第四章
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第四章相关的知识,希望对你有一定的参考价值。
本章内容
1.动态导入模块
2.粘包问题
3.paramkio(ssh链接模块)
4.多线程
5.GIL锁
6.互诉锁
7.递归锁
8.Semaphore(信号量)
9.事件(多线程标志位)
10.队列(queue)
11.生产者消费者模型
12.多进程
13.进程之间通讯
14.进程之间数据共享
15.进程池
16. 协程
17.事件驱动
18.堵塞IO 非堵塞,同步IO,异步IO
1.动态导入模块
aa.py
def test():
print("ok")
class C:
def __init__(self):
self.name = ‘abc‘
__import__
data = __import__(‘day5.aa‘)
a =data.aa
a.test()
b =data.aa.C()
print(b.name)
--------------------------------------------
import importlib
aa = importlib.import_module(‘day5.aa‘)
print(aa.C().name)
aa.test()
---------------------------------------------
conn.send(str(len(cmd_res.encode())).encode("utf-8"))
-------------------------------------------------------------
2.粘包问题
while True:
cmd = input(">>:").strip()
if len(cmd) == 0:continue
if cmd.startwith("get"):
clinet.send(cmd.encode())
file_toal_size = int(server_response.decode())
received_size = 0
filename = cmd.split()[1]
f = open(filename,‘wb‘)
m = hashlib.md5()
while received_size < file_toal_size:
if file_toal_size - received_size > 1024:
size = 1024
else:
size = file_toal_size - received_size
data = client.recv(size)
received_size += len(data)
f.write(data)
else:
new_file_md5 = m.hexdigest()
--------------------------------------------
import socketserver
class MyTCPHandler(socketserver.BaseRequestHandler):
def handler(self):
while True:
try:
self.data = self.request.recv(1024).strip()
print("{}wrote:".format(self.client_address[0]))
print(self.data)
self.request.send(self.data.upper())
except ConnectionAbortedError as e:
print("ree",e)
break
if __name__ == "__main__":
HOST,PORT = "localhost",9999
3.paramiko
paramiko模块安装
http://blog.csdn.net/qwertyupoiuytr/article/details/54098029
密码链接
#!/usr/bin/env python # _*_ encoding:utf-8 _*_ import paramiko #创建SSH对象 ssh = paramiko.SSHClient() #允许链接不在know_host文件主机中 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) #链接服务器 ssh.connect(hostname=‘192.168.80.11‘,port=22,username=‘root‘,password=‘123.com‘) #执行命令 stdin,stdout,stderr = ssh.exec_command(‘df‘) #获取结果 res,err = stdout.read(),stderr.read() resilt = res if res else err print(resilt) #关闭连接 ssh.close() ------------------------------------------------------- transport = paramiko.Transport((‘192.168.80.11‘,22)) transport.connect(username=‘root‘,password=‘123.com‘) ssh = paramiko.SSHClient() ssh._transport = transport stdin,stdout,stderr = ssh.exec_command(‘df‘) print(stdout.read()) transport.close()
密码链接上传/下载文件
transport = paramiko.Transport((‘192.168.80.11‘,22)) transport.connect(username=‘root‘,password=‘123.com‘) sftp = paramiko.SFTPClient.from_transport(transport) #上传文件 sftp.put(‘windows.txt‘,‘/root/win.txt‘) #下载文件 #sftp.get(‘linux.txt‘,‘linux.txt‘) transport.close()
免密码链接
linux 拷贝公钥 ssh-copy-id "[email protected]" #指定公钥 private_key = paramiko.RSAKey.from_private_key_file(‘id_rsa‘) ssh = paramiko.SSHClient() ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) ssh.connect(hostname=‘192.168.80.11‘,port=22,username=‘root‘,pkey=private_key) stdin,stdout,stderr = ssh.exec_command(‘df‘) result = stdout.read() print(result) ssh.close()
免密码上传/下载文件
private_key = paramiko.RSAKey.from_private_key_file(‘id_rsa‘) transport = paramiko.Transport((‘192.168.80.11‘,22)) transport.connect(username=‘root‘,pkey=private_key) sftp = paramiko.SFTPClient.from_transport(transport) sftp.put(‘windows.txt‘,‘/root/windows.txt‘) sftp.get(‘linux.txt‘,‘linux.txt‘) transport.close()
4.多线程
io 操作不沾用cpu
计算占用cpu,1+1
python多线程 不适合cpu密集操作型的任务,适合io密集型的任务操作
def run(n):
print(‘task‘,n)
time.sleep(2)
t1=threading.Thread(target=run,args=(‘t1‘,))
t2=threading.Thread(target=run,args=(‘t2‘,))
t1.start()
t2.start()
############
import threading
import time
class MyThread(threading.Thread):
def __init__(self,n):
super(MyThread,self).__init__()
self.n = n
def run(self):
print("runnint task",self.n)
t1 = MyThread("t1")
t1.start()
################
start_time = time.time()
t_objs = []
def run(n):
print(‘task‘,n)
time.sleep(2)
for i in range(50):
t = threading.Thread(target=run,args=(‘t-%s‘%i,))
t.start()
t_objs.append(t)
for t in t_objs:
t.join()
print(‘--------------all-------------‘)
print("cost",time.time() - start_time)
查看当前运行的主进程和主进程个数
print(‘-all--‘,threading.current_thread(),threading.active_count())
守护线程
import threading
import time
start_time = time.time()
t_objs = []
def run(n):
print(‘task‘,n)
time.sleep(2)
for i in range(50):
t = threading.Thread(target=run,args=(‘t-%s‘%i,))
t.setDaemon(True) #把子线程变成守护线程(守护线程,主线程执行完推出,不等待守护线程执行结束)
t.start()
t_objs.append(t)
for t in t_objs:
t.join()
print(‘--------------all-------------‘,threading.current_thread(),threading.active_count())
print("cost",time.time() - start_time)
5.GIL锁
python只能执行一个进程,所以在执的多进程工作室,是利用上下切花来完成的 因为python是调用C语言原始的进程接口,不可以调整 进程工作的顺序,在同一时间内只有一个进程在处理数据
6.互诉锁
互诉锁 防止上下切换覆盖数据
import threading
import time
def run(n):
lock.acpuire() #加锁
global num
num += 1
time.sleep(1)
lock.release() #释放锁
lock = threading.Lock() #调用锁
num = 0
t_objs = []
for i in range(50):
t = threading.Thread(target=run,args=("t-%s"%i,))
t.start()
t_objs.append(t)
for t in t_objs:
t.join()
print(‘num‘,num)
7.递归锁
递归锁 防止锁顺序错乱
import threading,time
def run1():
print("grab the first part dara")
lock.acquire()
global num
num +=1
lock.release()
return num
def run2():
print("grab the second part data")
lock.acquire()
global num2
num2+=2
lock.release()
return num2
def run3():
lock.acquire()
res = run1()
print("----run1 run2-----")
res2 = run2()
lock.release()
print(res,res2)
if __name__ == ‘__main__‘:
num,num2 = 0,0
lock = threading.RLock()
for i in range(10):
t = threading.Thread(target=run3)
t.start()
while threading.active_count() !=1:
print(threading.active_count())
else:
print(num,num2)
8.Semaphore(信号量)
互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去。
import threading,time
def run(n):
semaphore.acquire()
time.sleep(1)
print("run the threading:%s\\n"%n)
semaphore.release()
if __name__ == ‘__main__‘:
semaphore = threading.BoundedSemaphore(5) #允许5个线程同时运行
for i in range(20):
t = threading.Thread(target=run,args=(i,))
t.start()
while threading.active_count() !=1:
pass
else:
print(‘----all-------‘)
9.事件(多线程标志位)
import threading,time
event = threading.Event()
def lighter():
count = 0
event.set()
while True:
if count >5 and count <10:
event.clear()
print("\\033[41m--->红灯\\033[0m")
elif count >10:
event.set()
count = 0
else:
print("\\033[42m--->绿灯\\033[0m")
time.sleep(1)
count +=1
def car(name):
while True:
if event.is_set():
print("[%s] running..."% name)
time.sleep(1)
else:
print("[%s]sees red light waiting.."%name)
event.wait()
print("\\033[34m[%s] green ligth is on start going....\\033[0m"%name)
light = threading.Thread(target=lighter,)
light.start()
car1 = threading.Thread(target=car,args=("Tesla",))
car1.start()
10.队列(queue)
解耦,使程序直接耦合,提高程序效率,一个进程修改不影响其他进程
10.1.先进先出
q = queue.Queue() # q = queue.Queue(maxsize=3) 设置队列数量 q.put(1) 传数据 q.put(2) q.put(3) print(q.qsize()) 查看队列大小 print(q.get()) 取数据 print(q.get()) # print(q.get_nowait()) 取数据为空时不会卡住 # print(q.get(block=False)) 设置false取数据为空时不会卡住 print(q.get(timeout=1)) 设置其数据时间为1秒
10.2.先进后出
import queue q = queue.LifoQueue() q.put(1) q.put(2) q.put(2) print(q.get()) print(q.get()) print(q.get())
10.3.标记优先级
import queue q = queue.PriorityQueue() q.put((-1,"a")) q.put((3,"b")) q.put((6,"c")) print(q.get()) print(q.get()) print(q.get())
11.生产者消费者模型
import threading
import queue
q = queue.Queue()
def producer():
for i in range(10):
q.put("骨头%s"%i)
print("开始等待骨头被取走。。。")
q.join()
print("所有骨头被取完了。。。")
def consumer(n):
while q.qsize() >0:
print("%s 取到"%n,q.get())
q.task_done()
p = threading.Thread(target=producer,)
p.start()
# b = threading.Thread(target=consumer,args=("abc",))
# b.start()
consumer("abc")
12.多进程
def run(name):
time.sleep(2)
print("hello",name)
if __name__ == ‘__main__‘:
for i in range(10):
p = multiprocessing.Process(target=run,args=("bob %s"%i,))
p.start()
def thread_run():
print(threading.get_ident()) #返回当前线程的“线程标识符
def run(name):
time.sleep(2)
print("hello",name)
t = threading.Thread(target=thread_run,)
t.start()
if __name__ == ‘__main__‘:
for i in range(10):
p = multiprocessing.Process(target=run,args=("bob %s"%i,))
p.start()
13.进程之间通讯
from multiprocessing import Process,Queue
def f(qq):
qq.put([42,None,‘hello‘])
if __name__ == ‘__main__‘:
q = Queue()
p = Process(target=f,args=(q,))
p.start()
print(q.get())
p.join()
####################
from multiprocessing import Process
import os
def info(title):
print(title)
print(‘module name‘,__name__)
print(‘parent process‘,os.getppid()) 打印父进程id
print(‘process id:‘,os.getpid()) 打印子进程id
print("\\n\\n")
def f(name):
info(‘\\033[31mfunction f\\033[0m‘)
print(‘hello‘,name)
if __name__ == ‘__main__‘:
info(‘\\033[32;1mmain process line\\033[0m‘)
p = Process(target=f,args=(‘bob‘,))
p.start()
p.join()
#Pipes
#Pipe是通过管道传送和接受数据的
from multiprocessing import Process,Pipe
def f(conn):
conn.send([42,None,"hello"])
conn.close()
if __name__ == ‘__main__‘:
parent_conn,child_conn = Pipe()
p = Process(target=f,args=(child_conn,))
p.start()
print(parent_conn.recv())
p.join()
14.进程之间数据共享
from multiprocessing import Process,Manager
import os
def f(d,l):
d[os.getpid()] = os.getpid()
l.append(os.getpid())
print(l)
print(d)
if __name__ == ‘__main__‘:
with Manager() as manager:
d = manager.dict()
l = manager.list(range(5))
p_list =[]
for i in range(10):
p = Process(target=f,args=(d,l,))
p.start()
p_list.append(p)
for res in p_list:
res.join()
# print(d)
# print(l)
----------------------------------------------
from multiprocessing import Process,Lock
def f(l,i):
l.acquire()
try:
print(‘hello world‘,i)
finally:
l.release()
if __name__ == ‘__main__‘:
lock = Lock()
for num in range(10):
Process(target=f,args=(lock,num)).start()
15.进程池
from multiprocessing import process,Pool,freeze_support (windows 需要加,freeze_support)
import time,os
def Foo(i):
time.sleep(2)
print(‘in process‘,os.getpid())
return i + 100
def Bar(arg):
print(‘-->exec done:‘,arg,os.getpid())
if __name__ == ‘__main__‘:
pool = Pool(processes=3) 允许进程池同时放入5个进程
print("主进程",os.getpid())
for i in range(10):
pool.apply_async(func=Foo,args=(i,),callback=Bar) #同步(并行) (callback方法 执行完Foo执行Bar 避免重复的长连接)
#pool.apply(func=Foo,args=(i,)) 串行
print(‘end‘)
pool.close()
pool.join()
16.协程
import time
import queue
def consumer(name):
print("--->starting eating baozi...")
while True:
new_baozi = yield
print("[%s] is eating baozi %s" % (name,new_baozi))
#time.sleep(1)
def producer():
r = con.__next__()
r = con2.__next__()
n = 0
while n < 5:
n +=1
con.send(n)
con2.send(n)
print("\\033[32;1m[producer]\\033[0m is making baozi %s" %n )
if __name__ == ‘__main__‘:
con = consumer("c1")
con2 = consumer("c2")
producer()
#########################
from greenlet import greenlet
def test1():
print(12) #2
gr2.switch() #切换
print(34) #4
gr2.switch() #切换
def test2():
print(56) #3
gr1.switch() #切换
print(78) #5
gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch() #1
16.1.自动切换
协程切换原理 遇到IO操作就切换,执行时间短的先执行,(IO 为等待时间)
import gevent
def foo():
print(‘foo 1‘) #1
gevent.sleep(2)
print(‘foo 2‘) #6
def bar():
print(‘bar 1‘) #2
gevent.sleep(1)
print(‘bar 2‘) #5
def func3():
print("func 1") #3
gevent.sleep(0)
print(‘func 2‘) #4
gevent.joinall([
gevent.spawn(foo),
gevent.spawn(bar),
gevent.spawn(func3),
])
16.2.利用协程爬虫
#!/usr/bin/env python
# _*_ encoding:utf-8 _*_
from greenlet import greenlet
from urllib import request
import gevent,time
from gevent import monkey
monkey.patch_all() #把当前程序所有的IO操作做上标记(否则gevent无法识别)
def f(url):
print(‘GET: %s‘% url)
resp = request.urlopen(url)
data = resp.read()
print(‘%d bytes received from %s‘%(len(data),url))
urls = [‘https://www.python.org/ ‘,
‘https://www.yahoo.com/ ‘,
‘https://github.com/ ‘]
time_start = time.time()
for url in urls:
f(url)
print("cost",time.time() - time_start)
async_time_start = time.time()
gevent.joinall([
gevent.spawn(f,‘https://www.python.org/ ‘),
gevent.spawn(f,‘https://www.yahoo.com/ ‘),
gevent.spawn(f,‘https://github.com/ ‘),])
print("cost",time.time() - async_time_start)
16.3.协程socket
server
#!/usr/bin/env python
# _*_ encoding:utf-8 _*_
import sys
import socket
import time
import gevent
from gevent import socket,monkey
monkey.patch_all()
def server(port):
s = socket.socket()
s.bind((‘localhost‘,port))
s.listen(500)
while True:
cli,addr = s.accept()
gevent.spawn(handle_request,cli)
def handle_request(conn):
try:
while True:
data = conn.recv(1024)
print(‘recv:‘,data)
conn.send(data)
if not data:
conn.shutdown(socket.SHUT_WR)
except Exception as ex:
print(ex)
finally:
conn.close()
if __name__ == ‘__main__‘:
server(8001)
clinet
import socket
HOST = ‘localhost‘
PORT = 8001
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.connect((HOST,PORT))
while True:
msg = bytes(input(">>"),encoding=‘utf8‘)
s.sendall(msg)
data = s.recv(1024)
print(‘Received‘,data)
s.close()
17.事件驱动
对事件做处理 例如:点击鼠标 放到一个时间列表 按键盘放到一个时间列表 有一个进程来处理
18.堵塞IO 非堵塞,同步IO,异步IO
http://www.cnblogs.com/alex3714/articles/5876749.html
18.1 .文件描述
服务收到一个事件,会放到对应的列表里面,文件描述符就是对应的索引,而索引对应是文件句柄(文件对象)
18.2.缓存io
程序不可以直接调用系内核,程序打开文件都是调用内核来完成的,例如拷贝文件,是先拷贝到内核缓存区 然后再拷贝到io
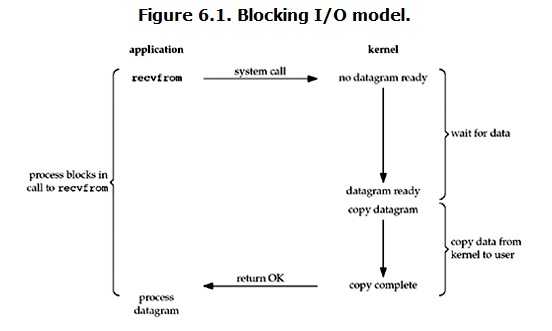
18.3.阻塞IO (blocking IO)
一个进程正在执行,另一个进程在等待,就造成了堵塞。
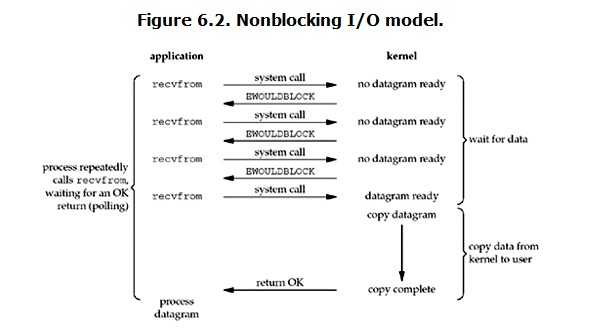
18.4 .非阻塞IO (nibulocking IO)
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,
而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,
而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,
于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,
那么它马上就将数据拷贝到了用户内存,然后返回。
所以,nonblocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有。
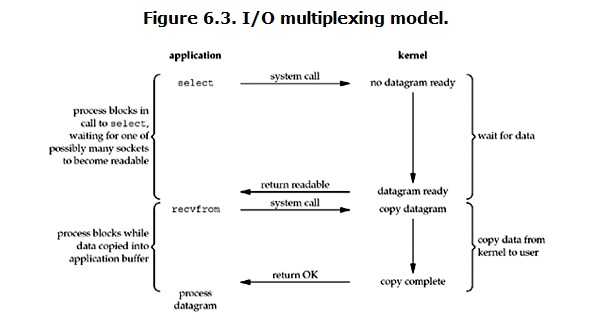
18.5.IO多路复用(IO multipexing)
IO multiplexing就是我们说的select,poll,epoll,
有些地方也称这种IO方式为event driven IO。
select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。
它的基本原理就是select,poll,
epoll这个function会不断的轮询所负责的所有socket,
当某个socket有数据到达了,就通知用户进程。
当用户进程调用了select,那么整个进程会被block,
而同时,kernel会“监视”所有select负责的socket,
当任何一个socket中的数据准备好了,select就会返回。
这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
所以,I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,
而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
18.6.IO多路复用之 select,poll,epoll的区别
select,poll,epoll是IO多路复中监视数据
select
例如有100个链接过来 内核检测到其中只有两个有数据,内核不会告诉select
因此select 需要自己循环查找消耗事件,
select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,
不过可以通过修改宏定义甚至重新编译内核的方式提升这一限制。
poll
poll在1986年诞生于System V Release 3,
它和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制。
epoll
它几乎具备了之前所说的一切优点,
被公认为Linux2.6下性能最好的多路I/O就绪通知方法。
例如有100个链接过来 内核检测到其中只有两个有数据,
内核会直接告诉epoll只有两个有数据 就不用自己查找。
18.7.异步IO (asyncchronous IO)
用户进程发起read操作之后,立刻就可以开始去做其它的事。
而另一方面,从kernel的角度,当它受到一个asynchronous read之后,
首先它会立刻返回,所以不会对用户进程产生任何block。然后,
kernel会等待数据准备完成,然后将数据拷贝到用户内存,
当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
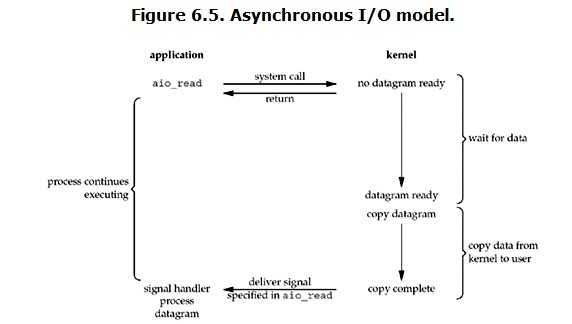
阻塞IO,非阻塞IO,IO多路复用:都为同步IO
异步IO:异步IO
以上是关于第四章的主要内容,如果未能解决你的问题,请参考以下文章