译SAE:一个大规模网络的社交分析引擎
Posted stackupdown
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了译SAE:一个大规模网络的社交分析引擎相关的知识,希望对你有一定的参考价值。
Yang Yang, Jianfei Wang, Yutao Zhang, Wei Chen, Jing Zhang, Honglei Zhuang,
Zhilin Yang, Bo Ma, Zhanpeng Fang, Sen Wu, Xiaoxiao Li, Debing Liu, and Jie Tang
Deparment of Computer Science and Technology, Tsinghua University
发表时间:2013 发表刊物:KDD
摘要
在线的社交网络成为了连接我们的日常生活和虚拟网络空间的桥梁,它不仅提供了丰富可供挖掘的数据,而且带来了许多新的挑战。在这篇论文中,我们提出了一个新的社交分析引擎以处理大规模在线社交网络。我们着力处理的分析引擎的关键问题跟以下问题有关:
1)在微观层次,人们怎么形成了不同类型的社交纽带,并且互相影响彼此?
2)在中间层次,人们是怎样形成群体的?
3)在宏观层次,社交网络最热的话题是什么而且这些话题是怎么随着时间发展的?
我们提出了一些方法来解决上述疑问。这些方法是通用的,可以被应用到多种社交网络的数据。我们部署了这个分析引擎到许多不同的网络上,并且验证了相关方法的有效性和高效性。
关键词
社交分析引擎;社交影响;社交网络
1.介绍
快速发展的在线社交网络提供了丰富的数据,正好可以让我们去理解那些支配着社交网络动态变化的复杂机制。这个事实吸引了来自学术界和工业界的关注。例如SNAP是一个通用的网络分析和图挖掘库。它主要是为网络静态网络设计的,并且提供了分析工具。GraphChi希望把网络规模的图计算能够运行在笔记本上。它支持在利用并行计算的技巧,在单机上非常大规模的图计算。它着眼于图的计算,但是不能直接被应用到社交网络。比如它忽略了社交网络中的几个重要因素,例如社交影响,社交状态,和结构洞。
在本文中,我们提出了社交网络引擎以分析和挖掘大规模的图网络。图1显示了SAE的架构。分析引擎的基石是一个分布式图数据库,它存储着网络化的数据。在数据库的顶部,有三个核心的部分:网络继承,社交网络分析和分布式机器学习。
网络集成组件能够集成从不同网络提取出来的实体。例如,在学术领域,一个作者可以在Google Scholar, AMiner和LinkedIn上都有个人主页,但却是不同的账号。自动识别和集成这些主页有利于许多应用,例如专家寻找和影响力的分析。
社交网络分析组件是我们的主要技术贡献。首先它提供了基本的网络特征分析,包括宏观层面的属性,如密度,直径,度数的分布和社交划分,也包括微观属性,例如中心性(centrality),同质性(homophily),互利性(reciprocity), 荣誉(prestige),和可达性(reachability)这些出现在明确个体上的属性。进一步地,我们设计和实现了几个新的技术用于社交影响分析,结构洞扩展检测以及社交纽带挖掘。更具体一点,社交影响力用于量化在一个大型的社交网络中用户在不同话题下受到的影响力度。结构洞扩展检测尝试识别结构洞spanner,也就是他们控制了社交网络的信息流。社交纽带挖掘尝试揭示那些使得不同社交关系组成的基础因素。
我们也开发了一个分布式机器学习的组件,它支持和其他和上面所说的社交网络协同,把分析组件获得的基于社交的因素归并到机器学习模型里。以因子图模型为例,我们通过把社交理论特征转换成因子图模型,证实了推断社交纽带的表现可以得到很大的提升。
我们提出的社交分析引擎,有很多真实的应用。我们将会用集成实体搜索,社交影响分析和话题演化分析作为例子证明这个分析引擎的强大。
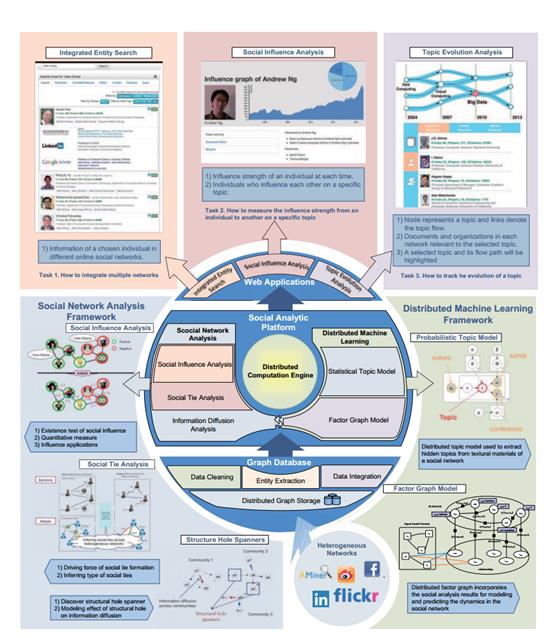
图-1. Architecture. Social Analytic Engine (SAE, http://thukeg.github.io/) for mining large networks. SAE consists of several major components: a graph database, which provides data storage and indexing; a distributed computation engine; a social network analysis component; and a distributed machine learning component.
2.核心技术
首先我们先说明我们在社交引擎中的社交网络数据。表-1列出了几个典型社交网络的统计。Co-Author是一个包括了作者和作者之间协作关系的网络;Twitter是通过滚雪球方法采样抓取的Twitter子集;Patent是一个包含公司、发明者和专利的完整文本的混合网络,它来自一个专利数据库;Weibo是一个像Twitter一样的微博网络;Slashdot是一个朋友和敌人组成的网络;Email是一个从Enron数据集导出的网络,而Mobile是一个基于位置的手机用户组成的网络。
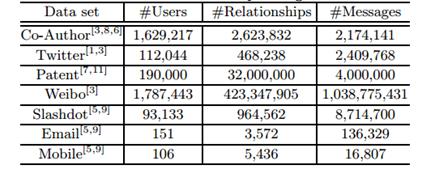
表-1 Several typical social networks. #Messages indicates the number of messages/articles associated with the users in the corresponding network.
我们接着用三个场景来介绍SAE的核心技术:集成实体搜索(Integrated Enitity Search),社交影响分析(Social Influence Analysis),话题演化分析(Topic Evolution Analysis)。
2.1 集成实体搜索
给定一个查询,在网络中找出最相关的实体(比如,意见领袖,作者和公司)是社交网络分析的一个重要任务。这个问题目前为止被称为实体搜索或者专家发现(搜索人物的时候)。但是,传统的搜索忽略了一个事实:一个用户可能在不同的网络有多个相异的账号。例如在学术领域,一个作者可能在Google Scholar,AMiner和LinkedIn都有个人主页。
自动连接不同网络的实体可以很大程度地为实体排序帮忙。我们首先提出了一个网络集成方法。基本想法是相同实体在不同网络内拥有相同的社交圈。为了实现这个方法,给定两个网络,我们首先用启发式方法识别出潜在的候选对。接着我们构建一个成对因子图,把每个候选对看成一个观察变量x,用一个二元变量y联系每个对,表示这个是否是表示同一对实体。我们用一个小规模的数据集训练因子图模型,通过最大化log-likelihood目标函数P(Y|X)(Y和X分别表示对应变量{x}和{y}的集合)[原文如此],并把训练好的模型应用到辨别其他连接对。
我们进行了一个Google Scholar, AMiner, LinkedIn和VideoLecture的实验。利用提出的方法,我们精确地聚集了超过10,000个来自四个网络的研究者。
基于集成的结果,我们提出了一个基于传播的实体排序算法。给定一个查询q, 我们要将文本和网络的信息计算,对每个v∈V得到一个相关性分数r[v]。
更明确地说,这个方法有两个步骤:第一步,我们计算一个实体跟查询q的相关度,这是通过使用语言模型得到的;第二步,我们选择排名最靠前的那些实体作为候选集,并且构造一个异构子图。我们通过传播子图中的相连实体的分数,修改了候选集的相关性分数。第二步的直观解释是,一个人写的文档在某话题上的专业度越高越可能有更高的相关性(或影响),一个拥有越高质量的文档和越高级、活跃的用户的机构应该排在越前面,一个写的文档影响力越大也的用户应该排名越高。分数传播表示如下(这里我们用一个机构节点c作为一个例子):
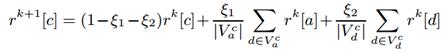
这里rk[c]是机构c的排序分数在第k步传播的大小;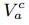 表示跟机构c相关的用户集合,而
表示跟机构c相关的用户集合,而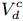 表示跟机构c拥有的文档;
表示跟机构c拥有的文档; 和
和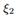 是两个控制传播的参数。传播步骤数反映了我们对网络信息的信任度。把k设置为0表示我们只使用内容的信息,把k设为∞表示我们只相信网络信息,因此这个算法在异构网络上得到一个跟PageRank相似的结果。
是两个控制传播的参数。传播步骤数反映了我们对网络信息的信任度。把k设置为0表示我们只使用内容的信息,把k设为∞表示我们只相信网络信息,因此这个算法在异构网络上得到一个跟PageRank相似的结果。
2.2 社交影响分析
社交影响分析发生在一个人的观点、情绪、行为被其他人影响的时候。它被普遍认为一个基本的造成社交网络动态变化的动力。在SAE里,提供了一个独特的特征来评估用户基于话题的影响力。在图1给出的例子中,Quoc Le被识别为一个受到Andrew Ng教授很大影响的人。
这个问题的输入是一个社交网络G=(V,E),以及一个T-维的话题分布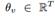 ,它跟G中的每个节点(用户)相关。每个元素
,它跟G中的每个节点(用户)相关。每个元素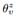 是用户在话题z的概率(重要度), 并且满足
是用户在话题z的概率(重要度), 并且满足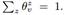 话题的分布是通过话题建模方法在SAE上的分布式机器学习组件获得的。社交影响分析的目标是基于输入的网络和每个用户的话题分布,得到话题级别的社交影响。形式化地说,从用户v到用户v\'的社交影响标记成
话题的分布是通过话题建模方法在SAE上的分布式机器学习组件获得的。社交影响分析的目标是基于输入的网络和每个用户的话题分布,得到话题级别的社交影响。形式化地说,从用户v到用户v\'的社交影响标记成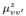 ,它是跟边
,它是跟边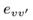 和话题z关联的数值权重。在大多数情况下,社交影响是不对称的,即
和话题z关联的数值权重。在大多数情况下,社交影响是不对称的,即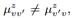 而且社交影响从用户v到v\'会因为不同的话题而改变。我们定义了一个人的全局影响度,记为
而且社交影响从用户v到v\'会因为不同的话题而改变。我们定义了一个人的全局影响度,记为 。
。
为了量化用户间的社交影响,有必要考虑指定用户-话题分布和网络结构。我们使用了一个统一的方法使得局部属性(话题分布)和全局结构(网络信息)可用于社交影响分析
。这个算法称为TAP(topical affinity propogation)。主要思想是在话题级别上为社交影响进行相似性传播以进行社交影响力识别。该方法基于一个观察数据是在局部属性和关系上都内聚性的因子图模型。为了计算在不同时期内的影响,我们在每个时间点分别运行了该方法。
2.3 话题演化分析
明白最热门的话题是什么和话题是怎么随时间演化的是一个重要和有挑战性的任务。SAE通过支持去建构一个话题流图,解决了这个问题。在一个话题流图例,一个顶点代表了一个话题,一条边代表了一个话题流。一个话题到另外一个话题的话题流,在相邻的时间点之间代表了前者怎么演化(分裂或合并)到后者的。如在图1中提到的例子,"大数据"话题最近非常热门,而且可以被回溯到"数据库"和"并行计算"。一个没有任何入边的顶点代表了一个已合并的话题。一个没有出边的顶点代表了一个无人讨论的话题。两个顶点间的箭头的粗细表示两个话题间的相似度。顶点的大小代表了相应话题的热度。
给定一个查询,SAE返回一个包含了查询相关的话题的流图。用户可以选择一个顶点(话题)。系统接着会识别出包含了被选中话题的主干路,并且把这条路上的所有话题显示出来。系统同时会显示一个表,上面有跟该话题相关,并且来自每个社交网络的文档,用户和机构。
话题流图可以定义成一个有向无环图(DAG),顶点表示每个时间点的话题,边隐含两个两个时间连续的话题的话题流。给定一个随时间变化的文档,则技术上的目标是抽取隐含的话题以及构建一个DAG来表示话题流。
为了给一个查询自动生成一个话题流图,我们首先用SAE分布式机器学习组件实现概率话题模型,来独立地提取每个时间点的文档中隐含的话题。每个话题被单词分布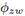 赋值,表示单词w用来表达话题z。我们采用了经典聚类算法,如K-means,来对连续时间点的话题进行聚类。两个话题之间的举例定义成它们的单词分布的KL-divergence。对于两个连续时间的话题,我们会在它小于一个阈值的时候创建一条边,并且把粗细定义成距离的倒数。
赋值,表示单词w用来表达话题z。我们采用了经典聚类算法,如K-means,来对连续时间点的话题进行聚类。两个话题之间的举例定义成它们的单词分布的KL-divergence。对于两个连续时间的话题,我们会在它小于一个阈值的时候创建一条边,并且把粗细定义成距离的倒数。
3. 总结
在这篇论文中,我们提出了Social Analytic Engine(SAE)用于大型网络。我们简单地介绍了该系统的架构并且用三个场景作为例子解释了它的核心技术:集成实体搜索,社交影响分析,话题演化分析。该引擎还提供了其他社交网络分析工具,例如核心社区的检测,结构洞用户的检测,以及用户行为建模。我们在若干个不同类型的数据集上部署了SAE引擎,并且我们的工作验证了这个社交分析引擎的有效性和高效性。
致谢
这项工作得到中国自然科学基金会(No. 61222212, No. 61073073, No. 61170061),中国国家重点研究基金(No. 60933013, No.61035004), 以及华为公司的研究基金会的支持。
4. 参考文献
[1] J. Hopcroft, T. Lou, and J. Tang. Who will follow you back? reciprocal relationship prediction. In CIKM\'11, pages 1137–1146, 2011.
[2] L. Liu, J. Tang, J. Han, M. Jiang, and S. Yang. Mining topic-level influence in heterogeneous networks. In CIKM\'10, pages 199–208, 2010.
[3] T. Lou and J. Tang. Mining structural hole spanners through information diffusion in social networks. In WWW\'13, pages 837–848, 2013.
[4] L. Page, S. Brin, R. Motwani, and T. Winograd. The pagerank citation ranking: Bringing order to the web. Technical Report SIDL-WP-1999-0120, Stanford University, 1999.
[5] J. Tang, T. Lou, and J. Kleinberg. Inferring social ties across heterogeneous networks. In WSDM\'12, pages 743–752, 2012.
[6] J. Tang, J. Sun, C. Wang, and Z. Yang. Social influence analysis in large-scale networks. In KDD\'09,
pages 807–816, 2009.
[7] J. Tang, B. Wang, Y. Yang, P. Hu, Y. Zhao, X. Yan, B. Gao, M. Huang, P. Xu, W. Li, and A. K. Usadi.
Patentminer: Topic-driven patent analysis and mining. In KDD\'2012, pages 1366–1375, 2012.
[8] J. Tang, J. Zhang, L. Yao, J. Li, L. Zhang, and Z. Su. Arnetminer: Extraction and mining of academic social networks. In KDD\'08, pages 990–998, 2008.
[9] W. Tang, H. Zhuang, and J. Tang. Learning to infer social ties in large networks. In ECML/PKDD\'11,
pages 381–397, 2011.
[10] C. Wang, J. Han, Y. Jia, J. Tang, D. Zhang, Y. Yu, and J. Guo. Mining advisor-advisee relationships from research publication networks. In KDD\'10, pages 203–212, 2010.
[11] Y. Yang, J. Tang, J. Keomany, Y. Zhao, Y. Ding, J. Li, and L. Wang. Mining competitive relationships
by learning across heterogeneous networks. In CIKM\'12, pages 1432–1441, 2012.
[12] J. Zhang, B. Liu, J. Tang, T. Chen, and J. Li. Social influence locality for modeling retweeting behaviors. In IJCAI\'13, 2013.
以上是关于译SAE:一个大规模网络的社交分析引擎的主要内容,如果未能解决你的问题,请参考以下文章