flume 1.7 的配置
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flume 1.7 的配置相关的知识,希望对你有一定的参考价值。
Apache Flume是一个分布式的、可靠的、高效的日志数据收集组件;我们通常使用Flume将分散在集群中多个Servers的log文件,汇集到中央式的数据平台中,以解决“从离散的日志文件中查看、统计数据困难”的问题。当然,Flume不仅仅可以收集log文件,它也支持比如TCP、UDP等消息数据的收集;无论如何,我们最终解决的问题就是“将离散的数据进行收集
flume的一些核心概念:
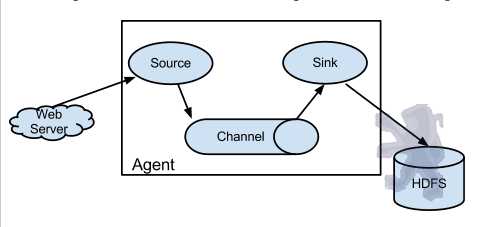
Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。
Client生产数据,运行在一个独立的线程。
Source从Client收集数据,传递给Channel。
Sink从Channel收集数据,运行在一个独立线程。
Channel连接 sources 和 sinks ,这个有点像一个队列。
Events可以是日志记录、 avro 对象等
Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成,如下图:
二 、flume的官网
下载地址: http://flume.apache.org/download.html
三、安装
1.解压下载好的包
# > tar -zxvf apache-flume-1.7.0-bin.tar.gz
2.修改系统环境变量
# > vim /etc/profile
export FLUME_HOME=/home/bigdata/flume-1.7.0
export PATH=$PATH:$FLUME_HOME/bin:
3.刷新环境变量
# > source /etc/profile
4.验证安装
# > flume-ng version
会看到以下输出:

5.修改flume的flume-env.sh 配置文件
# > /home/flume-1.7.0/conf
在文件中添加
export JAVA_HOME=/home/jdk1.8.0_131/
完成!!!
以上是关于flume 1.7 的配置的主要内容,如果未能解决你的问题,请参考以下文章
关于从kafka采集数据到flume,然后落盘到hdfs上生成的一堆小文件的总结
flume系列之:python读取flume配置文件,并把配置写入到zookeeper节点,再根据写入到zookeeper中的配置启动flume agent