百度风云榜相关
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百度风云榜相关相关的知识,希望对你有一定的参考价值。
时间:2017-8-5
目标:http://top.baidu.com/population?fr=topindex
配置:py3.4 + win7
目的:练习json数据抓取,及满足个人数据瘾
扩展:可选择性别、年龄分类(时间精力有限就没分类排序),可导入excel或是数据库,但我只是闲暇看看,就导入txt了。
完整代码:
1 ‘‘‘ 2 2017-8-5 0:41 by:羽凡 3 百度风云榜相关 4 py3.4 + win7 5 结果导入txt文件(方便查看,另可导入excel,数据库等(自行探索)) 6 练习json数据抓取 7 ‘‘‘ 8 9 10 11 12 import urllib.request 13 import urllib.parse 14 import json 15 di = {‘26‘:‘电影‘,‘4‘:‘电视剧‘, ‘19‘:‘综艺‘,‘23‘:‘动漫‘,‘491‘:‘欧美明星‘, 16 ‘255‘:‘体坛人物‘,‘261‘:‘财经人物‘,‘3‘:‘美女‘,‘22‘:‘帅哥‘,‘18‘:‘女演员‘, 17 ‘17‘:‘男演员‘,‘16‘:‘女歌手‘,‘15‘:‘男歌手‘,‘454‘:‘主持人‘,‘257‘:‘互联网人物‘, 18 ‘353‘:‘玄幻奇幻‘,‘355‘:‘都市言情‘,‘354‘:‘武侠仙侠‘,‘356‘:‘惊悚悬疑‘, 19 ‘359‘:‘历史军事‘,‘461‘:‘完结‘,‘460‘:‘免费‘,‘342‘:‘民生热点‘,‘344‘:‘娱乐热点‘, 20 ‘11‘:‘体育热点‘,‘12‘:‘高校‘,‘302‘:‘旅游城市‘,‘14‘:‘风景名胜‘,‘280‘:‘团购‘, 21 ‘270‘:‘奢侈品‘,‘291‘:‘美食‘,‘24‘:‘宠物‘,‘450‘:‘畅销书‘,‘2‘:‘热门搜索‘,‘396‘:‘世说新词‘} 22 print( 23 ‘‘‘---------------------------------------------------------------------- 24 26电影 4电视剧 19综艺 23动漫 491欧美明星 255体坛人物 261财经人物 25 3 美女 22帅哥 18女演员 17男演员 16女歌手 15男歌手 454主持人 257互联网人物 26 353玄幻奇幻 355都市言情 354武侠仙侠 356惊悚悬疑 359历史军事 461完结 460免费 27 342民生热点 344娱乐热点 11体育热点 28 12高校 302旅游城市 14风景名胜 280团购 270奢侈品 291美食 24宠物 450畅销书 29 2热门搜索 396世说新词 30 ----------------------------------------------------------------------‘‘‘) 31 choice = input(‘选择你感兴趣的话题编号:‘) 32 choice_int = int(choice) 33 url = ‘http://top.baidu.com/population/toplist‘ 34 header = {‘User-Agent‘:‘Mozilla/5.0‘} 35 data = {‘boardid‘:choice_int, 36 ‘divids[]‘:0} 37 data_encode = urllib.parse.urlencode(data).encode(‘utf-8‘) 38 req = urllib.request.Request(url,data=data_encode,headers=header) 39 res = urllib.request.urlopen(req) 40 content = res.read().decode(‘gb2312‘) 41 content = json.loads(content) 42 for n,i in enumerate(content[‘topWords‘][0]): 43 result = str(n+1) + ‘ ‘+i[‘keyword‘]+‘-----‘+‘关注度:‘+str(i[‘searches‘]) 44 print(result) 45 with open(di[choice]+‘.txt‘,‘a+‘) as f: 46 f.write(result+‘\\n‘) 47 print(‘Done‘)
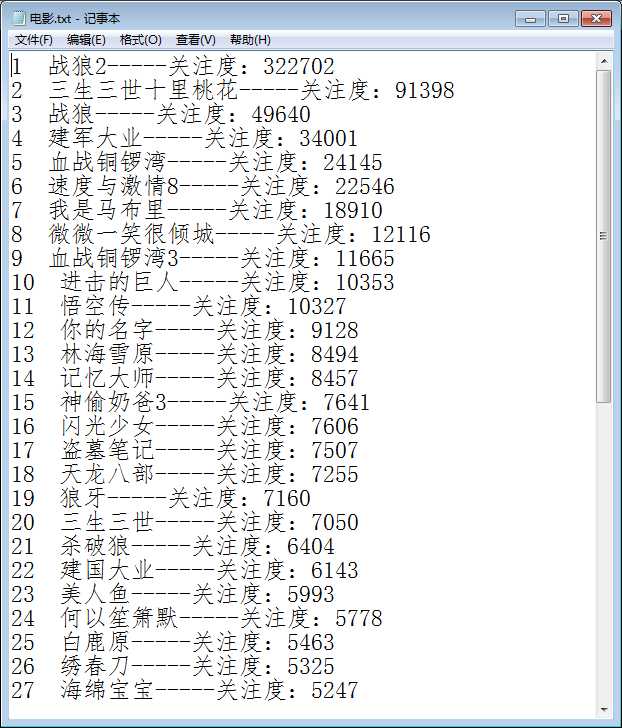
运行结果:
以上是关于百度风云榜相关的主要内容,如果未能解决你的问题,请参考以下文章