『cs231n』Faster_RCNN(待续)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了『cs231n』Faster_RCNN(待续)相关的知识,希望对你有一定的参考价值。
前言
研究了好一阵子深度学习在计算机视觉方面的实际应用意义不大的奇技淫巧,感觉基本对研究生生涯的工作没啥直接的借鉴意义,硬说收获的话倒是加深了对tensorflow的理解,是时候回归最初的兴趣点——物体检测了,实际上对cs231n的Faster RCNN讲解理解的不是很好,当然这和课上讲的比较简略也是有关系的,所以特地重新学习一下,参考文章链接在这,另:
Faster RCNN github : https://github.com/rbgirshick/py-faster-rcnn
Faster RCNN paper : https://arxiv.org/abs/1506.01497
综述
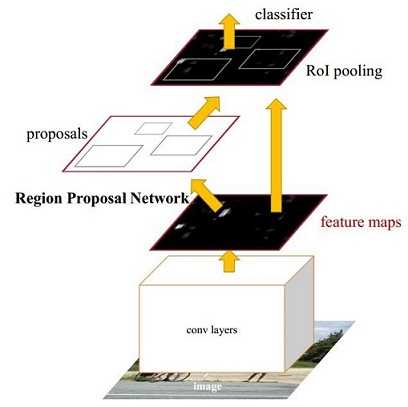
图1 Faster CNN基本结构(来自原论文)
如图1,Faster RCNN可以分为四个部分:
- Conv layers: Faster RCNN首先使用CNN网络提取image的feature maps;
- Region Proposal Networks: RPN网络用于生成region proposals,该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors获得精确的proposals;
- Roi Pooling: 该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别;
- Classification: 利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
所以本文以上述4个内容作为切入点介绍Faster RCNN网络。
图2展示了Python版本中的VGG16模型中的faster_rcnn_test.pt的网络结构:
- 对于任意大小PxQ的图像,首先缩放至固定大小MxN,然后将MxN图像送入网络;
- Conv layers中包含了13个conv层+13个relu层+4个pooling层;
- RPN网络首先经过3x3卷积,再分别生成foreground anchors与bounding box regression偏移量,然后计算出proposals;
- Roi Pooling层则利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)。
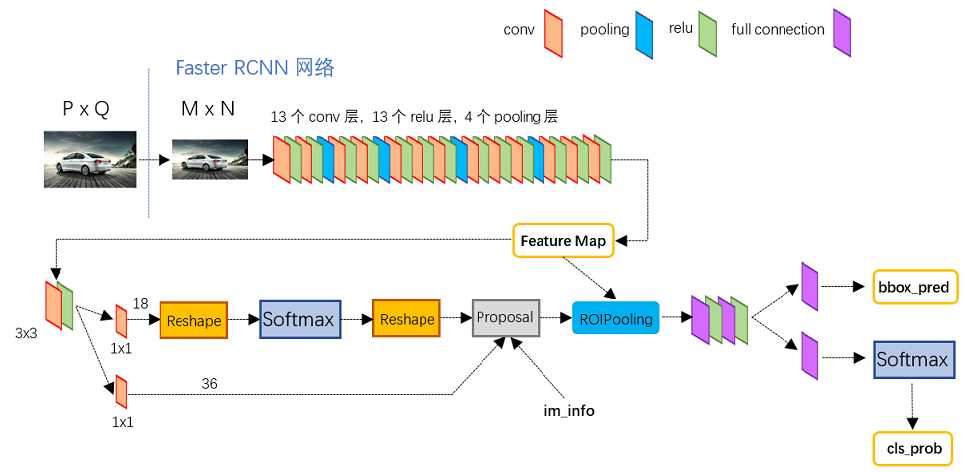
图2 faster_rcnn_test.pt网络结构
网络结构介绍
1、Conv layers
对于VGG16模型(原论文使用的模型),所有的卷积层使用了3*3的卷积核,既是最优的卷积核大小并padding,然后poling层使用的2*2大小过滤器,步长取2,也就是每一次池化后尺寸缩短1/2,Conv layers部分共有13个conv层,13个relu层,4个pooling层,这样MxN大小的矩阵经过Conv layers固定变为(M/16)x(N/16),当然这本身并没什么值得介绍的,主要是这揭示了Conv layers生成的feature map和原图对应的关系实际上是简单的映射过来的。
2、Region Proposal Networks(RPN)
传统的滑动窗口+图像金字塔生成检测框以及RCNN使用SS(Selective Search)方法生成检测框的过程是十分耗时的,Faster RCNN的主要创新之处也正在于此:RPN生成检测框的方法能极大提升检测框的生成速度。
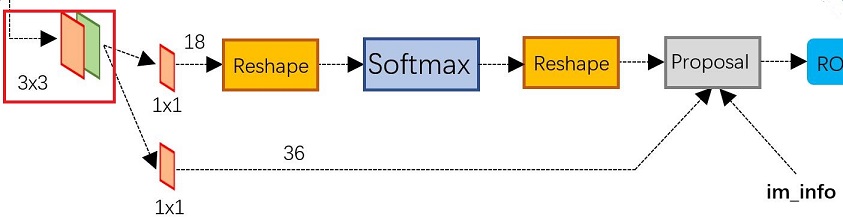
图3 RPN网络结构
上图3展示了RPN网络的具体结构,可以看到RPN网络实际分为2条线:
- 上面一条通过softmax分类anchors获得foreground和background(检测目标是foreground);
- 下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。
而最后的Proposal层则负责综合foreground anchors和bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
2.1 anchors
提到RPN网络,就不能不说anchors。所谓anchors,实际上就是一组由rpn/generate_anchors.py生成的矩形。直接运行demo中的generate_anchors.py可以得到以下输出:
[[ -84. -40. 99. 55.]
[-176. -88. 191. 103.]
[-360. -184. 375. 199.]
[ -56. -56. 71. 71.]
[-120. -120. 135. 135.]
[-248. -248. 263. 263.]
[ -36. -80. 51. 95.]
[ -80. -168. 95. 183.]
[-168. -344. 183. 359.]]
其中每行的4个值[x1,y1,x2,y2]代表矩形左上和右下角点坐标。9个矩形共有3种形状,长宽比为大约为:width:height = [1:1, 1:2, 2:1]三种,如图4,实际上通过anchors就引入了检测中常用到的多尺度方法:
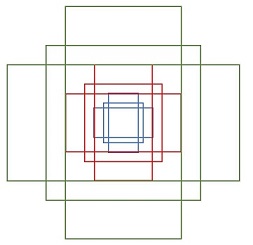
图4 anchors示意图
【注】:关于上面的anchors size,是根据网络输入图像设置的,在python demo中,会把任意大小的输入图像reshape成800x600(即图2中的M=800,N=600),再看anchors的大小,anchors中长宽1:2中最大为352x704,长宽2:1中最大736x384,基本是cover了800x600的各个尺度和形状。
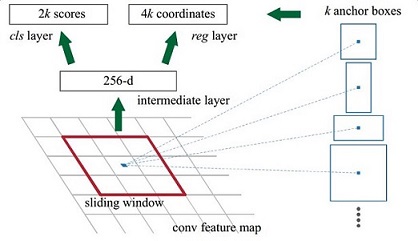
图5
解释一下图5:
- Conv Layers最后生成256张特征图,所以相当于feature map每个点都是256-d;
- Conv Layers之后,做了rpn_conv/3x3卷积且输出深度256,相当于每个点又融合了周围3x3的空间信息,同时256-d不变,注意卷积层不改变图片大小,即(M/16)x(N/16)不变;
- 假设在conv5 feature map中每个点上有k个anchor(默认k=9),而每个anhcor要分foreground和background,所以每个点由256d feature转化为cls=2k scores,而每个anchor都有[x, y, w, h]对应4个偏移量,所以reg=4k coordinates;
- 补充一点,全部anchors拿去训练太多了,训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练。
【注1】:之前了解Faster RCNN时最为费解的部分就是上面的第3条,实际上结合cs231n课程中介绍的定位任务(单目标)就比较容易理解了,这实际上和把定位任务分化为分类+回归是一个原理,对于同一个输入分别设计得分网络(分类)和坐标网络进行学习。
【注2】:在本文讲解中使用的VGG conv5 num_output=512,所以是512d,其他类似.....
2.2 softmax判定foreground与background
接上面的参数,RPN网络输入为(M/16)x(N/16),设W=M/16,H=N/16。这一步实际就是一个1x1卷积或者是全连接,如图6:

1x1卷积其输出深度18(相当于全连接层),也就是经过该卷积的输出图像为WxHx18大小,对应了feature maps每一个点都有9个anchors,同时每个anchors又有可能是foreground和background。
2.4 bounding box regression原理
3、Roi Pooling
以上是关于『cs231n』Faster_RCNN(待续)的主要内容,如果未能解决你的问题,请参考以下文章