mapreduce中的combinerpartitionerShuffle
Posted 张超五
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mapreduce中的combinerpartitionerShuffle相关的知识,希望对你有一定的参考价值。
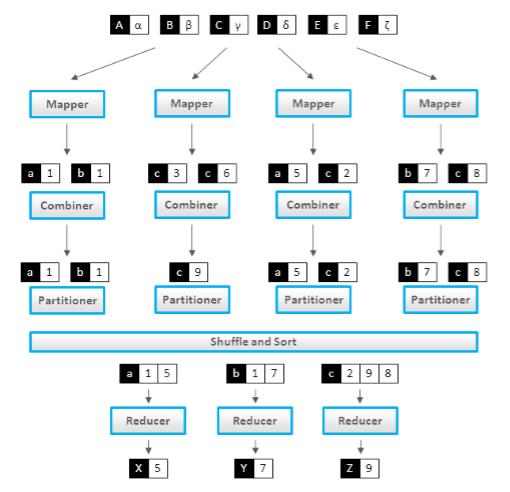
一.combiner
combiner不是mapreduce的一个必备过程,是由开发者选择是否使用的,是mapreduce的一种优化手段。
combiner的作用:combiner是为了解决mapreduce过程中的两个性能瓶颈,1.网络宽带严重被占降低程序效率,2.单一节点承载过重降低程序效率。所以性能有以下两个作用:
1.combiner实现本地key的聚合,对map输出的key排序value进行迭代
2.combiner还有本地reduce功能(其本质上就是一个reduce).
什么时候运行Combiner?
2、但是有的情况下,Merge开始执行,但spill文件的个数没有达到需求,这个时候Combiner可能会在Merge之后执行;
3、Combiner也有可能不运行,Combiner会考虑当时集群的一个负载情况。如果集群负载量很大,会尽量提早执行完map,空出资源,所以,就不会去执行。
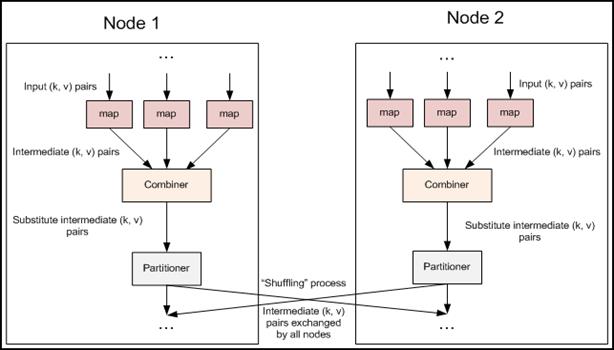
对于Combiner有几点需要说明的是:
1)有很多人认为这个combiner和map输出的数据合并是一个过程,其实不然,map输出的数据合并只会产生在有数据spill出的时候,即进行merge操作。
2)与mapper与reducer不同的是,combiner没有默认的实现,需要显式的设置在conf中才有作用。
3)并不是所有的job都适用combiner,只有操作满足结合律的才可设置combiner。combine操作类似于:opt(opt(1, 2, 3), opt(4, 5, 6))。如果opt为求和、求最 大值的话,可以使用,但是如果是求中值的话,不适用。
4)一般来说,combiner和reducer它们俩进行同样的操作。
二、partitioner
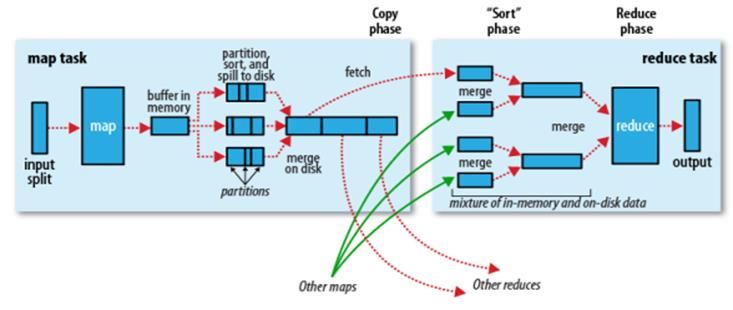
以上是关于mapreduce中的combinerpartitionerShuffle的主要内容,如果未能解决你的问题,请参考以下文章