为啥说JavaScript中的DOM操作很慢
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为啥说JavaScript中的DOM操作很慢相关的知识,希望对你有一定的参考价值。
在浏览器中,DOM和JS的实现,用的并不是同一个“东西”。比如说,我们最熟悉的chrome,JS引擎是V8,而DOM和渲染,靠的是WebCore库。也就是说,DOM和JS是两个独立的个体。
--《高性能JavaScript》
1、添加页面元素,innerhtml vs DOM方法。
document.getElementById('test').innerHTML='<div>test</div>';var t=document.createElement('div');
t.appendChild(document.createTextNode('test'));
document.getElementById('test').appendChild(t);
以上分别使用两种方法,向id='test'的元素中添加一个div。之前,大家可能一直被灌输的思想是innerHTML更快一些,真的是这样么?
还真是,至少在IE中是这样,但在基于webkit的新版浏览器中,使用DOM方法会稍快一些。所以,到底使用哪一种方法,还是应该有点争议的。我个人是喜欢innerHTML,因为用起来更简单。
此外,当需要添加大量相同的元素时,cloneNode比直接创建元素,稍微快一点。
2、访问元素的正确方法。
2.1、遍历集合vs遍历数组
当我们使用document.getElementsByName、document.getElementsByTagName、document.getElementsByClassName、docuemnt.images等方式来获取DOM元素时,我们得到的是一个HTML集合,这个集合始终与底层文档保持连接,每次去获取集合的信息时,都会重复执行一次查询。
for(var i=0;i<divs.length;i++)
document.body.append(document.createElement('div'))
如果不去运行,我们可能以为上面的代码会新添加几个div元素在页面中,但实际上,因为每次添加完一个div后,divs.length都会被更新(加一),所以,这个循环永远不会停止。解决办法非常简单
for(var i=0,len=divs.length;i<len;i++)
document.body.append(document.createElement('div'))
另外,HTML集合并不是一个数组,如果我们需要对这个集合进行遍历,可以先把它拷贝进一个数组,这样再遍历的时候,效率更高。
for(var i=0,a=[],len=coll.length;i<len;i++)
a[i]=coll[i]
return a;
2.2、访问元素属性
当遍历一个集合时,length属性应被缓存在循环外部,能够避免2.1中的逻辑错误;集合存储在局部变量中,也能够提高效率。此外,当对同一个DOM元素的属性进行访问时,把这个DOM缓存成一个局部变量,是更好的选择。
//最差的方式
function fo1()
var name='';
for(var i=0;i<document.getElementsByTagName('div');i++)
name=document.getElementsByTagName('div').nodeName;
name=document.getElementsByTagName('div').nodeType;
return name;
//好一点的方式
function fo2()
var name='';
var coll=document.getElementsByTagName('div');
for(var i=0,len=coll.length;i<len;i++)
name=coll[i].nodeName;
name=coll[i].nodeType;
return name;
//更好的方式
function fo3()
var name='';
var coll=document.getElementsByTagName('div');
var ele=null;
for(var i=0,len=coll.length;i<len;i++)
el=coll[i];
name=el.nodeName;
name=el.nodeType;
3、选择器
前面已经提到,document.getElementsByName、document.getElementsByTagName、document.getElementsByClassName、docuemnt.images等方式,获取到的是HTML集合,效率低下;而querySelector以及querySelectorAll与之相比,得到的是一个NodeList,它是一个类数组对象,不会带来HTML集合的问题。而且,这个API在获取元素时,更加方便。唯一的问题,是要考虑目标浏览器是否提供支持。
4、重绘和重排
4.1、何时重绘、重排?
重绘并不一定导致重排,比如修改某个元素的颜色,只会导致重绘;而重排之后,浏览器需要重新绘制受重排影响的部分。导致重排的原因有:
添加或删除DOM元素
元素位置、大小、内容改变
浏览器窗口大小改变
滚动条出现
因为重排和重绘的操作十分昂贵,浏览器会通过队列化修改并批量执行的方式,来进行优化(我的理解是,浏览器通过队列化和批量执行的方式,减少了重绘的次数)。比如:
//这段代码,并不会去重绘三次var bodyStyle=document.body.style;
bodyStyle.color='red';
bodyStyle.color='black';
bodyStyle.color='green';
获取布局的操作,会导致队列刷新,浏览器的优化效果也就没有了。要避免在布局信息改变时,获取下列属性:
offsetTop,offsetLeft,offsetWidth,offsetHeight;
scrollTop,scrollLeft,scrollWidth,scrollHeight;
clientTop,clientLeft,clientWidth,clientHeight;
getComputedStyle()/currentStyle
4.2、最小化重排、重绘的建议
建议:不要再修改布局信息的时候,去查询布局信息
var computed;var tmp='';
var bodyStyle=document.body.style;
if(document.body.currentStyle)
computed=document.body.currentStyle
else
computed=document.defaultView.getComputedStyle(document.body,'')
//bad
bodyStyle.color='red';
tmp=computed.backgroundColor;
bodyStyle.color='green';
tmp=computed.backgroundImage;
//good
bodyStyle.color='red';
bodyStyle.color='green';
tmp=computed.backgroundColor;
tmp=computed.backgroundImage;
修改一个元素的多个style时,一次性修改,而不是多次(虽然多次修改,经过现代浏览器的优化,也只会导致一次重排,但在老旧的浏览器中,仍然会导致多次)。建议:能用css的class解决的,就尽量不用内联样式。
:hover会降低响应速度,在处理很大的列表时,避免使用。
5、事件委托
每绑定一个事件处理器,都是有代价的。如果有大量的元素需要绑定时间,尝试使用事件委托。分三步
判断事件来源
根据不同来源,进行不同操作
取消冒泡,阻止默认行为(可选)
document.querySelector('#nav').onclick=function (e)if (e.target.nodeName=='A')
foo();
else
foo2()
总结:
减少DOM访问次数
多次访问同一DOM,应该用局部变量缓存该DOM
尽可能使用querySelector,而不是使用获取HTML集合的API
注意重排和重绘
使用事件委托,减少绑定事件的数量
更多内容,可以阅读《高性能JavaScript》
以上内容来自: cnblogs,www.cnblogs.com/yepbug/p/5427213.html
参考技术A DOM对象本身也是一个js对象,所以严格来说,并不是操作这个对象慢,而是说操作了这个对象后,会触发一些浏览器行为,比如布局(layout)和绘制(paint)。为什么说DOM操作很慢
一直都听说DOM很慢,要尽量少的去操作DOM,于是就想进一步去探究下为什么大家都会这样说,在网上学习了一些资料,这边整理出来。
首先,DOM对象本身也是一个js对象,所以严格来说,并不是操作这个对象慢,而是说操作了这个对象后,会触发一些浏览器行为,比如布局(layout)和绘制(paint)。下面主要先介绍下这些浏览器行为,阐述一个页面是怎么最终被呈现出来的,另外还会从代码的角度,来说明一些不好的实践以及一些优化方案。
浏览器是如何呈现一张页面的
一个浏览器有许多模块,其中负责呈现页面的是渲染引擎模块,比较熟悉的有WebKit和Gecko等,这里也只会涉及这个模块的内容。
先用文字大致阐述下这个过程:
- 解析HTML,并生成一棵DOM tree
- 解析各种样式并结合DOM tree生成一棵Render tree
- 对Render tree的各个节点计算布局信息,比如box的位置与尺寸
- 根据Render tree并利用浏览器的UI层进行绘制
其中DOM tree和Render tree上的节点并非一一对应,比如一个"display:none"的节点就只会存在于DOM tree上,而不会出现在Render tree上,因为这个节点不需要被绘制。
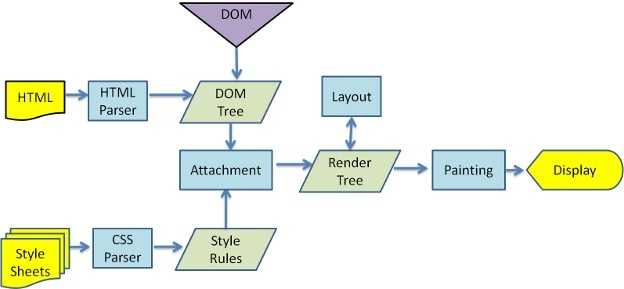
上图是Webkit的基本流程,在术语上和Gecko可能会有不同,这里贴上Gecko的流程图,不过文章下面的内容都会统一使用Webkit的术语。
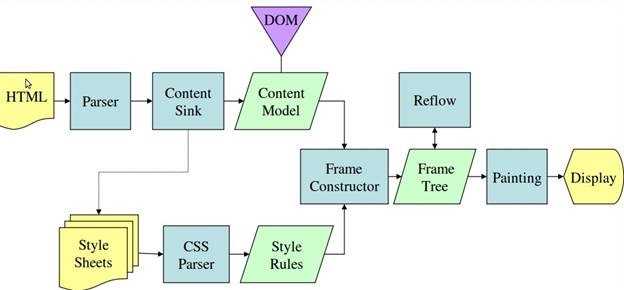
影响页面呈现的因素有许多,比如link的位置会影响首屏呈现等。但这里主要集中讨论与layout相关的内容。
paint是一个耗时的过程,然而layout是一个更耗时的过程,我们无法确定layout一定是自上而下或是自下而上进行的,甚至一次layout会牵涉到整个文档布局的重新计算。
但是layout是肯定无法避免的,所以我们主要是要最小化layout的次数。
什么情况下浏览器会进行layout
在考虑如何最小化layout次数之前,要先了解什么时候浏览器会进行layout。
layout(reflow)一般被称为布局,这个操作是用来计算文档中元素的位置和大小,是渲染前重要的一步。在HTML第一次被加载的时候,会有一次layout之外,js脚本的执行和样式的改变同样会导致浏览器执行layout,这也是本文的主要要讨论的内容。
一般情况下,浏览器的layout是lazy的,也就是说:在js脚本执行时,是不会去更新DOM的,任何对DOM的修改都会被暂存在一个队列中,在当前js的执行上下文完成执行后,会根据这个队列中的修改,进行一次layout。
然而有时希望在js代码中立刻获取最新的DOM节点信息,浏览器就不得不提前执行layout,这是导致DOM性能问题的主因。
如下的操作会打破常规,并触发浏览器执行layout:
- 通过js获取需要计算的DOM属性
- 添加或删除DOM元素
- resize浏览器窗口大小
- 改变字体
- css伪类的激活,比如:hover
- 通过js修改DOM元素样式且该样式涉及到尺寸的改变
我们来通过一个例子直观的感受下:
1 // Read
2 var h1 = element1.clientHeight;
3
4 // Write (invalidates layout)
5 element1.style.height = (h1 * 2) + ‘px‘;
6
7 // Read (triggers layout)
8 var h2 = element2.clientHeight;
9
10 // Write (invalidates layout)
11 element2.style.height = (h2 * 2) + ‘px‘;
12
13 // Read (triggers layout)
14 var h3 = element3.clientHeight;
15
16 // Write (invalidates layout)
17 element3.style.height = (h3 * 2) + ‘px‘;
clientHeight,这个属性是需要计算得到的,于是就会触发浏览器的一次layout。我们来利用chrome(v47.0)的开发者工具看下(截图中的timeline record已经经过筛选,仅显示layout):
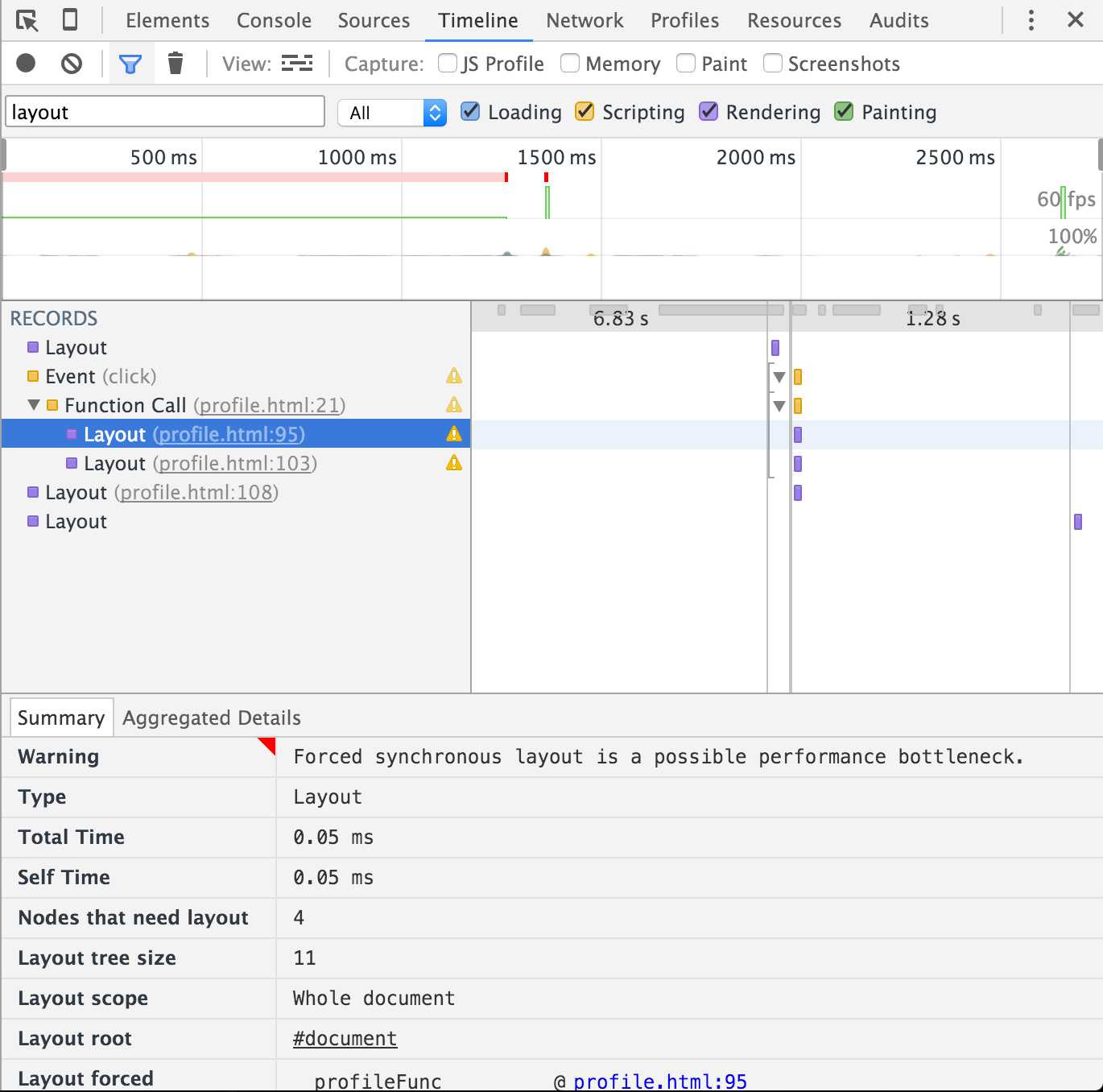
上面的例子中,代码首先修改了一个元素的样式,接下来读取另一个元素的clientHeight属性,由于之前的修改导致当前DOM被标记为脏,为了保证能准确的获取这个属性,浏览器会进行一次layout(我们发现chrome的开发者工具良心的提示了我们这个性能问题)。
优化这段代码很简单,预先读取所需要的属性,在一起修改即可。
1 // Read
2 var h1 = element1.clientHeight;
3 var h2 = element2.clientHeight;
4 var h3 = element3.clientHeight;
5
6 // Write (invalidates layout)
7 element1.style.height = (h1 * 2) + ‘px‘;
8 element2.style.height = (h2 * 2) + ‘px‘;
9 element3.style.height = (h3 * 2) + ‘px‘;
看下这次的情况:
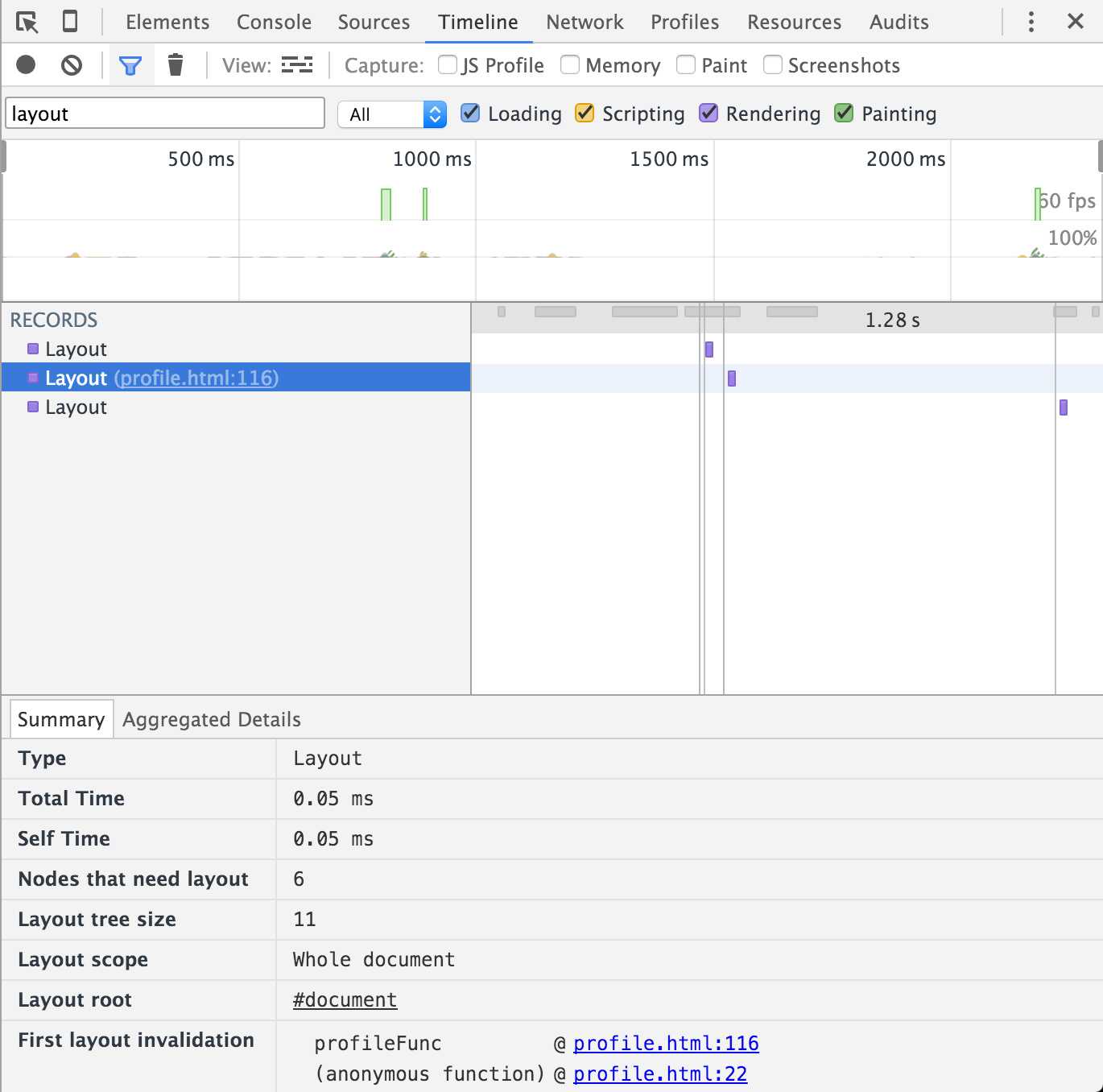
下面再介绍一些其他的优化方案。
最小化layout的方案
上面提到的一个批量读写是一个,主要是因为获取一个需要计算的属性值导致的,那么哪些值是需要计算的呢?
这个链接里有介绍大部分需要计算的属性:http://gent.ilcore.com/2011/03/how-not-to-trigger-layout-in-webkit.html
再来看看别的情况:
面对一系列DOM操作
针对一系列DOM操作(DOM元素的增删改),可以有如下方案:
- documentFragment
- display: none
- cloneNode
比如(仅以documentFragment为例):
var fragment = document.createDocumentFragment();
for (var i=0; i < items.length; i++){
var item = document.createElement("li");
item.appendChild(document.createTextNode("Option " + i);
fragment.appendChild(item);
}
list.appendChild(fragment);
这类优化方案的核心思想都是相同的,就是先对一个不在Render tree上的节点进行一系列操作,再把这个节点添加回Render tree,这样无论多么复杂的DOM操作,最终都只会触发一次layout。
面对样式的修改
针对样式的改变,我们首先需要知道并不是所有样式的修改都会触发layout,因为我们知道layout的工作是计算RenderObject的尺寸和大小信息,那么我如果只是改变一个颜色,是不会触发layout的。
这里有一个网站CSS triggers,详细列出了各个CSS属性对浏览器执行layout和paint的影响。
像下面这种情况,和上面讲优化的部分是一样的,注意下读写即可。
elem.style.height = "100px"; // mark invalidated
elem.style.width = "100px";
elem.style.marginRight = "10px";
elem.clientHeight // force layout here
但是要提一下动画,这边讲的是js动画,比如:
function animate (from, to) {
if (from === to) return
requestAnimationFrame(function () {
from += 5
element1.style.height = from + "px"
animate(from, to)
})
}
animate(100, 500)
动画的每一帧都会导致layout,这是无法避免的,但是为了减少动画带来的layout的性能损失,可以将动画元素绝对定位,这样动画元素脱离文本流,layout的计算量会减少很多。
使用requestAnimationFrame
任何可能导致重绘的操作都应该放入requestAnimationFrame
在现实项目中,代码按模块划分,很难像上例那样组织批量读写。那么这时可以把写操作放在requestAnimationFrame的callback中,统一让写操作在下一次paint之前执行。
// Read
var h1 = element1.clientHeight;
// Write
requestAnimationFrame(function() {
element1.style.height = (h1 * 2) + ‘px‘;
});
// Read
var h2 = element2.clientHeight;
// Write
requestAnimationFrame(function() {
element2.style.height = (h2 * 2) + ‘px‘;
});
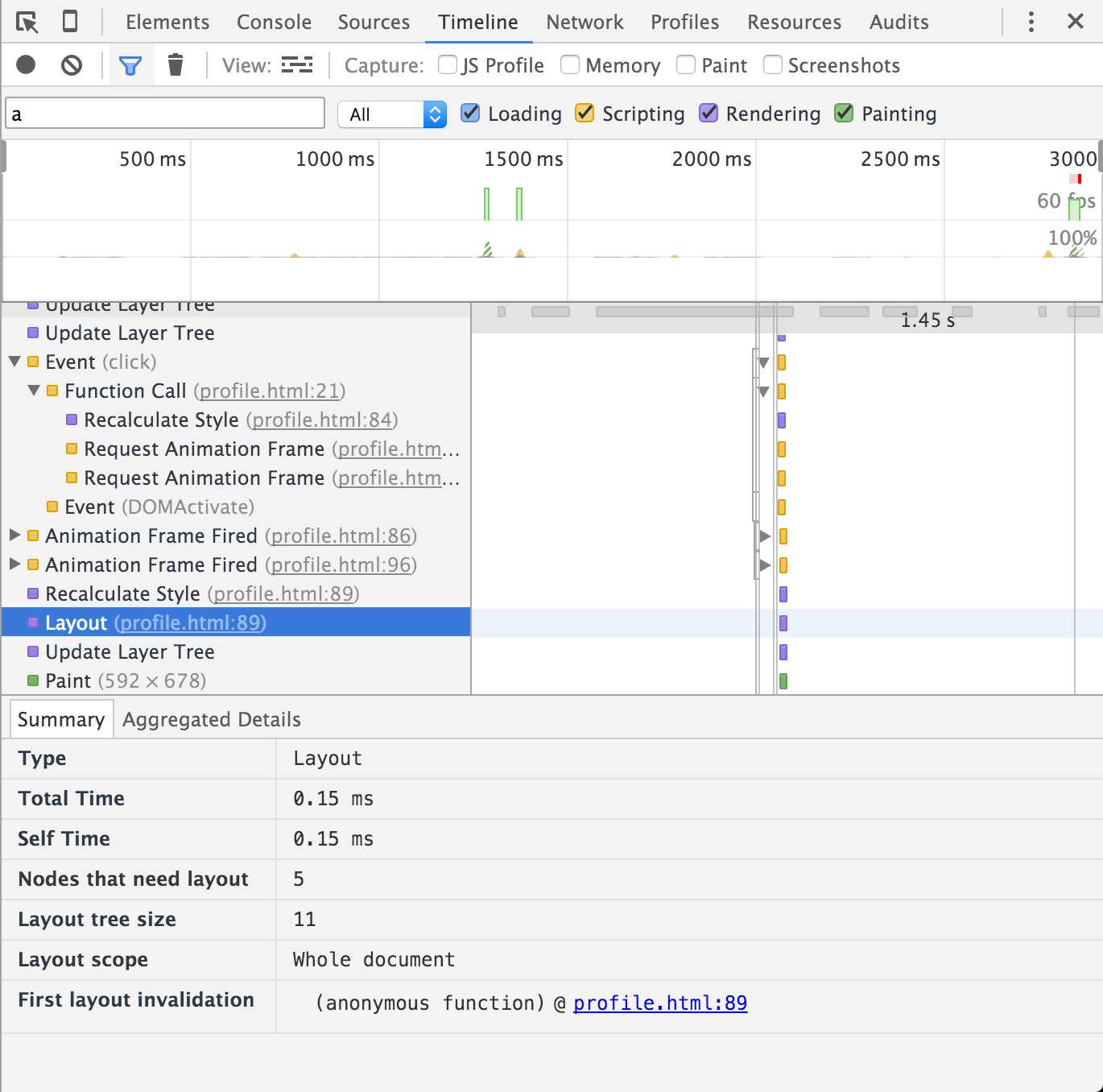
可以很清楚的观察到Animation Frame触发的时机,MDN上说是在paint之前触发,不过我估计是在js脚本交出控制权给浏览器进行DOM的invalidated check之前执行。
其他注意点
除了由于触发了layout而导致性能问题外,这边再列出一些其他细节:
缓存选择器的结果,减少DOM查询。这里要特别提下HTMLCollection。HTMLCollection是通过document.getElementByTagName得到的对象类型,和数组类型很类似但是每次获取这个对象的一个属性,都相当于进行一次DOM查询:
var divs = document.getElementsByTagName("div");
for (var i = 0; i < divs.length; i++){ //infinite loop
document.body.appendChild(document.createElement("div"));
}
比如上面的这段代码会导致无限循环,所以处理HTMLCollection对象的时候要做些缓存。
另外,减少DOM元素的嵌套深度并优化css,去除无用的样式对减少layout的计算量有一定帮助。
在DOM查询时,querySelector和querySelectorAll应该是最后的选择,它们功能最强大,但执行效率很差,如果可以的话,尽量用其他方法替代。
下面两个jsperf的链接,可以对比下性能。
1)https://jsperf.com/getelementsbyclassname-vs-queryselectorall/162
2)http://jsperf.com/getelementbyid-vs-queryselector/218
自己对View层的想法
上面的内容理论方面的东西偏多,从实践的角度来看,上面讨论的内容,正好是View层需要处理的事情。已经有一个库FastDOM来做这个事情,不过它的代码是这样的:
fastdom.read(function() {
console.log(‘read‘);
});
fastdom.write(function() {
console.log(‘write‘);
});
问题很明显,会导致callback hell,并且也可以预见到像FastDOM这样的imperative的代码缺乏扩展性,关键在于用了requestAnimationFrame后就变成了异步编程的问题了。要让读写状态同步,那必然需要在DOM的基础上写个Wrapper来内部控制异步读写,不过都到了这份上,感觉可以考虑直接上React了......
总之,尽量注意避免上面说到的问题,但如果用库,比如jQuery的话,layout的问题出在库本身的抽象上。像React引入自己的组件模型,用过virtual DOM来减少DOM操作,并可以在每次state改变时仅有一次layout,我不知道内部有没有用requestAnimationFrame之类的,感觉要做好一个View层就挺有难度的,之后准备学学React的代码。希望自己一两年后会过来再看这个问题的时候,可以有些新的见解。
以上是关于为啥说JavaScript中的DOM操作很慢的主要内容,如果未能解决你的问题,请参考以下文章