Unicode 与 Unicode Transformation Format(UTF-8 / UTF-16 / UTF-32)
Posted 熊猫猛男
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Unicode 与 Unicode Transformation Format(UTF-8 / UTF-16 / UTF-32)相关的知识,希望对你有一定的参考价值。
- ASCII(American Standard Code for Information Interchange):早期它使用7 bits来表示一个字符,总共表示27 = 128个字符;后来扩展到8 bits,即用一个字节来表示一个字符,总共表示28 = 256个字符,这种ASCII扩展字符集如IBM字符集和ISO Latin-1,首位为1(128~255)的编码区域表示扩展字符
- Unicode:由于ASCII字符集总数有限且只适用于欧洲语言国家,不同语言体系的国家要统一使用同一种字符集,就需要一种更大的字符集。Unicode早期采用2个字节编码,总共可表示216 = 65536个字符,它通过增加一个高字节对ISO Latin-1字符集进行扩展,当这些高字节位为0时,低字节就是ISO Latin-1字符;然而,可以用ASCII表示的字符使用Unicode并不高效,因为Unicode比ASCII占用大一倍的空间,对ASCII来说高字节的0对他毫无用处。为了解决这个问题,就出现了一些中间格式的字符集,他们被称为通用转换格式,即UTF(Unicode Transformation Format),如UTF-8、UTF-16、UTF-32。Universal Character Set(UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集,UCS-2用两个字节编码,UCS-4用4个字节编码。从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码,以保持两者兼容。Unicode计划使用17个平面(Plane,包含216 = 65536个码位。Plane 0被称为Basic Multilingual Plane),一共有17×65536=1114112个码位(0~1114111)。ISO承诺ISO 10646将不会替超出U+10FFFF(1114111)的UCS-4编码赋值,以使得两者保持一致
- BOM(Byte Order Mark,字节顺序标记):特殊字符U+FEFF叫做 "Zero Width No-Break Space" ,中文译作“零宽无间断间隔”的字符,实际不会出现在正常字节流中。但在传输字节流前,先传输字符 "Zero Width No-Break Space",如果收到FFFE,就表明这个字节流是 Little- Endian (小端序、小字节序、低字节序、小尾序,即低位字节排放在内存的低地址端,高位字节排放在内存的高地址端)的;如果收到 FEFF,就表明这个字节流是 Big-Endian (大端序,字节顺序与 Little- Endian 刚好相反)的。因此字符 "Zero Width No-Break Space" 又被称作 BOM,它将出现在文本文件头部,表明文件的编码方式。UTF-8 虽是字节顺序无关的,但仍然可以用 BOM (EF BB BF)来表明其编码方式。下图展示了编码方式与BOM的对应关系:
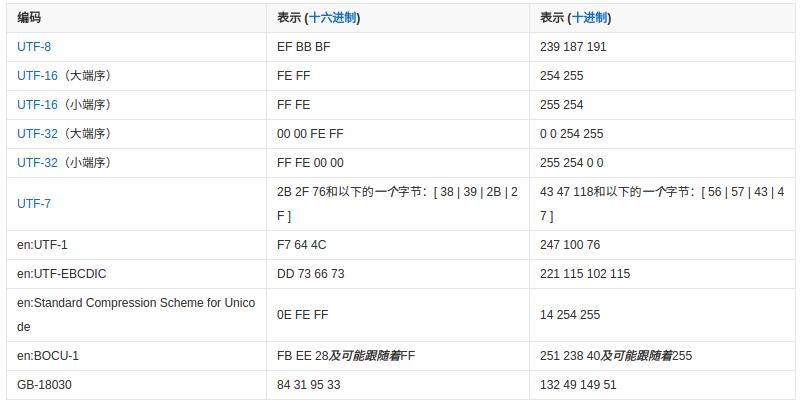
php并不会忽略UTF-8文件的BOM,所以在读取、包含或者引用这些文件时,会把BOM作为该文件开头正文的一部分。因此,PHP文件采用UTF-8编码时可保存无BOM格式。
如果U+FEFF出现在数据流中,该怎么办呢?下面这段来自Wikipedia,关于Word Joiner(WJ, U+2060):The word joiner replaces the zero-width no-break space (ZWNBSP), a deprecated use of the Unicode character at code point U+FEFF. Character U+FEFF is intended for use as a Byte Order Mark at the start of a file. However, if encountered elsewhere it should, according to Unicode, be treated as a "zero-width non-breaking space." The deliberate use of U+FEFF for this purpose is deprecated as of Unicode 3.2, with the word joiner strongly preferred. - UTF-8(万国码):它是可变长编码,即用1~4个字节来编码Unicode字符集。其与Unicode的转换关系如下:
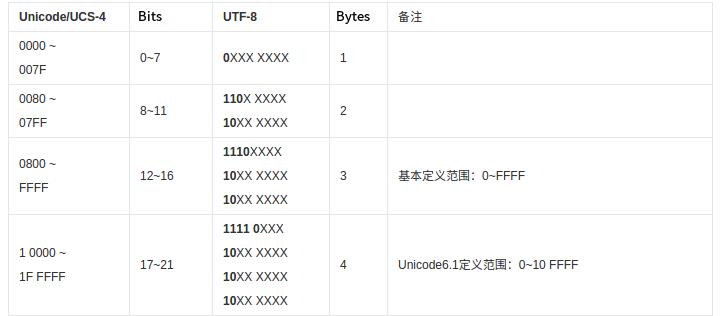
另外,以下部分非Unicode编码范围,属于UCS-4 编码早期的规范: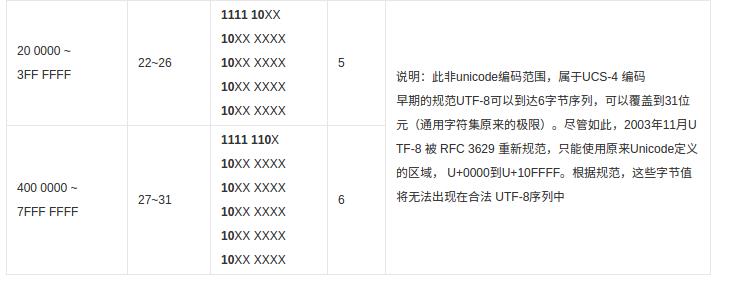
UTF-8用1个字节(U+0000~U+007F)来编码所有ASCII字符,并且与ASCII字符表示是一样的,故其与ASCII兼容,而那些ISO Latin-1扩展ASCII字符集的字符(128~255)是Unicode的子集,但不是UTF-8的子集;其他的字符UTF-8编码将需要2~4个字节,首字节连续的1的个数表示字符编码所需的字节数。“编”的Unicode编码是U+7F16,因此UTF-8需要3个字节来表示,形如1110xxxx 10xxxxxx 10xxxxxx这种格式。
由于UTF-8采用的是变长字符编码,与UTF-16和UTF-32相比,无论是计算字符数,还是执行索引操作效率都不高,因此UTF-8适合在传输数据中使用,可在数据接收完毕后将其转换为UTF-16或UTF-32进行处理,最后再转换回UTF-8(但这转换本身也会有性能损耗);但UTF-8空间足够大,无字节序问题,且容错性高,局部的字节错误(丢失、增加、改变)不会导致连锁性的错误,因为 UTF-8 的字符边界很容易检测出来。另外,utf8mb4是utf8的一个超集,支持最多4个字节来表示一个字符,如emoji表情字符就占用4个字节。 - UTF-16:以2个字节16bits为编码基本单位。假设U代表字符的Unicode编码,如果U < 0x10000且U∉[0xD800,0xDFFF],U的UTF-16编码就是U对应的16位无符号整数(0x00000~0xFFFF,除去0xD800-0xDFFF作为BMP的代理区部分);如果U ≥ 0x10000,则使U\' = U - 0x10000(最大为0x10FFFF - 0x10000 = 0xFFFFF),然后将U\'写成二进制形式:yyyy yyyy yyxx xxxx xxxx,U的UTF-16编码二进制表示就是:110110yyyyyyyyyy(0xD800~0xDBFF) 110111xxxxxxxxxx(0xDC00~0xDFFF)。由此可见,Unicode字符的UTF-16表示要么是2个字节长度,要么是4个字节长度,为将二者区分开来、防止冲突,设计者将0xD800-0xDFFF保留下来,称代理区(Surrogate):
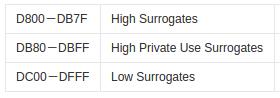
High Surrogates就是指这个范围的码位是Unicode字符4字节UTF-16编码的头两个字节;Low Surrogates就是指这个范围的码位是Unicode字符4字节UTF-16编码的后两个字节;High Private Use Surrogates是指这个范围的码位是Unicode字符4字节UTF-16编码的头两个字节,但该Unicode字符属于平面15和平面16这两个专用区 - UTF-32:用4个字节32bits来编码一个Unicode字符,Unicode的UTF-32编码就是其对应的32位无符号整数
- 更多信息参考链接:http://www.unicode.org/faq/utf_bom.html
以上是关于Unicode 与 Unicode Transformation Format(UTF-8 / UTF-16 / UTF-32)的主要内容,如果未能解决你的问题,请参考以下文章