浅谈Key-value 存储——SILT
Posted amyliushu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈Key-value 存储——SILT相关的知识,希望对你有一定的参考价值。
摘要:本文以文章SILT: A Memory Efficient High Performance Key-Value Store 为基础,探讨SILT存储系统是如何实现内存占用低和高性能的设计目标,从SILT系统架构入手,依次简述系统的三个基本组成部分Logstore、Hashstore和SortedStore。
- 前言
现代操作系统提供了文件系统作为存取和管理信息的机构,文件的逻辑组织形式分流式文件和记录式文件,文件的物理组织结构可分为连续文件、串联文件和随机文件[1],在我认为SILT存储系统是随机文件结构的一个扩展应用。又因为SILT是基于固态盘的单节点存储系统,了解固态盘读写的性能是至关重要的。固态盘被看做是存储领域的革命性产品,相比磁盘,固态盘的随机读写性能要高很多,能耗低,抗震,但是价格也更贵,寿命更短。下图1是基于NAND Flash的固态盘的读写示意图,我们可以看到随机写将造成失效Page随机分布在各个Block上,擦除Block需要大量数据迁移,相当于放大了写操作;如果是顺序写,失效Page将集中在少量Block中,擦除Block需要较少的数据迁移,因此性能更高[2]。可见随机写操作对性能和寿命的影响很大,因此针对固态盘的上层应用SILT存储系统在设计时尽量避免了随机写操作。
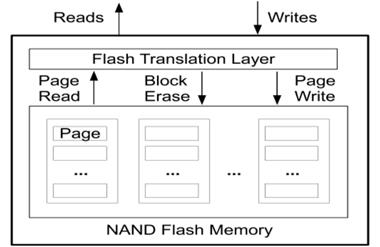
图 1 固态盘存取示意图
- SILT存储系统设计目标
2.1 各种key-value store 的对比
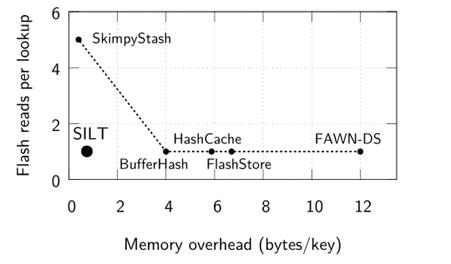
Key-Value Store 对于当今大规模、高性能的数据敏感型应用来说已经成为一个至关重要的设计模块。因此,在诸多领域高性能的key-value stores 的设计均受到重点关注,如电商平台[3]、数据去重中心[4,5,6]、图像存储[7]和web对象缓存[8,9]等等。那怎样才算是一个好的Key-value store,文章中给的目标是低延迟、高性能、充分利用有效的I/O资源。在这样的目标,各类顶级会议上涌现出了大量基于固态盘设计的Key-Value Store,包括BufferHash@NSDI10,FlashStore@VLDB10,ChunkStash@ATC10,SkimpyStash@SIGMOD11,SILT@SOSP11,BloomStore@MSST12等。如图2所示是 SILT和这几种KVS产品在内存开销和查询性能的比较,图的横坐标是系统索引文件的Key在内存中占用的字节数,纵坐标是每一次查询操作触发读FLASH的次数,显然越靠近原点,则系统总体性能越佳。其中SILT是目前最佳的系统设计,下面详细探讨其对系统的要求。
图2 SILT和其它几种KVS产品在内存开销和查询性能的比较
2.2 SILT系统的设计目标
SILT的设计遵循以下五个目标:
(1)较低的读放大:对于单个Get请求,只触发1+ε次flash read操作。其中ε是很小且可配置的值。(作者认为即使使用的固态盘,flash随机读仍然是系统读性能瓶颈, 这是相对于内存计算而言,包括哈希表计算等 )
(2)可控的写放大,支持顺序写:每个KV pair,在它的生命周期内(被删除前),被写了多少(垃圾回收等操作都会导致重复写一个KV pair, SILT的一个值得关注的缺陷是写放大,因此作者强调了可控 )。系统能够避免随机写,支持顺序写。
(3)使用较少的内存索引:log-structure不可避免地需要内存索引结构,SILT尽量减少使用内存。(DRAM仍然相当昂贵,且能耗过高, SILT的优势是将内存压缩到极致)
(4)降低内存索引的计算开销:SILT的内存索引的计算开销必须很低,使得SILT能够充分利用固态盘的吞吐率IOPS。( SILT的计算开销主要包括哈希表计算、排序、解压缩等 )
(5)高效利用固态盘空间:为了提高查询和插入性能,SILT的一些数据布局很稀疏,但是总体的空间利用率必须很高。( 我认为作者说的数据布局主要是SILT的HashStore,它的利用率最多达到93%,另一个需要注意的是SILT的Merge操作,需要2倍的固态盘空间才能完成 )
传统的Key-Value Store采用Single-Store设计,它们通常包括三个部件:
1.内存过滤器:高效地判断一个Key是否存在,避免去固态盘查找不存在的Key。典型的数据结构是Bloom Filter;
2.内存索引:高效地定位固态盘上的Key,典型数据结构是哈希表;
3.一个适合固态盘的数据布局,例如log-structure。
作者认为当时的Key-Value Store无法满足所有五个目标。比如SkimpyStash的内存开销很少,但是读放大严重;ChunStash和FlashStore的读很高效,但是内存开销太大。事实上,Single-Store的设计很难达到目标。SILT采用了Multi-Store的设计,如图三所示是SILT的系统架构图,每个Store都有不同的设计目标:
1.LogStore:针对读、写优化,但是内存开销大,最新写入的数据在这里。
2.SortedStore:不可写,读性能较高,但比LogStore弱,内存开销极小,大部分数据放在这里;
3.HashStore:不可写,读性能等于LogStore,内存开销比LogStore少,比Sort
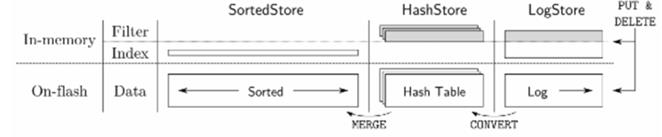
图3 SILT存储系统架构图
2.3 SILT读写操作
LogStore是log-structure,负责处理Put和Delete操作。LogStore使用一个内存哈希表将key映射到其在固态盘的位置,哈希表可以同时起到filter和index的作用。因为每个key都需要一个4字节的指针,因此内存开销很大。LogStore一旦满了,就会被转换为HashStore,HashStore是临时的,引入HashStore是为了避免频繁合并SortedStore。HashStore按key的哈希顺序存储数据,因此不需要内存索引,而是使用内存开销更少的filter。当HashStore的数量达到上限,就会批量地合并到SortedStore。SortedStore按key的自然顺序排序,然后用前缀树表示,通过结合压缩算法,可以达到非常低的内存开销。
每次插入操作,都将KV pair写入LogStore。删除操作相当于插入了一个"delete"。每次查询操作,依次查询LogStore,HashStore,和SortedStore,一旦找到就立刻停止搜索,返回结果。如果找到了"delete",说明数据已经被删了,则返回。
4 LogStore的设计
LogStore的主要目的是处理Put请求,它将新的数据顺序写到固态盘上,并在内存中用一个哈希表检索。普通的哈希表利用率只有50%,因此重点是如何设计哈希表,尽可能高效地利用内存。
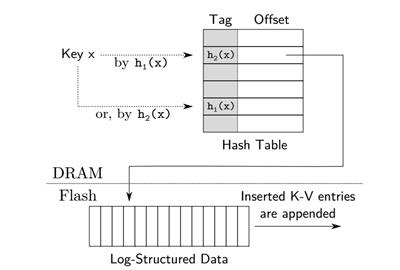
图4 Logstore设计结构
如图4所示是 Logstore设计结构, SILT使用布谷哈希表,它使用两个哈希函数h1和h2,将每个key映射到两个候选位置,key必然存在候选位置,因此绑定查询开销的上限,同时无需保存指针( 内存开销低,这是相比链表法的优势 )。当插入一个key时,存在任意空的候选位置就插入成功了;否则,需要踢掉一个位置的key,被踢掉key需要被放置到它另外一个候选位置上。这个过程可能需要重复多次才能安排好所有的key,重复次数过多(例如128次)意味着哈希表接近满了。为了节约内存,SILT并不在哈希表内存放完整的key,而是仅仅一个key的"tag"。查询key时,只有当tag匹配时,才会进一步访问固态盘。只存放一个tag并不是布谷哈希的标准做法,因为踢出操作需要使用完整的key才能计算另一个候选位置,这就导致被踢的key需要读固态盘才能进行计算。SILT的办法是用key的tag指向另一个候选位置,这样踢出一个key时,就根据tag找到另一个候选位置,并将旧候选位置设为新的tag。
标准的布谷哈希表达到50%的装填因子后,冲突就变得很难解决。为了增加利用率,SILT允许每个候选位置存放四个key的tag。SILT的实验表明,这样做可以将装填因子上升到93%。因为SILT假设key本身是哈希值,可以直接在key上取15 bits作为tag,当然两个哈希函数取的位置是不覆盖的。因此每个KV pair有15 bit的tag,4字节的指针,和1 bit的有效位(是否删除),一共是6个字节。
5 HashStore的设计
直接将LogStore合并到SortedStore会增加写放大,保留多个LogStore会增加内存开销。因此,当LogStore满的时候(即尝试了一定次数后仍无法为所有key找到合适的位置),SILT会将LogStore转换为HashStore,HashStore是只读的。当积累了一定数量的HashStore后,再批量地合并到SortedStore。在转化LogStore的过程中,旧LogStore仍然提供查询功能,由新的LogStore提供插入功能。如图5是Hashstore的设计结构。
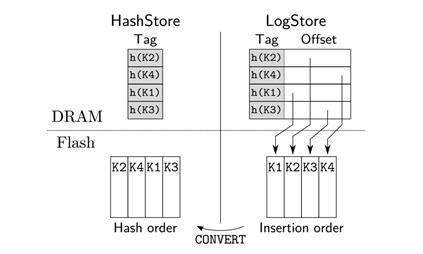
图5 HashStore的设计
HashStore中的KV pairs在固态盘上按哈希的顺序排列,因此是一个固态盘上的哈希表,有着和LogStore一样的装载因子93%。HashStore将LogStore的哈希表中的指针去掉,只保留tag。因此每个key的内存开销2.15字节。查询一个key时,如果匹配了tag,就根据tag的位置去固态盘上读key。因为没有指针,内存开销大大降低,保留的tag起到了filter的作用,避免去固态盘查找不存在的key。HashStore的冲突概率与LogStore一样。
6 结语
通读整篇文章[10],我认为该文提出的SILT存储系统很好的解决了Key-value store系统中的读放大问题,除此索引文件的设计满足较低的内存占用率和高效的利用率,但不足的是并没有解决系统中存在的写放大问题,在垃圾回收和批量整合的过程中存在很明显的写放大问题。
参考文献:
【1】操作系统原理
【2】大话云存储
【3】G. DeCandia, D. Hastorun, M. Jampani, G. Kakulapati, A. Lakshman, A. Pilchin, S. Sivasub-ramanian, P. Vosshall, and W. Vogels. Dynamo: Amazon\'s highly available key-value store.In Proc. 21st ACM Symposium on Operating Systems Principles (SOSP), Stevenson, WA, Oct.2007.
【4】[1] A. Anand, C. Muthukrishnan, S. Kappes, A. Akella, and S. Nath. Cheap and large CAMs for high performance data-intensive networked systems. In NSDI\'10: Proceedings of the 7th USENIX conference on Networked systems design and implementation, pages 29–29.
【5】[19] B. Debnath, S. Sengupta, and J. Li. FlashStore: High throughput persistent key-value store. Proc.VLDB Endowment, 3:1414–1425, September 2010
【6】[20] B. Debnath, S. Sengupta, and J. Li. SkimpyStash: RAM space skimpy key-value store onflash-based storage. In Proc. International Conference on Management of Data, ACM SIGMOD\'11, pages 25–36, New York, NY, USA, 2011.
[7][7] D. Beaver, S. Kumar, H. C. Li, J. Sobel, and P. Vajgel. Finding a needle in Haystack: Facebook\'s photo storage. In Proc. 9th USENIX OSDI, Vancouver, Canada, Oct. 2010.
[8][4] A. Badam, K. Park, V. S. Pai, and L. L. Peterson. HashCache: Cache storage for the next billion.In Proc. 6th USENIX NSDI, Boston, MA, Apr. 2009.
以上是关于浅谈Key-value 存储——SILT的主要内容,如果未能解决你的问题,请参考以下文章