Hadopp安装配置
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadopp安装配置相关的知识,希望对你有一定的参考价值。
第一步 创建一个Hadoop用户
在开始安装Hadoop之前,建议创建一个单独的用户以从Linux文件系统来隔离Hadoop文件系统。按照下面的步骤创建用户:
● 用管理员root用户来创建Hadoop用户
● 创建账户使用命令“useradd username”
●使用该账户“su username”
第二部 SSH设置和秘钥生成,
SSH设置需要在集群上做不同的操作,如启动、停止、分布式守护shell操作。认证不同的hadoop用户需要一种用于Hadoop用户提供的公钥/私钥对,并用不同的用户共享。
首先要用到ssh-keygen这条命令,完成的操作是有机器A、B,现在A想通过免密登录到B。
(1)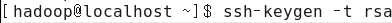
该命令在当前用户家目录的.ssh目录下面产生一对秘钥:
id_rsa:私钥
id_rsa.pub:公钥
-t参数用来指定产生不同类型的秘钥,有三种类型rsa、rsa1、dsa
(2)把A机下的/root/.ssh/id_rsa.pub公钥文件复制到到B机的/root/.ssh/authorized_keys文件里,先要在B机上创建好/home/hadoop/.ssh这个目录。

(3)设置authorized_keys文件的权限为600
chmod 600 /root/.ssh/authorized_keys
(4)验证
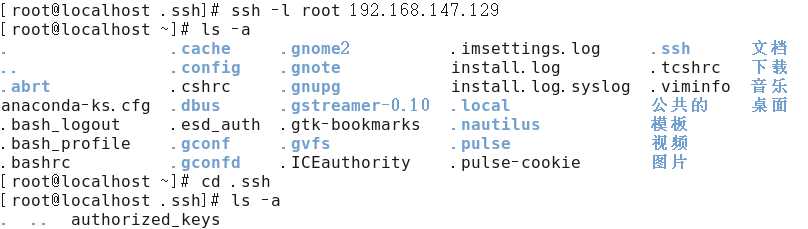
第三部 安装Java
Java是Hadoop的先决条件,可以用“java -version”命令验证Java是否存在中系统中,若没有安装则要在系统中安装jdk。
第四部 下载hadoop
下载来自Apache基金会软件,使用下面的网址获取hadoop-2.8.1
第五步 hadoop概念
让我们来看一个简单的例子,Hadoop安装提供了下列MapReduce jar文件,它提供了MapReduce的基本功能。MapReduce采用“分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是“任务的分解与结果的汇总”。
在Hadoop中,用于执行MapReduce任务的机器角色有两个:一个时JobTracker;另一个是TaskTracker,JobTracker用于调度工作,TaskTracker用于执行工作。一个Hadoop集群只有一台JobTracker。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多个任务处理结果汇总起来。
需要注意的是,用MapReduce来处理数据集(或任务)必须具备这样的特点:待处理的数据集可以分成许多小的数据集,而且每个小数据集都可以完全并行地的进行处理。
MapReduce处理过程
在Hadoop中,每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。这两个阶段分别用两个函数表示,用map和reduce函数。map函数接受一个<key,value>形式的输入,然后同样产生一个<key,value>形式的中间输出,Hadoop函数接受一个如<key,(list of values)>形式的输入,然后对这个value的集合进行处理,每个reduce产生0或1个输出,reduce的输出的输出也是<key,value>形式的。
第六步 hadoop的三种模式
下载 Hadoop 以后,可以操作Hadoop集群以以下三个支持模式之一:
-
本地/独立模式:下载Hadoop在系统中,默认情况下之后,它会被配置在一个独立的模式,用于运行Java程序。
-
模拟分布式模式:这是在单台机器的分布式模拟。Hadoop守护每个进程,如 hdfs, yarn, MapReduce 等,都将作为一个独立的java程序运行。这种模式对开发非常有用。
-
完全分布式模式:这种模式是完全分布式的最小两台或多台计算机的集群。
第七步 在单机模式下安装hadoop
有单个JVM运行任何守护进程一切都运行。独立模式适合于开发期间运行MapReduce程序,因为它很容易进行测试和调试。
设置hadoop
可以通过附加下面的命令到~/etc/profile文件中设置Hadoop环境变量。
export HADOOP_HOME=/bin/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
如果这一切设置正常,那么应该看到以下结果:

这意味着hadoop在独立模式下工作正常。默认情况下,hadoop被配置为非分布模式的单个机器上运行。
示例:运行WorldCount程序
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版的“Hello World”,该程序的完整代码可以在hadoop安装包“src/example”目录下找到。单词计数主要完成的功能是:统计一系列文件中每个单词出现的次数。
准备工作:
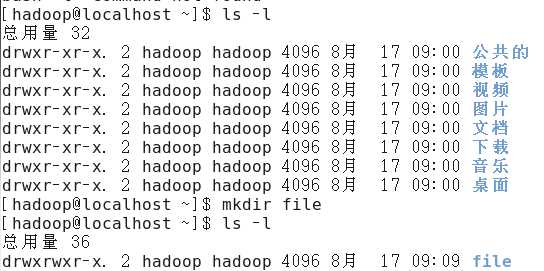
(1)创建本地示例文件
首先在“/home/hadoop”目录下创建目录“file”,用来存放示例文件。
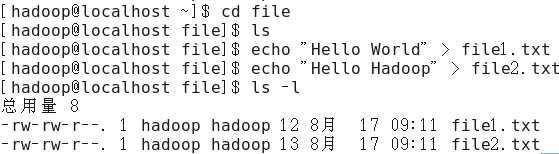
接着创建两个两个文件file1.txt和file2.txt,使file1.txt内容为“Hello World”,而file2.txt内容为“Hello Hadoop”。
(2)在HDFS上创建输入文件
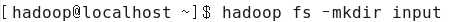
(3)上传本地file文件到input目录下

运行例子
(1)在机器上运行WorldCount程序
备注:以input作为输入目录,output目录作为输出目录。
已编译好的WordCount的jar包在“$HADOOP_HOME/hadoop/share/hadoop/mapreduce/”,就是hadoop-mapreduce-examples-2.8.1.jar,所以在下面执行命令时记得把路径写全了,不然会提示找不到jar包。
(2)查看HDFS上output内容

(3)查看输出文件内容

第七部 WorldCount处理过程
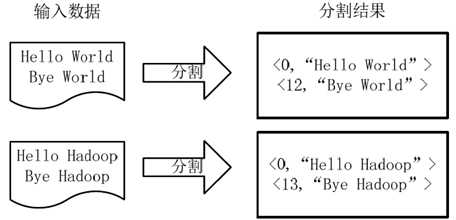
(1)将文件拆分成splits,由于测试用文件较小,所以每个文件为一个split,并将文件按行分割成<key,value>对,如下图所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)。
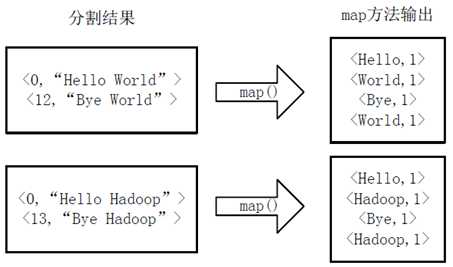
(2)将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如下图所示。
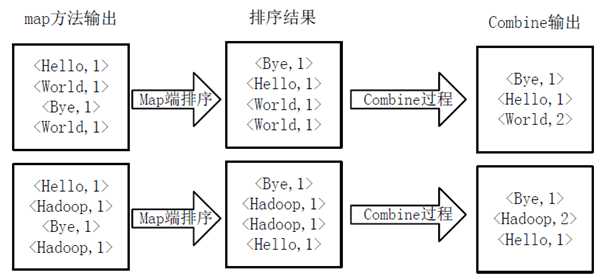
(3)得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key值同value值累加,得到Mapper的最终输出结果。
(4)Reducer先对从Mapper接受的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WorldCount的输出结果,如下图所示。

以上是关于Hadopp安装配置的主要内容,如果未能解决你的问题,请参考以下文章