实际梯度下降中的两个重要调节方面
Posted 晓语听风
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实际梯度下降中的两个重要调节方面相关的知识,希望对你有一定的参考价值。
Gradient Descent in Practice I - Feature Scaling(特征尺度)
调整处理X的范围,以提高梯度下降效果和减小迭代次数,加快了下降速度。
Note: [6:20 - The average size of a house is 1000 but 100 is accidentally written instead]
We can speed up gradient descent by having each of our input values in roughly the same range. This is because θ will descend quickly on small ranges and slowly on large ranges, and so will oscillate inefficiently down to the optimum when the variables are very uneven.
The way to prevent this is to modify the ranges of our input variables so that they are all roughly the same. Ideally:

These aren\'t exact requirements; we are only trying to speed things up. The goal is to get all input variables into roughly one of these ranges, give or take a few.
Two techniques to help with this are feature scaling and mean normalization. Feature scaling involves dividing the input values by the range (i.e. the maximum value minus the minimum value) of the input variable, resulting in a new range of just 1. Mean normalization involves subtracting the average value for an input variable from the values for that input variable resulting in a new average value for the input variable of just zero. To implement both of these techniques, adjust your input values as shown in this formula:
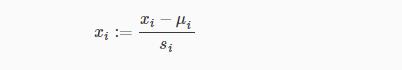
输入值减去输入值平均值除以输入值的范围
Where μi is the average of all the values for feature (i) and si is the range of values (max - min), or si is the standard deviation.
Note that dividing by the range, or dividing by the standard deviation, give different results. The quizzes in this course use range - the programming exercises use standard deviation.
For example, if xi represents housing prices with a range of 100 to 2000 and a mean value of 1000, then,
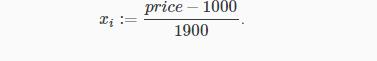
Gradient Descent in Practice II - Learning Rate
Note: [5:20 - the x -axis label in the right graph should be θ rather than No. of iterations ]
Debugging gradient descent. Make a plot with number of iterations on the x-axis. Now plot the cost function, J(θ) over the number of iterations of gradient descent. If J(θ) ever increases, then you probably need to decrease α.
Automatic convergence test. Declare convergence if J(θ) decreases by less than E in one iteration, where E is some small value such as 10−3. However in practice it\'s difficult to choose this threshold value.

It has been proven that if learning rate α is sufficiently small, then J(θ) will decrease on every iteration.

To summarize:
If α is too small: slow convergence.
If α is too large: may not decrease on every iteration and thus may not converge.
以上是关于实际梯度下降中的两个重要调节方面的主要内容,如果未能解决你的问题,请参考以下文章
2.9 logistic回归中的梯度下降法(非常重要,一定要重点理解)