B+tree索引
Posted 猎空
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了B+tree索引相关的知识,希望对你有一定的参考价值。
- B+Tree索引
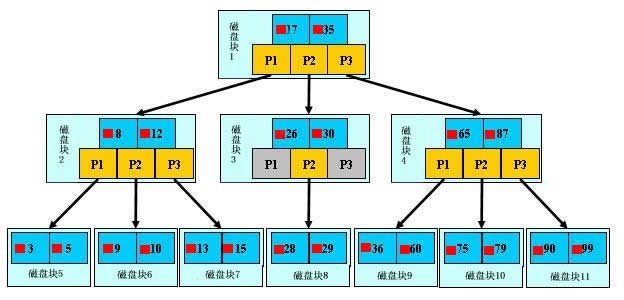
- 如上图,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99, 非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
- B+索引在InnoDB和MyISAM中数据分布对比
CREATE TABLE layout_test ( col1 int NOT NULL, col2 int NOT NULL, PRIMARY KEY(col1), KEY(col2) );
-
假设主键的值位于1---10,000之间,且按随机顺序插入,然后用OPTIMIZE TABLE进行优化。col2随机赋予1---100之间的值,所以会存在许多重复的值。
(1) MyISAM的数据布局
其布局十分简单,MyISAM按照插入的顺序在磁盘上存储数据,如下:
注:左边为行号(row number),从0开始。因为元组的大小固定,所以MyISAM可以很容易的从表的开始位置找到某一字节的位置。
据些建立的primary key的索引结构大致如下:
注:MyISAM不支持聚簇索引,索引中每一个叶子节点仅仅包含行号(row number),且叶子节点按照col1的顺序存储。
-
- B+Tree索引
来看看col2的索引结构:

实际上,在MyISAM中,primary key和其它索引没有什么区别。Primary key仅仅只是一个叫做PRIMARY的唯一,非空的索引而已。
(2) InnoDB的数据布局
InnoDB按聚簇索引的形式存储数据,所以它的数据布局有着很大的不同。它存储表的结构大致如下:

注:聚簇索引中的每个叶子节点包含primary key的值,事务ID和回滚指针(rollback pointer)——用于事务和MVCC,和余下的列(如col2)。
相对于MyISAM,二级索引与聚簇索引有很大的不同。InnoDB的二级索引的叶子包含primary key的值,而不是行指针(row pointers),这减小了移动数据或者数据页面分裂时维护二级索引的开销,因为InnoDB不需要更新索引的行指针。其结构 大致如下:

(3)总结:

-主键索引/非主键索引
叶子节点上均带有行号,通过行号进行索引
-主键索引(聚簇索引) 叶子节点上带有数据
以上是关于B+tree索引的主要内容,如果未能解决你的问题,请参考以下文章