基础知识八集成学习
Posted AYE89
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基础知识八集成学习相关的知识,希望对你有一定的参考价值。
难点:如何产生“好而不同”的个体学习器;“好而不同”:“准确性”和“多样性”
一、个体与集成
构建并结合多个学习器来完成学习任务
集成:结果通过投票法voting产生,“少数服从多数”
获得整体性能提升要求个体学习器:好而不同
1)个体学习器有一定的“准确性”
2)学习器间具有差异
集成学习的错误率:
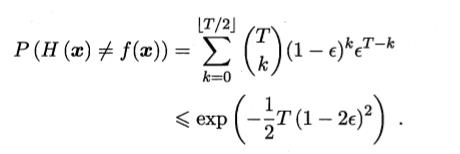
假设基学习器的误差相互独立,随着集成中个体分类器数目T的增大,集成的错误率将指数级下降,最终趋向于零
事实上,个体学习器是为了解决同一个问题训练出来的,它们不可能相互独立
集成学习方法大致分两大类:
个体学习器之间存在强依赖关系:代表是Boosting
个体之间不存在强依赖关系:代表是Bagging和“随机森林”
二、Boosting
根据前一个基学习器的表现对训练样本分布进行调整,用调整后的样本分布来训练下一个基学习器;重复进行直至达到事先指定的值T
最著名的算法是AdaBoost:推导基于“加性模型”,即基学习器的线性组合

从偏差-方差分解的角度看,Boosting主要关注降低偏差,因此能基于泛化能力相当弱的学习器构建出很强的集成。
三、Bagging
bootstrap sampling产生T个训练样本的采样集,基于每个采样集训练出一个基学习器,集成采用平均/投票
随机森林是Bagging的一个扩展变体
在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入随机属性选择
三、结合策略
数值型输出:
1. 简单平均法
2. 加权平均法
标记分类:
1.绝对多数投票法
2.相对多数投票法
3. 加权投票法
学习法
四、多样性
1. 多样性度量
通常,考虑个体分类器的两两相似/不相似性:
不合度量
相关系数
Q-统计量
K-统计量
2. 多样性增强
数据样本扰动
输入属性扰动
输出表示扰动
算法参数扰动
以上是关于基础知识八集成学习的主要内容,如果未能解决你的问题,请参考以下文章