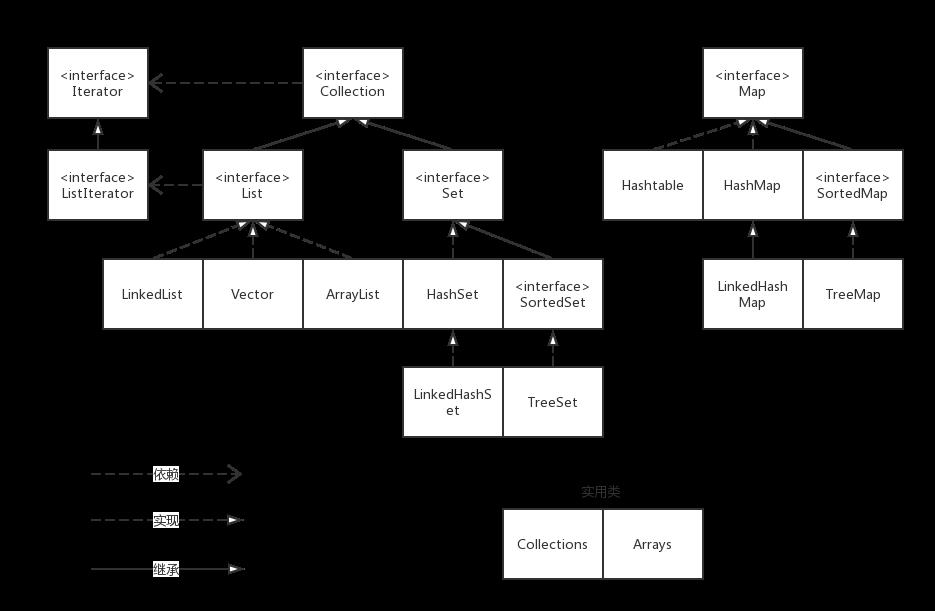
List:有序、可重复
Set:无序、不可重复
Map:将键映射到值的对象,一个映射不能包含重复的键,每个键最多只能映射到一个值
一、List(以ArrayList为例)
1)ArrayList.remove(int)按照下标删除,不会自动装箱
List list = new ArrayList(); list.add(1); list.add(2); list.add(2); list.add(2); list.add(3); list.add(4); list.add(5); list.remove(new Integer(5));//删除值为5的键值对 list.remove(1);//删除下标为1的键值对
2)迭代器遍历的同时,添加元素,并发修改异常,通过ListIterator解决
public static void print(List list){ ListIterator iter = list.listIterator(); while(iter.hasNext()){ Student s = (Student)iter.next(); if(s.getName().equals("Jack")) iter.add(new Student("Marry",20)); System.out.println(iter.next()); } }
3)遍历集合删除元素,使用Iterater.remove()操作(否则会报并发修改异常)
Iterator iter = list.iterator(); while(iter.hasNext()){ Integer i = (Integer)iter.next(); if(i == 5) iter.remove(); System.out.println(iter.next()); }
4)集合数组互转用Arrays.asList()/ArrayList.toArray() 但要注意:数组转化成集合Arrays.asList() 转化后的集合为固定长度,不可改变
5)List的三个子类的特点:
ArrayList:底层数据结构是数组,查询快,增删慢。线程不安全,效率高。
LinkedList:底层数据结构是链表,查询慢,增删快。线程不安全,效率高。
Vector:底层数据结构是数组,查询快,增删慢。线程安全,效率低。
二、Set
a) 我们使用Set集合都是需要去掉重复元素的, 如果在存储的时候逐个equals()比较, 效率较低,哈希算法提高了去重复的效率, 降低了使用equals()方法的次数
当HashSet调用add()方法存储对象的时候, 先调用对象的hashCode()方法得到一个哈希值, 然后在集合中查找是否有哈希值相同的对象 如果没有哈希值相同
的对象就直接存入集合 ,如果有哈希值相同的对象, 就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存。
b)TreeSet:有序,不可重复。可以指定一个顺序, 对象存入之后会按照指定的顺序排列
1)自然顺序(Comparable)
TreeSet类的add()方法中会把存入的对象提升为Comparable类型
调用对象的compareTo()方法和集合中的对象比较
根据compareTo()方法返回的结果进行存储
2)比较器顺序(Comparator)
创建TreeSet的时候可以指定一个Comparator
如果传入了Comparator的子类对象, 那么TreeSet就会按照比较器中的顺序排序
add()方法内部会自动调用Comparator接口中compare()方法排序
调用的对象是compare方法的第一个参数,集合中的对象是compare方法的第二个参数
3)两种方式的区别
TreeSet构造函数什么都不传, 默认按照类中Comparable的顺序(没有就报错ClassCastException)
TreeSet如果传入Comparator, 就优先按照Comparator
三、Map
1)HashMap和Hashtable的区别
Hashtable是JDK1.0版本出现的,是线程安全的,效率低;HashMap是JDK1.2版本出现的,是线程不安全的,效率高
Hashtable不可以存储null键和null值;HashMap可以存储null键和null值
2)LinkedHashMap:链表实现,存放顺序和取出顺序一致
3)TreeMap:可以根据键进行排序,排序规则的指定同TreeSet相同
4)Map的遍历方式(包含增强for循环)
public static void print1(Map map){ Set keys = map.keySet(); Iterator iter = keys.iterator(); while(iter.hasNext()){ Character key = (Character)iter.next(); Integer value = (Integer)map.get(key); System.out.println(key + ":" + value); } } public static void print2(Map map){ Set entrys = map.entrySet(); Iterator iter = entrys.iterator(); while(iter.hasNext()){ Map.Entry entry = (Map.Entry)iter.next(); Character key = (Character)entry.getKey(); Integer value = (Integer)entry.getValue(); System.out.println(key + ":" + value); } } public static void print3(Map map){ Set entry = map.entrySet(); for(Object entrys : entry){ Map.Entry entryss = (Map.Entry)entrys; System.out.println(entryss.getKey() + ":" + entryss.getValue()); } } public static void print4(Map map){ Set keys = map.keySet(); for(Object o : keys){ Character key = (Character)o; System.out.println(key + ":" + map.get(key)); }
以上是关于类集框架解析的主要内容,如果未能解决你的问题,请参考以下文章
JDK类集框架实验(ArrayList,LinkedList,TreeSet,HashSet,TreeMap,HashMap)