2017.8.10 习题随笔
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2017.8.10 习题随笔相关的知识,希望对你有一定的参考价值。
 1.between使用的小细节
1.between使用的小细节
在使用between 函数限定范围的时候,要注意小的在前大的在后

这样使用between会导致结果为“0”
代码运行结果如下

将代码修改后
代码课正确运行
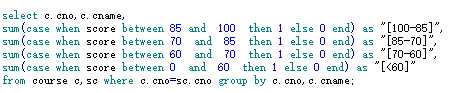
2.distinct使用(引)
当 distinct 作用在多个字段的时候,她只会将所有字段值都相同的记录“去重”掉
完全相同的记录,验证一下即可。添加一条记录后的表如下所示:
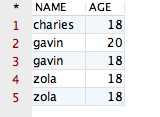
再运行如下的 SQL 语句,
|
1
|
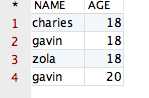
select distinct name, age from PPPRDER.CESHIDEMO |
得到的结果如下所示:
3.row_number() over(partiton by colunm1 order by colunm2)
将表中的记录按字段 COLUMN1进行分组,按字段 COLUMN2 进行排序,其中
PARTITION BY:表示分组ORDER BY:表示排序
接下来,咱们还用表“CESHIDEMO”中的数据进行测试。首先,给出没有使用 row_number() over() 函数时查询的结果,如下所示:
然后,运行如下 SQL 语句,
|
1
|
select PPPRDER.CESHIDEMO.*, row_number() over(partition by age order by name desc) from PPPRDER.CESHIDEMO |
得到的结果如下所示:
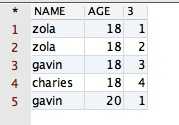
从上面的结果可以看出,其在原表的基础上,多了一列标有数字排序的列。那么反过来分析咱们运行的 SQL 语句,发现其确实按字段 AGE 的值进行分组了,也按字段 NAME 的值进行排序啦!因此,函数的功能得到了验证。
接下来,咱们就研究如何用 row_number() over() 函数实现“去重”的功能。通过观察上面的结果,咱们可以发现,如果以 NAME 分组,以 AGE 排序,然后再取每组的第一个记录或许就可以实现“去重”的功能啊!那么试试看,运行如下 SQL 语句,
|
1
2
3
4
5
6
7
|
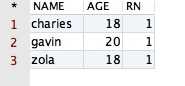
/** 其中 rn 表示最后添加的那一列*/select * from(select PPPRDER.CESHIDEMO.*, row_number() over(partition by name order by age desc) rn from PPPRDER.CESHIDEMO)where rn = 1 |
运行后,得到的结果如下所示:
以上是关于2017.8.10 习题随笔的主要内容,如果未能解决你的问题,请参考以下文章
codevs http://www.codevs.cn/problem/?problemset_id=1 循环递归stl复习题