Scrapy架构概述
Posted 若鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy架构概述相关的知识,希望对你有一定的参考价值。
Scrapy架构概述
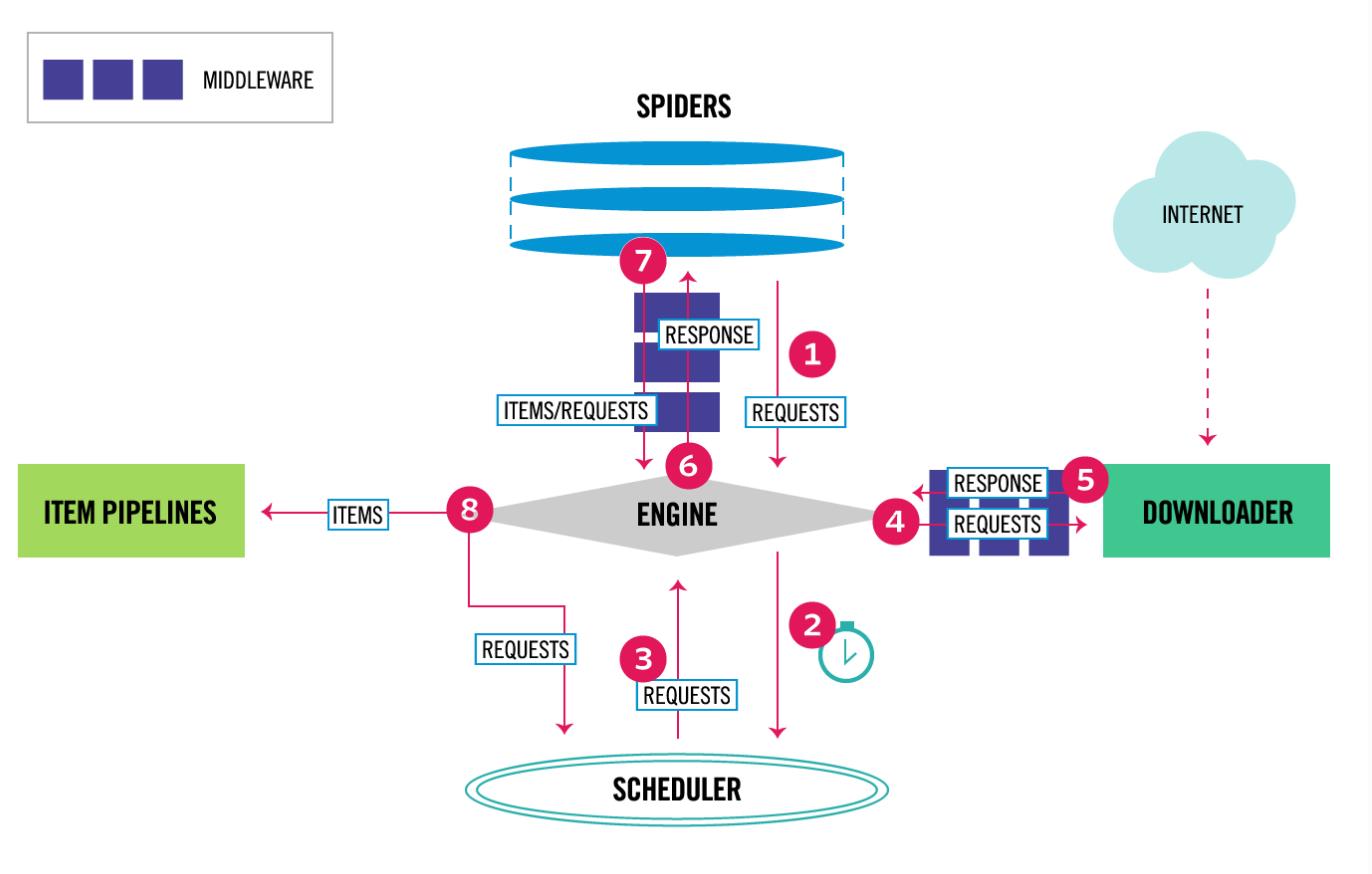
1, 从最初自己编写的spiders,获取到start_url,并且封装成Request对象。
2,通过engine(引擎)调度给SCHEDULER(Requests管理调度器)。
3,SCHEDULER管理ENGINE传递过来的所有Requests,通过优先级,传递给ENGINE。
4,ENGINE 将传递过来的Request对象传递给Downloader(下载器),但是在传递之间会通过MiddleWare(中间件)对Requests进行包装,添加头部,代理IP之类的。
5,Downloader(下载器)将包装好的Requests进行下载,并将下载后的Response对象传递给Engin。
6,Engin将Response对象传递给自己编码的Spider,但是中间仍有对于Response加工的中间件,在spider中通过自己编写的规则对内容进行提取。
7,提取完成后会产生两种对象,一个是自己想要的数据,存储在Item中;另一个是想要继续爬取的URL,包装成Request一并传递给Engine
8,Engine获取到 7 传递过来的Item,将其传递给ItemPipelines(Item管道,将Item中数据写入存储);获取到 7 传递来的Requests对象,跟之前一样,交给SCHEDULER进行管理调度
9,SCHEDULER中没有Requests对象需要下载时,爬虫关闭。
以上是关于Scrapy架构概述的主要内容,如果未能解决你的问题,请参考以下文章