ML: 聚类算法R包 - 密度聚类
Posted 天戈朱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ML: 聚类算法R包 - 密度聚类相关的知识,希望对你有一定的参考价值。
密度聚类
- fpc::dbscan
fpc::dbscan
DBSCAN核心思想:如果一个点,在距它Eps的范围内有不少于MinPts个点,则该点就是核心点。核心和它Eps范围内的邻居形成一个簇。在一个簇内如果出现多个点都是核心点,则以这些核心点为中心的簇要合并。其中要注意参数eps的设置,如果eps设置过大,则所有的点都会归为一个簇,如果设置过小,那么簇的数目会过多。如果MinPts设置过大的话,很多点将被视为噪声点(先计算距离矩阵,然后看一下距离大概都是多少,找个靠谱的设置成半径)
优点:
- 对噪声不敏感。
- 能发现任意形状的聚类。
缺点:
- 聚类的结果与参数有很大的关系。
- DBSCAN用固定参数识别聚类,但当聚类的稀疏程度不同时,相同的判定标准可能会破坏聚类的自然结构,即较稀的聚类会被划分为多个类或密度较大且离得较近的类会被合并成一个聚类
> library(fpc)
> iris2 <- iris[-5] # 与之前相同,从数据样本中剔除species属性
> ds <- dbscan(iris2, eps=0.42, MinPts=5)
> # compare clusters with original class labels
> table(ds$cluster, iris$Species)
setosa versicolor virginica
0 2 10 17
1 48 0 0
2 0 37 0
3 0 3 33
上面的数据表中1到3为识别出来的3个聚类簇,0表示噪声数据或利群点,即不属于任何簇的对象。
plot(ds, iris2)

查看部分特性分布图 plot(ds,iris2[c(1,4)])

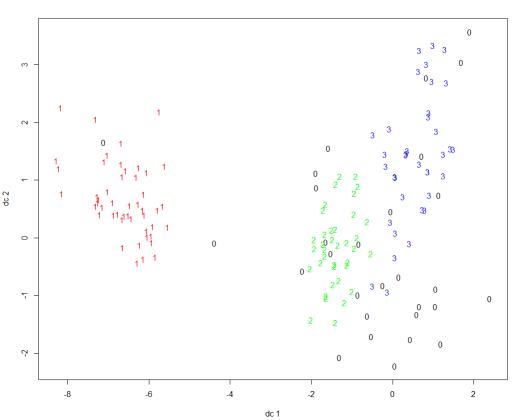
fpc包还提供了另一个展示聚类分析的函数plotcluster(),值得一提的是,数据将被投影到不同的簇中
plotcluster(iris2, ds$cluster)
参考资料:
以上是关于ML: 聚类算法R包 - 密度聚类的主要内容,如果未能解决你的问题,请参考以下文章