95自然语言处理svd词向量
Posted 香港胖仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了95自然语言处理svd词向量相关的知识,希望对你有一定的参考价值。
import numpy as np import matplotlib.pyplot as plt la = np.linalg words = ["I","like","enjoy","deep","learning","NLP","flying","."] X = np.array([[0,2,1,0,0,0,0,0], [2,0,0,1,0,1,0,0], [1,0,0,0,0,0,1,0], [0,1,0,0,1,0,0,0], [0,0,0,1,0,0,0,1], [0,1,0,0,0,0,0,1], [0,0,1,0,0,0,0,1], [0,0,0,0,1,1,1,0]]) U,s,Vh=la.svd(X, full_matrices=False) for i in range(len(words)): print(U[i,1],U[i,1],words[i]) plt.text(U[i,0],U[i,1],words[i]) plt.xlim(-1,1) plt.ylim(-1,1) plt.show()
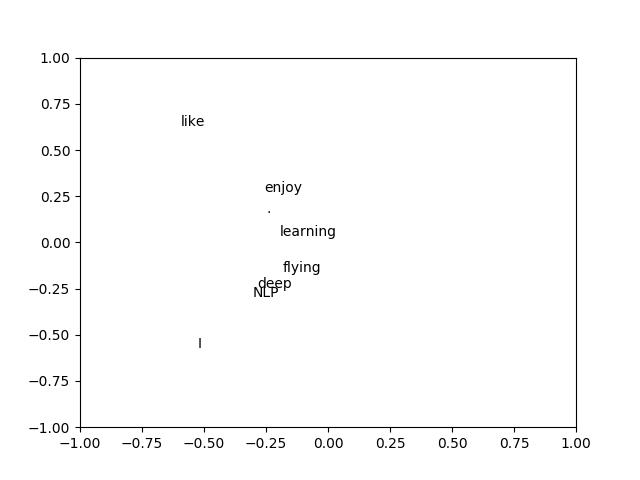
这是根据斯坦福cs224d课程写出来的,
这是课程里边最开始所讲的词向量,
1、首先将所有的词组织成一个词典
2、对于词典中的每一个词,
扫描词典中的其他词,
对于扫描到的每一个词,
统计原始词在被扫描到的词的前边或者后边出现的次数,
这样就构成了一个由词频所构成的对角阵
3、对该对角阵进行SVD分解得到
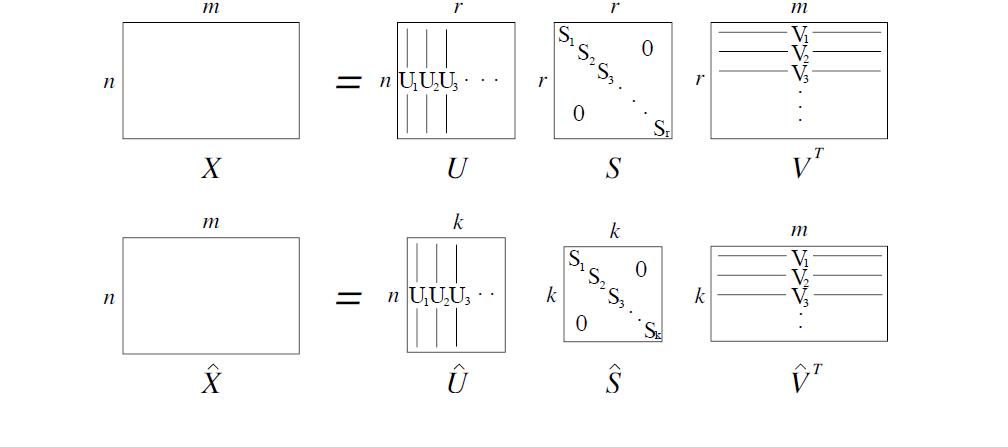
得到的U矩阵便是经过降维后的词向量矩阵
将每个词的词向量前两个值画在图中
便得到了如最上面图所示的
词关系图
Thanks
WeiZhen
以上是关于95自然语言处理svd词向量的主要内容,如果未能解决你的问题,请参考以下文章