R语言计算α多样性指数与画图
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言计算α多样性指数与画图相关的知识,希望对你有一定的参考价值。
参考技术A 操作之前安装好ggplot2、vegan、ggpubr包。如下:install.packages("ggplot2")
install.packages("ggpubr")
install.packages("vegan")
计算Shannon-香农指数和Simpson-辛普森指数的命令在vegan包中,计算各组显著性的命令在ggpubr包中;画图使用ggplot命令,在行使每个命令之前一定要加载相应的包,如下:
library(ggplot2)
library(ggpubr)
library(vegan)
拿到一个otu表格,要先计算香农指数和辛普森指数,操作如下:
otu=read.table('D:/r-working/feature-table.taxonomy.txt',row.names = 1,skip=1,header=T,comment.char ='',sep='\t')
#读取out表格
#'D:/feature table.taxonomy.txt'为文件路径,注意斜线方向
#row.names = 1指定第一列为行名
#skip=1跳过第一行不读
#header=T指定第一个有效行为列名
#sep='\t'表示指定制表符为分隔符
#comment.char=''表示设置注释符号为空字符‘’,这样#后面的内容就不会被省略
otu=otu[,-ncol(otu)]
#去除表格的最后一列,无用信息
otu=t(otu)
#表格转置,必须将样品名作为行名
shannon=diversity(otu,"shannon")
#计算香农指数,先加载vegan包
shannon
#查看香农指数
simpson=diversity(otu,"simpson")
#计算辛普森指数,先加载vegan包
simpson
#查看辛普森指数
alpha=data.frame(shannon,simpson,check.names=T)
#合并两个指数
write.table(alpha,"D:/r-working/alpha-summary.xls",sep='\t',quote=F)
#存储数据,注意路径使用反斜杠
将各样本进行分组,并进行画图,操作如下:
map<-read.table('D:/r-working/mapping_file.txt',row.names = 1,header=T,comment.char ='',sep='\t',check.names=F)
#读取分组表格
group<-map["Group1"]
#提取需要的分组,'Group1'是表中的分组列名,包括A,B,C三组
alpha<-alpha[match(rownames(group),rownames(alpha)),]
#重排alpha的行的顺序,使其与group的样本id(行名)一致
data<-data.frame(group,alpha,check.rows=T)
#合并两个表格.'<-'与'='同属赋值的含义.
p=ggplot(data=data,aes(x=Group1,y=shannon))+geom_boxplot(fill=rainbow(7)[2])
#data = data指定数据表格
#x=Group1指定作为x轴的数据列名
#y=shannon指定作为y轴的数据列名
#geom_boxplot()表示画箱线图
#fill=rainbow(7)[2]指定填充色
此处用到ggplot2包画箱线图,将画图函数赋值给p后,可以用‘+’不断进行图层叠加,给图片p增加新的特性
p
#查看p
mycompare=list(c('A','B'),c('A','C'),c('B','C'))
#指定多重比较的分组对
mycompare
p<-p+stat_compare_means(comparisons=mycompare,label = "p.signif",method = 'wilcox')
#添加显著性标记的第一种方法,在此之前先加载ggpubr包
p<-p+ylim(2,5.5)
#调整图像的外观
R语言基础介绍
① R语言学习书籍推荐

ggplot2开始,即如何画图开始,后讲理论和语法。也就是,先告诉你怎么用,然后告诉你为什么这样用,这也是我认为它最大的优点,推荐。
② R与RStudio的安装
③ R包
tidyverse。
install.packages("tidyverse")
library()加载包
library(tidyverse)
tidyverse 的核心包
ggplot2,
tibble,
tidyr,
readr,
purrr,
dplyr 已经加载完成,这些都是平常数据分析作图常用到的。(后续可以用
tidyverse_update()进行更新)
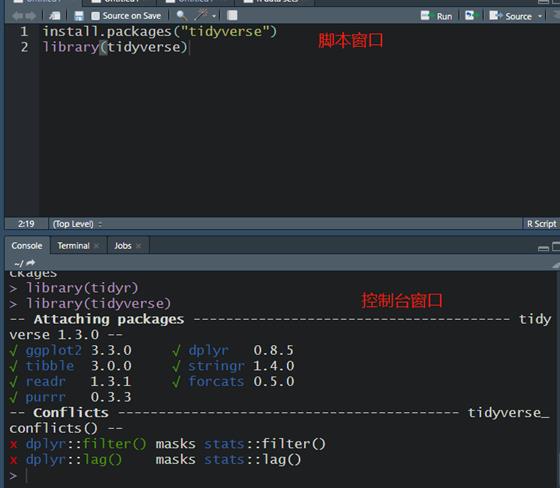
tidyverse中的库,使用
tidyverse_update()检查最方便。
④ R学习论坛
Google
stackoverflow(http://stackoverflow.com/)
RStudio blog(https://blog.rstudio.org/)
代码窗口输入
??。比如你不清楚tidyverse,可以输入??tidyverse如图2,在输出窗口中help当中可以看到它的解释。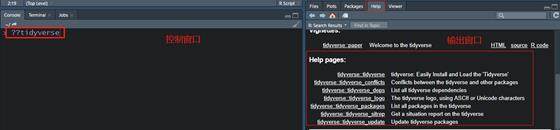
图2
⑤ R画图与数据可视化
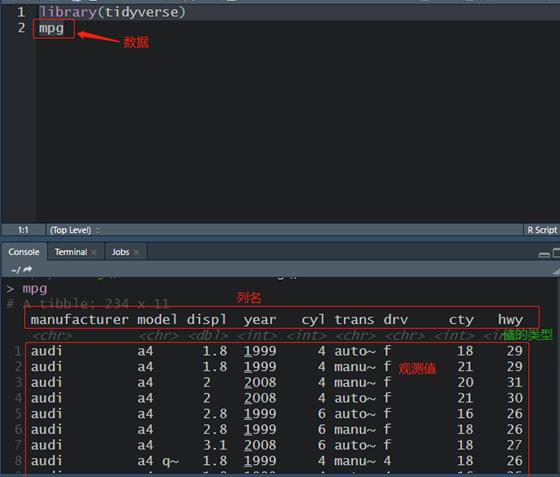
ggplot2包当中的
mpg数据来举例(
mpg数据是美国环境保护署收集的有关汽车类型,尾气排放效率等的数据)。如图3所示,列名为变量名,行中的数值为观测值,中间含
<>的为值的类型。(其中,displ表示汽车引擎大小,hwy表示汽车燃料效率)
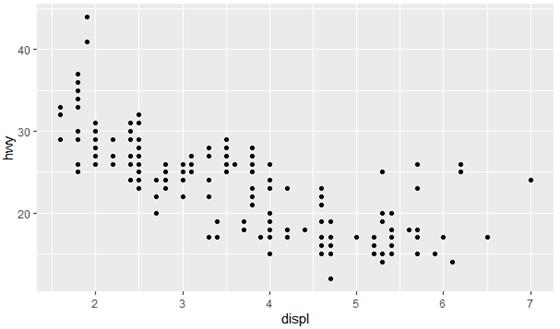
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy))
ggplot(data = mpg)
+ geom_point(mapping = aes(x = displ, y = hwy)) (×)
ggplot()函数中的参数表明在图中使用的数据集,
ggplot(data = mpg)表示你使用的mpg数据集。
ggplot有很多
geom函数,其中
geom_point()表示在图层中加入一个点图层,即该函数可以创建一个散点图。
asx表示数据与图的映射,
aes(x = displ, y = hwy)表示
x轴与
y轴对应的变量。
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = class))
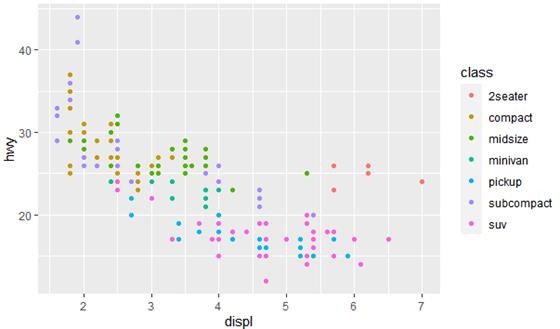
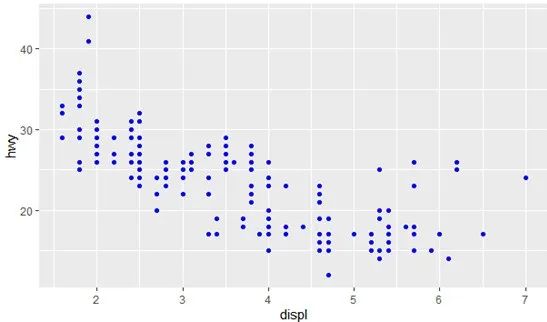
color = “blue”,且它应当在aes()的外面,代码如下
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy), color = "blue")
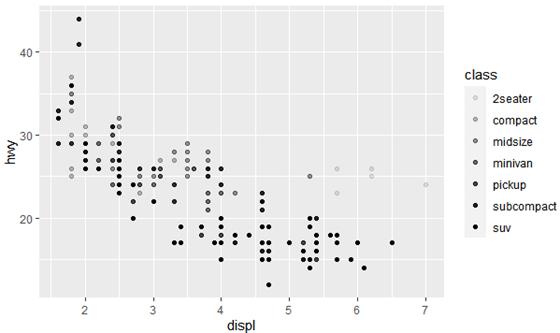
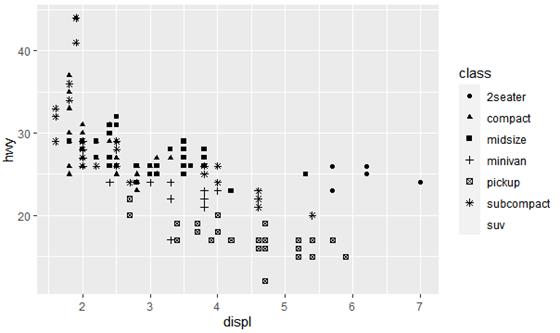
当然,划分车的类型时,不一定使用颜色区分,也可以使用透明度(图7a)、形状(图7b)来区分。
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, alpha = class
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, shape = class))
geom_smooth()
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy))
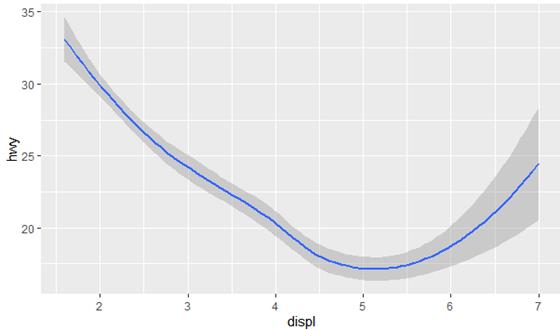
se = FALSE
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy),se=FALSE)
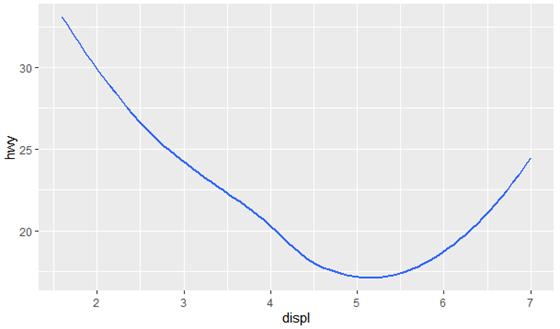
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
geom_smooth(mapping = aes(x = displ, y = hwy),se = FALSE)
以上是关于R语言计算α多样性指数与画图的主要内容,如果未能解决你的问题,请参考以下文章