Kafka数据辅助和Failover
Posted 一寂知千秋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka数据辅助和Failover相关的知识,希望对你有一定的参考价值。
数据辅助与Failover
CAP理论(它具有一致性、可用性、分区容忍性)

CAP理论:分布式系统中,一致性、可用性、分区容忍性最多只可同时满足两个。一般分区容忍性都要求有保障,因此很多时候在可用性与一致性之间做权衡。
一致性方案
1.Master-slave
》RDBMS的读写分离即为典型的Master-slave方案
》同步复制可保证强一致性但会影响可用性(等master确保将数据复制给全部的slave,slave才返回结果)
》异步复制可提供高可用性但会降低一致性
2.WNR
》主要用于去中心化(P2P)的分布式系统,DynameDB与Cassandra即采用此方案
》N代表副本数,W代表每次写操作要保证的最少写成功的副本数,R代表每次读至少读取的副本数
》当W+R>N时,可保证每次读取的数据至少有一个副本具有最新的更新
》多个写操作的顺序难以保证,可能导致多副本间的写操作顺序不一致,Dynamo通过向量时钟保证最终一致性
3.Paxos及其变种
》Google的Chubby,Zookeeper的Zab,RAFT等
Kafka是如何权衡CA的呢?
Replica

如:
当一个Patiton副本数超过Broker时,就会报错
Data Replication要解决的问题
1.如何Propagate(扩散)消息
2.何时Commit
3.如何处理Replica恢复
4.如何处理Replica全部宕机
1.如何Propagate(扩散)消息
以写入数据为例,Patiton分为leader和follower,follower周期性的向leader pull数据(和consumer相似)。
在读取数据时,与数据库读写分离不一样,follower并不参与读取操作,读取只和leader有关。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。但考虑到这种场景非常少见,可以认为这种方式在性能和数据持久化上做了一个比较好的平衡。在将来的版本中,Kafka会考虑提供更高的持久性。
2.何时Commit

由上图可知,leader数据发送给follower既不是同步通信也不是异步通信,而是在一致性和可用性做了动态的平衡
3.如何处理Replica恢复
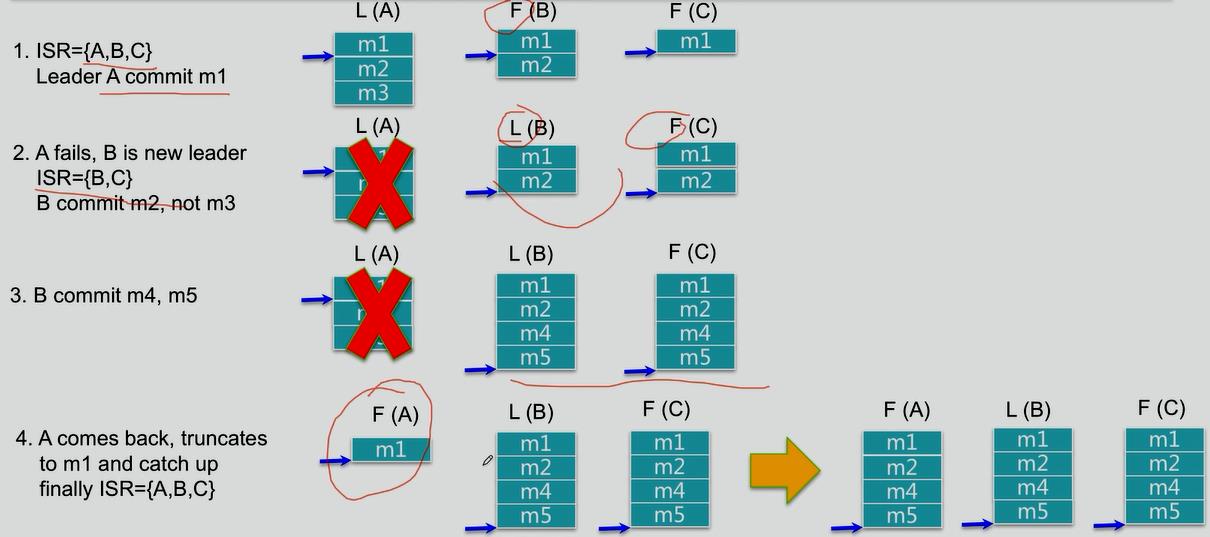
4.如何处理Replica全部宕机
等待ISR中任一Replica恢复,并选它为Leader
》等待时间较长,降低可用性
》或ISR中的所有Replica都无法恢复或者数据丢失,则该Patition将永不可用
选择第一个恢复的Replica为新的Leader,无论它是否在ISR中
》可能会有数据丢失
》可用性较高
以上是关于Kafka数据辅助和Failover的主要内容,如果未能解决你的问题,请参考以下文章