Flask 项目结构说明
Posted K.Takanashi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flask 项目结构说明相关的知识,希望对你有一定的参考价值。
项目结构
Flask的一大优势就是其极其轻量化。但是也需要注意到,如果我们要用Flask做一个大项目的话,把所有代码写在一个文件里肯定是不合适的。非常难以维护。但是和Django这种框架又不一样,Flask并没有规定项目一定要遵从某种必须遵守的目录结构。最终,人们在长期的实践中得到一些比较好用因此约定俗成的目录结构。
一个典型的flask项目的目录结构是这样的(再次明确,不是强制的,而是约定俗成的一种结构):
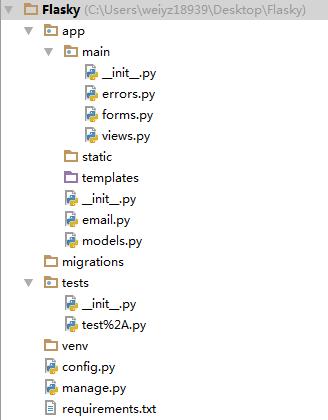
这种结构有四个顶级文件夹,主体的程序代码都放在app包中;migrations文件夹中一般存放数据库迁移脚本;单元测试的编写放在tests目录中;venv文件夹包含了python的虚拟环境。
再来看下最外层的几个文件。config.py中包含了整个项目启动时需要知道的配置信息,debug等级(开发、测试还是生产等);manage.py用于启动程序以及其他程序任务。requirements.txt中记录了所有依赖包,这样可以便于让其他主机重新生成相同的虚拟环境。下面将一个个剖开分析:
■ 配置选项
把所有代码写在一个文件中的一个大坏处就是没有办法动态地进行配置。一旦程序开始跑了,就没有回头路了。为了区别不同环境下对程序不同的配置需求,在这里添加了一个config.py这个文件。虽然具体的配置管理也没有规定形式,但是这里介绍一种相比于用字典格式来进行管理更加高级的方式,用具有层级的配置类来管理。比如我们可以设计这样一个类:
import os class Config: SECRET_KEY = os.getenv(\'SECRET_KEY\') or \'some string\' SQLALCHEMY_COMMIT_ON_TEARDOWN = True @staticmethod def init_app(app): pass class DevelopmentConfig(Config): \'\'\'开发环境配置\'\'\' DEBUG = True SQLALCHEMY_DATABASE_URI = os.environ.get(\'DEV_DATABASE_URI\') class TestingConfig(Config): \'\'\'测试环境配置\'\'\' TESTING = True SQLALCHEMY_DATABASE_URI = xxxx class ProductionConfig(Config): SQLALCHEMY_DATABASE_URI = xxx config = { \'development\':DevelopmentConfig, \'testing\':TestingConfig, \'production\':ProductionConfig, \'default\':DevelopmentConfig }#用一个字典来统合地给出所有配置
Config基类中的静态方法init_app以程序实例为参数,这个方法后面还会再提到。得到了这些不同环境下的Config类之后,可以怎么用?可以在一些合适的地方from config import config把上面那个字典config给导入进去。然后调用app.config.from_object(config[config_mode])来进行配置的导入。
■ 程序包
我们把所有的代码,模板和静态文件全部都放到程序包中,在上面的这个例子中,程序包是app目录,如果想的话也可以将app换成其他的相关名字。下面简单说明一下包中每个文件的职责:
templates和static分别盛放模板文件和静态文件,都在app目录下。然后再是email.py和models.py分别存放了电子邮件支持函数和数据库模型的代码。(电子邮件这方面之前文章中没有提到过,其实Flask还有一个拓展模块flask-mail来更好地支持电子邮件的收发。以后看情况如果有需要再回过头去看补充)
app/__init__.py是整个程序包的构造文件。在单个脚本构建项目的时候,往往只能运行一个app实例,而且一旦开始运行就无法回头修改配置了。而在__init__.py这个构造文件中,我们可以设计一个所谓的“工厂函数”。比如def一个create_app(config_mode)函数,经过一些处理之后返回一个由Flask(__name__)得到的app实例对象。工厂函数可以帮助在想要实例的时候创建一个实例出来,并且函数可以接受一些配置选项作为参数,这也实现了配置的灵活加载。比如下面这一个例子__init__.py:
from flask import Flask,render_template from flask.ext.bootstrap import Bootstrap from flask.exit.moment import Moment from flask.ext.sqlalchemy import SQLAlchemy from config import config #config就默认是上面写过的那个config啦 bootstrap = Bootstrap() moment = Moment() db = SQLAlchemy() #这里创建的三个扩展组件的对象都还是空对象,没有约束具体的app对象 def create_app(config_mode): app = Flask(__name__) app.config.from_object(config[config_mode]) config[config_mode].init_app(app) bootstrap.init_app(app) moment.init_app(app) db.init_app(app) #现在三个插件约束了app \'\'\'要在这里添加一些路由和自定义错误处理的信息,按照下文的说明,可以注册一个蓝本对象\'\'\'
from .main import main as main_blueprint
app.register_blueprint(main_blueprint)
return app
可以想象得到,以后在manage.py这个启动脚本中可以from app import create_app,然后根据自己的需要来create_app(\'development\')之类的得到app,这样的一个app是自带了一整套运行用的插件以及合适的配置的,就可以方便地让app.run了。
● 蓝本
因为工厂函数返回的是一个app实例,如果没有定义路由的话这个app实例也没什么用。但直接在create_app函数中定义路由和错误处理(错误处理因为用app.errorhandler装饰器,和路由设置是类似的)显然不太合理。一个比较好的解决方案是利用蓝本。蓝本是一种概念,其体现可以是一个单独的脚本文件或者一个包,蓝本中可以像之前单脚本架构项目时那样定义路由和错误处理。只不过蓝本中的路由处于休眠状态,只有当蓝本被注册到app实例上去之后路由才被激活然后开始发挥作用。
在上面举例的目录结构中,蓝本是main这个子包。在子包的构造文件__init__.py中可以根据需要来构建蓝图对象以及导入子包内相关的代码,比如views来定义基础路由和错误处理等,而forms是定义了表单类等等。具体创建的代码:
from flask import Blueprint main = Blueprint(\'main\',__name__) #这里的main只是为蓝本取得一个名字,并不一定要和main这个主程序包一致 import views import errors #导入路由和错误处理文件。
可以看到,Blueprint类创建实例时需要两个参数,第一个是创建出来的蓝本对象的名称,这牵扯到后面进行url_for等函数参数的写法。第二个参数一般写__name__即可。
这里有一个不太合理的地方,main/__init__.py这个文件和views.py以及errors.py等一些其他这个包中的文件互相循环导入了。__init__.py中为了把views,errors中的代码和蓝本联系起来,必须在__init__.py这个文件里面显式地import两者,而在views和errors里,蓝本的名字就像是单文件应用中的app那样,需要用来定义路由等,所以也肯定要import 蓝本名。这个循环导入的避免方法是在蓝本所在的__init__.py文件中,import views和errors的语句放在整个文件的最后面。这样可以保证外界的调用者先进来调用了__init__.py,确定建立了main这个对象之后,再导入后面两个,后面两个文件中的main就不会空手套白狼了。至于如views.py的文件的代码:
from flask import render_template,url_for,redirect from . import main from .froms import NameForm from .models import Student @main.route(\'/\',methods=[\'GET\',\'POST\']) def index(): return render_template(\'index.html\') @main.route(\'/form\',metods=[\'GET\',\'POST\']) def form(): form = NameForm() if form.validate_on_submit(): #...一些对表单的数据的处理 return render_template(\'form.html\',form=form)
*这里没有涉及到flask_sqlalchemy的导入,如果引入了flask_sqlalchemy来作为orm插件处理数据库的话,那么就要注意db.create_all()这个操作。我已开始把这个操作试着放在好几个地方不过都失败了,后来我自己从stackoverflow上面看到了一个做法是在views下面写一个@main.before_app_first_request然后在下面的函数中做create_all。可能不是最好的办法,但是可以解决db初始化的问题。
在创建完蓝本之后,再回看create_app函数,现在我们不需要定义路由,只需要调用app.register_blueprint(蓝本对象)就可以把app和蓝本中的代码动态地关联。当有需要时才激活那些代码。在蓝本基础上编写错误处理函数和路由函数的时候要注意,第一修饰器不再是app打头而是有蓝本对象的名字打头,第二url_for函数的用法会不一样,在单脚本单应用的项目中,对于响应函数时index()的路由我们可以直接url_for(\'index\')来获取。但是在蓝本中,我们必须得url_for(\'蓝本名.index\')来获取。因为所有在蓝本中设定的响应函数都被加载到蓝本对象的命名空间中,这样才能保证不污染外部命名空间并且允许不同蓝本有相同名字的响应函数。另外,如果重定向是到本蓝本的响应函数的话可以省略蓝本名直接写\'.index\',而重定向到其他蓝本的就一定要写全。
用蓝本的另一个好处就是,一个app可以关联多个蓝本。每一个蓝本可以看作是一个代码模块,用来处理一些工作。这样子就可以实现程序的模块化管理和编写了。在把app注册到不同的蓝本上去的时候,可以在register_blueprint方法中添加url_prefix参数,比如url_prefix=\'/test\'。这样就可以让这个蓝本中所有路由都默认是加在这个前缀的后面。
■ 命令行启动项目以及数据库迁移
上面说的一个在@main.before_first_app_request下面进行db.create_all的工作,但其实书上的,命令行启动的方式更加好一点。之前没有意识到,后来用了下之后发现确实很好用。
原来我们的manage脚本可能就是简单的from app import create_app,然后create_app(config_mode),然后就app.run()了。如果之前在config里面提到过debug的配置的话这里的run里面就不用写debug。这样做的话就使得启动脚本只有一个启动项目的功能,至于数据库的初始化,数据库迁移等等工作都没能做。在flask-script和flask-migrate的支持下,我们的启动脚本可以写成这样:
from app import create_app,db from app.models import User #这里把需要初始化的表,对应的类拿出来 from flask_script import Manager,Shell from flask_migrate import MigrateCommand,Migrate if __name__ == \'__main__\': app = create_app(\'development\') manager = Manager(app) migrate = Migrate(app,db) #建立一个迁移数据库的对象。 def make_shell_context(): return dict(app=app,db=db,User=User) manager.add_command(\'shell\',Shell(make_context=make_shell_context)) #make_context的意义在于命令行中输入db就知道是我们创建的那个db manager.add_command(\'db\',MigrateCommand) manager.run()
有了这样一个manage.py之后,我们可以在命令行中键入python manage.py [命令]。这里面我们设置的命令有
runserver 启动项目,相当于原来的app.run(),在后面可以跟一些参数来使得服务器更加个性化。比如默认的服务IP时127.0.0.1,只有本地可访问。可以在runserver后加上参数--host=0.0.0.0。
shell 进入有当前app作为上下文的python shell,在这里我们可以直接键入db.create_all()以及db.drop_all()来进行表的初始化和清空
● 数据库迁移相关命令
所谓数据库迁移,是指我们对model进行某些调整之后,要备份之前的数据库表结构和一些其他信息。(经过试验发现当表名发生变化,即使表结构不变,原表中的数据会不见。如果表名保持不变,只是对字段做一些增删改的话,原表中的数据还是会被调整到新表中。)
db init 进行数据库迁移仓库的建立,会自动创建migrations等目录和必要的文件
db migrate -m "some message" 用来自动创建一个数据库迁移脚本,会放在migrations/versions下面。因为是自动生成的不一定可靠,建议自己手动再去改改。
db upgrade 执行上面自动生成脚本中upgrade函数,相当于是把数据库表结构更新成当前models中定义的那样
db downgrade 执行上面脚本中的downgrade函数,把数据库表结构回滚一次改变。
依赖自动生成的脚本进行的数据库升降级是很死板的,版本只能是一条线性地升降级而不能有任何分支。比如生成自动迁移脚本的时候经常会报个Target database is not up to date之类的错。这个错的原因可能是没有在最新版本的数据库版本上进行迁移脚本的生成,可能之前生成了一个版本的迁移脚本后来又修改了model而没有生成迁移脚本,导致现在的迁移脚本指向的版本已经偏老了。测试的时候解决的办法简单粗暴,把所有自动生成的迁移脚本都删除,然后重新db migrate。
我的测试代码:【https://github.com/wyzypa/Flasky_Test】
以上是关于Flask 项目结构说明的主要内容,如果未能解决你的问题,请参考以下文章